部署环境
虚拟机5台(1G内存,40G硬盘,ubuntu操作系统,Hadoop-0.20.2,Zookeeper-3.3.2,Hbase-0.20.6)
hadoop1-virtual-machine 10.10.11.250 主namenode
hadoop2-virtual-machine 10.10.11.152 datanode
hadoop3-virtual-machine 10.10.11.160 datanode
hadoop4-virtual-machine 10.10.11.184 secondarynamenode
hadoop5-virtual-machine 10.10.12.25 备份namenode
相关资源及描述
DRBD:提供数据的备份,保证数据的高可用性。
文件系统:和DRBD相关,DRBD主备节点切换时,卸载或加载相应的分区。
VIP:向外提供统一的访问地址,主要是针对hadoop及hbase而言,屏蔽节点迁移时ip不一致的问题。在pacemaker资源中配置。
Hadoop相关资源:hdfs服务(用来启动namenode),jobtracker服务(用来启动jobtracker),如果集群的secondarynamenode服务也包括在namenode中,那就同时必须准备secondarynamenode服务。
Pacemaker:集群管理,包括资源检测及恢复等
部署
一. 安装DRBD
关于DRBD的介绍及安装请参考相关文档DRBD介绍、DRBD部署。
以下为本次DRBD的配置文件,与DRBD一般安装有所不同,安装时请注意。
1. global_common.conf
global { usage-count no; # minor-count dialog-refresh disable-ip-verification } common { protocol C; handlers { pri-on-incon-degr "/usr/lib/drbd/notify-pri-on-incon-degr.sh; /usr/lib/drbd/notify-emergency-reboot.sh; echo b > /proc/sysrq-trigger ; reboot -f"; pri-lost-after-sb "/usr/lib/drbd/notify-pri-lost-after-sb.sh; /usr/lib/drbd/notify-emergency-reboot.sh; echo b > /proc/sysrq-trigger ; reboot -f"; local-io-error "/usr/lib/drbd/notify-io-error.sh; /usr/lib/drbd/notify-emergency-shutdown.sh; echo o > /proc/sysrq-trigger ; halt -f"; fence-peer "/usr/lib/drbd/crm-fence-peer.sh"; split-brain "/usr/lib/drbd/notify-split-brain.sh root"; # out-of-sync "/usr/lib/drbd/notify-out-of-sync.sh root"; # before-resync-target "/usr/lib/drbd/snapshot-resync-target-lvm.sh -p 15 -- -c 16k"; after-resync-target /usr/lib/drbd/crm-unfence-peer.sh; } startup { # wfc-timeout degr-wfc-timeout outdated-wfc-timeout wait-after-sb # wfc-timeout 15; # degr-wfc-timeout 15; # outdated-wfc-timeout 15; } disk { # on-io-error fencing use-bmbv no-disk-barrier no-disk-flushes # no-disk-drain no-md-flushes max-bio-bvecs on-io-error detach; fencing resource-only; } net { # sndbuf-size rcvbuf-size timeout connect-int ping-int ping-timeout max-buffers # max-epoch-size ko-count allow-two-primaries cram-hmac-alg shared-secret # after-sb-0pri after-sb-1pri after-sb-2pri data-integrity-alg no-tcp-cork timeout 60; connect-int 15; ping-int 15; ping-timeout 50; max-buffers 8192; ko-count 100; cram-hmac-alg sha1; shared-secret "123456"; } syncer { # rate after al-extents use-rle cpu-mask verify-alg csums-alg rate 10M; al-extents 512; #verify-alg sha1; csums-alg sha1; } } |
2.namenode.res
resource namenode { meta-disk internal; device /dev/drbd0; #device指定的参数最后必须有一个数字,用于global的minor-count,否则会device指定drbd应用层设备。 disk /dev/sdb1; #所有语句末尾必须有分号。disk指定存储数据的底层设备。 on hadoop1-virtual-machine { #注意:drbd配置文件中,机器名大小写敏感! address 10.10.11.250:9876; } on hadoop5-virtual-machine { address 10.10.12.25:9876; } } |
3. 关闭DRBD的开机启动,这里DRBD作为集群资源将由pacemaker统一管理。
chkconfig --level 2345 drbd off
4. 自动切换drbd的master和slave应该在DRBD同步数据之后,否则将无法切换。
cat /proc/drbd 或drbd_overview 查看数据同步状态
二. 安装Pacemaker
关于Pacemaker的介绍及安装请参考相关文档Pacemaker介绍、Pacemaker部署。
以下为本次Pacemaker的配置文件,与Pacemaker一般安装有所不同,安装时请注意。
1. corosync.conf
# Please read the corosync.conf.5 manual page compatibility: whitetank totem { version: 2 secauth: on threads: 0 interface { ringnumber: 0 bindnetaddr: 10.10.0.0 mcastaddr: 226.94.1.1 mcastport: 5405 } } amf { mode: disabled } service { # Load the Pacemaker Cluster Resource Manager ver: 0 name: pacemaker } aisexec { user: root group: root } logging { fileline: off to_stderr: yes to_logfile: yes to_syslog: yes logfile: /var/log/corosync/corosync.log debug: off timestamp: on logger_subsys { subsys: AMF debug: off } } |
2. 开启corosync的开机启动
chkconfig --level 2345 corosync on
三. Hadoop配置
这里修改hadoop&hbase配置主要是修改ip地址为vip地址,同时修改文件夹路径为基于DRBD的文件系统路径(后面将在packemaker中配置,挂载路径为/drbddata)。
首先修改所有主机的/etc/hosts文件增加vip(后面将在packemaker中配置,为10.10.12.88)与虚拟主机名VHOST的映射。
10.10.12.88 VHOST
修改以下配置文件,并分发到集群各个节点(包括备份namenode)
1. core-site.xml
<property> <name>fs.default.name</name> <value>hdfs://VHOST:9000</value> </property>
<property> <name>hadoop.tmp.dir</name> <value>/home/hadoop/drbddata/tmp</value> </property> |
2. hdfs-site.xml
<property> <name>dfs.name.dir</name> <value>/home/hadoop/drbddata/name</value> </property> |
3. mapred-site.xml
<property> <name>mapred.job.tracker</name> <value>VHOST:9001</value> </property>
<property> <name>mapred.job.tracker.http.address</name> <value>VHOST:50030</value> </property> |
4. hbase-site.xml
<property> <name>base.rootdir</name> <value>hdfs://VHOST:9000/hbase</value> </property> |
四. Hadoop相关资源
1. hdfs脚本
用于启动/停止namenode节点的hdfs服务。
复制start-dfs.sh及stop-dfs.sh脚本于bin目录下,删除脚本最后两行,重命名为 start-namenode.sh和stop-namenode.sh。
2. jobtracker脚本
用于启动/停止namenode节点的jobtracker服务。
复制start-mapred.sh及stop-mapred.sh脚本于bin目录下,删除脚本最后一行, 重命名为start-jobtracker.sh和stop-jobtracker.sh。
3. 创建hdfs资源服务
于/etc/init.d目录下,创建dfs脚本(基于LSB标准),内容如下(红色字体为相应hadoop集群路径及用户):
#! /bin/sh #This is a Resource Agent for managing hadoop namenode #2011-12-22 by zhangzhiwei # HADOOP_HOME=/home/hadoop/hadoop HADOOP_PID_DIR=/tmp DFS_USER=hadoop DFS_START=$HADOOP_HOME/bin/start-namenode.sh DFS_STOP=$HADOOP_HOME/bin/stop-namenode.sh start() { echo -n "Starting dfs: " su - $DFS_USER -c $DFS_START sleep 10 if netstat -an |grep 50070 >/dev/null then echo "dfs is running" return 0 else return 3 fi } stop() { if netstat -an |grep 50070 |grep LISTEN >/dev/null then echo "Shutting down dfs" su - $DFS_USER -c $DFS_STOP else echo "dfs is not running" return 3 fi if netstat -an |grep 50070 |grep LISTEN >/dev/null then sleep 10 kill -9 $(cat $HADOOP_PID_DIR/hadoop-$DFS_USER-namenode.pid) fi } restart() { if netstat -an |grep 50070 |grep LISTEN >/dev/null then stop sleep 10 start else start return 0 fi } status() { if netstat -an |grep 50070 |grep LISTEN >/dev/null then echo "dfs is running" return 0 else echo "dfs is stopped" return 3 fi } case "$1" in start) start ;; stop) stop ;; restart|force-reload) restart ;; status) status ;; *) echo "Usage: /etc/init.d/dfs {start|stop|restart|status}" exit 1 ;; esac exit 0 |
4. 创建mapred资源服务
于/etc/init.d目录下,创建mapred脚本(基于LSB标准),内容如下(红色字体为相应hadoop集群路径及用户):
#! /bin/sh #This is a Resource Agent for managing hadoop jobtracker #2011-12-22 by zhangzhiwei # HADOOP_HOME=/home/hadoop/hadoop HADOOP_PID_DIR=/tmp MAPRED_USER=hadoop MAPRED_START=$HADOOP_HOME/bin/start-jobtracker.sh MAPRED_STOP=$HADOOP_HOME/bin/stop-jobtracker.sh start() { echo -n "Starting mapred: " su - $MAPRED_USER -c $MAPRED_START sleep 10 if netstat -an |grep 50030 >/dev/null then echo "mapred is running" return 0 else return 3 fi } stop() { if netstat -an |grep 50030 |grep LISTEN >/dev/null then echo "Shutting down mapred" su - $MAPRED_USER -c $MAPRED_STOP else echo "mapred is not running" return 3 fi if netstat -an |grep 50030 |grep LISTEN >/dev/null then sleep 10 kill -9 $(cat $HADOOP_PID_DIR/hadoop-$MAPRED_USER-jobtracker.pid) fi } restart() { if netstat -an |grep 50030 |grep LISTEN >/dev/null then stop sleep 10 start else start return 0 fi } status() { if netstat -an |grep 50030 |grep LISTEN >/dev/null then echo "mapred is running" return 0 else echo "mapred is stopped" return 3 fi } case "$1" in start) start ;; stop) stop ;; restart|force-reload) restart ;; status) status ;; *) echo "Usage: /etc/init.d/mapred {start|stop|restart|status}" exit 1 ;; esac exit 0 |
注:以上两脚本对于配置不一样的集群可能不是通用的,可单独测试下是否能启动或关掉相应进程。
五. 配置Pacemaker资源
有关资源配置请参考
http://blog.csdn.net/rzhzhz/article/details/7108405
切换到root用户下,打开pacemaker资源配置控制台
crm configure
防止输入有误,建议在每次配置后都commit下,看是否有错,有助于尽快的定位并解决错误的配置问题。
1. 配置no-quorum-policy和stonith-enabled
crm(live)configure# property no-quorum-policy=ignore
crm(live)configure# property stonith-enabled=false
crm(live)configure# commit
2. 配置VIP资源
crm(live)configure# primitive VIP ocf:heartbeat:IPaddr2
>params ip="10.10.12.88" cidr_netmask="32"
>op monitor interval="20s" timeout="30s"
crm(live)configure# commit
3. 配置hdfs资源(即配置前面基于LSB标准的dfs脚本)
crm(live)configure# primitive namenode lsb:dfs
crm(live)configure# commit
4. 配置mapred资源(即配置前面基于LSB标准的mapred脚本)
crm(live)configure# primitive jobtracker lsb:mapred
crm(live)configure# commit
5. 编组hadoop资源
crm(live)configure# group HADOOP namenode jobtracker
crm(live)configure# commit
6. 配置HADOOP组资源与VIP资源的约束
crm(live)configure# colocation HADOOP-with-VIP inf: HADOOP VIP
crm(live)configure# order HADOOP-after-VIP inf: VIP HADOOP
crm(live)configure# commit
7. 设置资源粘性,防止资源在节点间的频繁迁移
crm(live)configure# rsc_defaults resource-stickiness=100
crm(live)configure# commit
8. 设置集群的时间间隔
crm(live)configure# property default-action-timeout=60
crm(live)configure# commit
9. 创建DRBD资源,及其状态克隆资源 (使用ocf:linbit:drbd配置DRBD )
crm(live)configure# cd
crm(live)# cib new drbd
INFO: drbd shadow CIB created
crm(drbd)# configure primitive drbd0 ocf:linbit:drbd
> params drbd_resource=namenode
> op start timeout=250
> op stop timeout=110
> op promote timeout=100
> op demote timeout=100
> op notify timeout=100
> op monitor role=Master interval=20 timeout=30
> op monitor role=Slave interval=30 timeout=30
crm(drbd)# configure ms ms-drbd0 drbd0
> meta master-max=1 master-node-max=1 clone-max=2 clone-node-max=1 notify=true
crm(drbd)# cib commit drbd
INFO: commited 'drbd' shadow CIB to the cluster
10. 创建文件系统资源 (基于DRBD)
crm(drbd)# cib use live
crm(live)# cib new fs
INFO: fs shadow CIB created
crm(fs)# configure primitive fs-drbd0 ocf:heartbeat:Filesystem
> params device=/dev/drbd0 directory=/home/hadoop/drbddata fstype=xfs
crm(fs)# cib commit fs
INFO: commited 'fs' shadow CIB to the cluster
11. 配置文件系统与drbd资源的两个约束
crm(fs)# cib use live
crm(live)# configure
crm(live)configure# colocation fs-on-drbd0 inf: fs-drbd0 ms-drbd0:Master
crm(live)configure# order fs-after-drbd0 inf: ms-drbd0:promote fs-drbd0:start
crm(live)configure# commit
12. 配置组资源hadoop与文件系统的两个约束
crm(live)configure# colocation HADOOP-on-fs inf: HADOOP fs-drbd0
crm(live)configure# order HADOOP-after-fs inf: fs-drbd0 HADOOP
crm(live)configure# commit
13. 配置完成,查看集群配置
root@hadoop1-virtual-machine:/home/hadoop# crm configure show
node hadoop1-virtual-machine
attributes standby="off"
node hadoop5-virtual-machine
attributes standby="off"
primitive VIP ocf:heartbeat:IPaddr2
params ip="10.10.12.88" cidr_netmask="32"
op monitor interval="20s" timeout="30s"
primitive drbd0 ocf:linbit:drbd
params drbd_resource="namenode"
op start interval="0" timeout="250"
op stop interval="0" timeout="110"
op promote interval="0" timeout="100"
op demote interval="0" timeout="100"
op notify interval="0" timeout="100"
op monitor interval="20" role="Master" timeout="30"
op monitor interval="30" role="Slave" timeout="30"
primitive fs-drbd0 ocf:heartbeat:Filesystem
params device="/dev/drbd0" directory="/home/hadoop/drbddata" fstype="xfs"
primitive jobtracker lsb:mapred
primitive namenode lsb:dfs
group HADOOP namenode jobtracker
ms ms-drbd0 drbd0
meta master-max="1" master-node-max="1" clone-max="2" clone-node-max="1" notify="true"
colocation HADOOP-on-fs inf: HADOOP fs-drbd0
colocation HADOOP-with-VIP inf: HADOOP VIP
colocation fs-on-drbd0 inf: fs-drbd0 ms-drbd0:Master
order HADOOP-after-VIP inf: VIP HADOOP
order HADOOP-after-fs inf: fs-drbd0 HADOOP
order fs-after-drbd0 inf: ms-drbd0:promote fs-drbd0:start
property $id="cib-bootstrap-options"
dc-version="1.0.9-unknown"
cluster-infrastructure="openais"
expected-quorum-votes="2"
stonith-enabled="false"
no-quorum-policy="ignore"
default-action-timeout="60"
rsc_defaults $id="rsc-options"
resource-stickiness="100"
注:crm_verify -L 命令可以查看错误的configure信息,出现如下错误时,此错误是一个版本遗留问题,可直接忽略。
crm_verify[6067]: 2011/12/29_00:24:08 ERROR: create_notification_boundaries: Creating boundaries for ms-drbd0
crm_verify[6067]: 2011/12/29_00:24:08 ERROR: create_notification_boundaries: Creating boundaries for ms-drbd0
crm_verify[6067]: 2011/12/29_00:24:08 ERROR: create_notification_boundaries: Creating boundaries for ms-drbd0
crm_verify[6067]: 2011/12/29_00:24:08 ERROR: create_notification_boundaries: Creating boundaries for ms-drbd0
测试
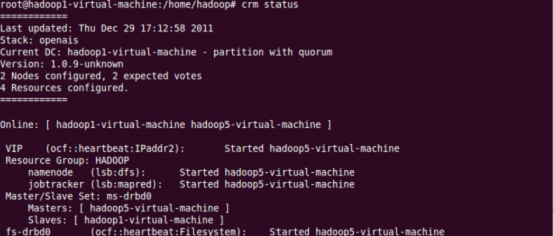
1. 查看集群状态crm status,hadoop1-virtual-machine为主节点,hadoop5-virtual-machine为备份节点。

2. 在hadoop1-virtual-machine主节点执行命令crm node standby ,查看集群状态crm status,大概20秒后hadoop5-virtual-machine切换成主节点。

3. 在hadoop1-virtual-machine主节点执行命令crm node online ,查看集群状态crm status,hadoop5-virtual-machine依旧是主节点。Hadoop1-virtual-machine成为备份节点。
Hadoop&Hbase集群测试
基于Hbase的master本身就不存在单点问题(可以在多个节点启动master服务),在这里就不用作热备考虑。
把HA集群恢复到初始状态hadoop1-virtual-machine作为Master,hadoop5-virtual-machine作为Slave。在Master上启动hadoop集群及hbase集群(zookeeper集群部署在其他节点),在Slave上启动hbase的HMaster进程(采用hbase本身对于HMaster备份的方案)。
1.关闭Master主机(模拟namenode主节点宕机),原slave切换成master,切换时间大概是30秒左右,期间集群不能向外提供服务,之后Hadoop处于safe mode(只能读不能写)状态,最后才正常向外提供服务。启动原Master主机,自动重新加入集群,不过其角色变成了slave。
2.关闭Master主机的网络ifconfig eth0 down(模拟namenode主节点网络故障),原slave切换成master,切换时间大概是30秒左右,期间集群不能向外提供服务,之后Hadoop处于safe mode(只能读不能写)状态,最后才正常向外提供服务。启动原Master主机的网络ifconfig eth0 up(此时VIP服务会出现问题,重启corosync (service corosync restart) 即可解决),自动重新加入集群,不过其角色变成了slave。