1、语法:
<窗口函数> OVER ([PARTITION BY <列清单>] ORDER BY <排序用列清单>)
a、PARTITION BY用来分组的,计算只是在各自组内进行
b、ORDER BY 用来决定窗口函数按照什么样的顺序进行计算的
c、当不指定partition by时,则数据便不会分组了,也就是只分一个组,所有数据在一起计算
d、能够作为窗口函数的聚合函数(SUM、AVG、COUNT、MAX、MIN)
e、RANK、DENSE_RANK、ROW_NUMBER 等专用窗口函数
f、原则上窗口函数只能在SELECT子句中使用,在SELECT 子句之外“使用窗口函数是没有意义的”
2、聚合函数做窗口函数:
列句:
select cid,score, sum(score) over(partition by cid order by score desc) r from sc
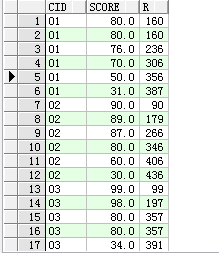
会按照cid分组,每组排序求和,80都是第一位的,80+80=160,结果就是160,到76的时候,便是160+76=236,下面也是如此,cid变成2的时候便是另一组,这时重新开始计算
同样的AVG、COUNT、MAX、MIN便会返回对应的值
3、移动窗口函数计算:
select cid,score, sum(score) over(partition by cid order by score desc ROWS 2 PRECEDING) r from sc、
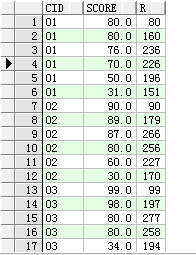
同样先分组,然后从第一个数据开始,先计算从当前数据开始前2个数据(ROWS 2 PRECEDING)的和。因为第一个80前面没有数据,则80+0=80,第二个80前面有个80,则80+80=160,到76的时候是80+76=236。接着往下走,然后新的分组也是同样往下走。’FOLLOWING是往后计算行数,AVG、COUNT、MAX、MIN也是同样的道理
4、RANK、DENSE_RANK、ROW_NUMBER:
查询各科成绩前三名的记录:
select * from ( select cid,score, rank() over(partition by cid order by score desc) r from sc) where r<4
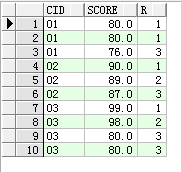
内层查询便是窗口函数的应用了,首先数据会按照cid列(partition by)进行分组,然后每组按照score(order by)排序,最后的rank()会返回数据的排名,这个排名是每组(cid)数据按照score的排序。
RANK函数
计算排序时,如果存在相同位次的记录,则会跳过之后的位次。
例)有 3 条记录排在第 1 位时:1 位、1 位、1 位、4 位……
DENSE_RANK函数
同样是计算排序,即使存在相同位次的记录,也不会跳过之后的位次。
例)有 3 条记录排在第 1 位时:1 位、1 位、1 位、2 位……
ROW_NUMBER函数
赋予唯一的连续位次。
有 3 条记录排在第 1 位时:1 位、2 位、3 位、4 位……