环境准备
服务器四台:
| 系统信息 | 角色 | hostname | IP地址 |
| Centos7.4 | Mster | hadoop-master-001 | 10.0.15.100 |
| Centos7.4 | Slave | hadoop-slave-001 | 10.0.15.99 |
| Centos7.4 | Slave | hadoop-slave-002 | 10.0.15.98 |
| Centos7.4 | Slave | hadoop-slave-003 | 10.0.15.97 |
四台节点统一操作操作
创建操作用户
gourpadd hduser
useradd hduser -g hduser
切换用户并配置java环境变量
笔者这里用的1.8的
JAVA_HOME=~/jdk1.8.0_151
PATH=$PATH:$JAVA_HOME/bin
export JAVA_HOME
export PATH
配置/etc/hosts
10.0.15.100 hadoop-master-001
10.0.15.99 hadoop-data-001
10.0.15.98 hadoop-data-002
10.0.15.97 hadoop-data-003
设置ssh免密
这个网上比较多,这里不在累述
安装流程(所有节点,包括master与slave)
下载hadoop并安装
http://mirror.bit.edu.cn/apache/hadoop/common/hadoop-2.7.7/hadoop-2.7.7.tar.gz
tar -zxvf hadoop-2.7.7.tar.gz
移动并修改权限
chown hduser:hduser hadoop-2.7.7
mv hadoop-2.7.7 /usr/local/hadoop
切换用户并配置环境变量
su - hduser
vim .basrc
#变量信息
export JAVA_HOME=/home/hduser/jdk1.8.0_151
export HADOOP_HOME=/usr/local/hadoop
export PATH=$PATH:$HADOOP_HOME/bin
export PATH=$PATH:$HADOOP_HOME/sbin
export HADOOP_MAPRED_HOME=$HADOOP_HOME
export HADOOP_COMMON_HOME=$HADOOP_HOME
export HADOOP_HDFS_HOME=$HADOOP_HOME
export YARN_HOME=$HADOOP_HOME
export HADOOP_COMMON_HOME=$HADOOP_HOME
export HADOOP_HDFS_HOME=$HADOOP_HOME
export YARN_HOME=$HADOOP_HOME
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export HADOOP_OPTS="-Djava.library.path=$HADOOP_HOME/lib"
export JAVA_LIBRARY_PATH=$HADOOP_HOME/lib/native:$JAVA_LIBRARY_PATH
修改Master配置文件
vim hadoop-env.sh
/**/
配置java路径
export JAVA_HOME=/home/hduser/jdk1.8.0_151
/**/
vim core-site.xml
/**/
<configuration>
<property>
<name>fs.default.name</name>
<value>hdfs://hadoop-master-001:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/data/hadoop_data/hadoop_tmp</value>
</property>
</configuration>
/**/
vim hdfs-site.xml
/**/
<configuration>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/data/hadoop_data/hdfs/namenode</value> #创建真实的路径用来存放名称节点
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/data/hadoop_data/hdfs/datanode</value> #创建真实的路径用了存放数据
</property>
</configuration>
/**/
vim mapred-site.xml
/**/
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
/**/
vim yarn-site.xml
/**/
<configuration>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hadoop-master-001</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
<property>
<name>yarn.resourcemanager.address</name>
<value>hadoop-master-001:8050</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>hadoop-master-001:8030</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>hadoop-master-001:8025</value>
</property>
#使用hadoop yarn运行pyspark时,不添加下面两个参数会报错
<property>
<name>yarn.nodemanager.pmem-check-enabled</name>
<value>false</value>
</property>
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
</configuration>
/**/
修改Slave配置文件
vim hadoop-env.sh
/**/
配置java路径
export JAVA_HOME=/home/hduser/jdk1.8.0_151
/**/
vim core-site.xml
/**/
<configuration>
<property>
<name>fs.default.name</name>
<value>hdfs://hadoop-master-001:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/data/hadoop_data/hadoop_tmp</value>
</property>
</configuration>
/**/
vim hdfs-site.xml
/**/
<configuration>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/home/data/hadoop_data/hdfs/datanode</value>
</property>
</configuration>
/**/
vim mapred-site.xml
/**/
<configuration>
<property>
<name>mapred.job.tracker</name>
<value>hadoop-master-001:54311</value>
</property>
</configuration>
/**/
vim yarn-site.xml
/**/
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
<property>
<name>yarn.resourcemanager.address</name>
<value>hadoop-master-001:8050</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>hadoop-master-001:8030</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>hadoop-master-001:8025</value>
</property>
#使用hadoop yarn运行pyspark时,不添加下面两个参数会报错
<property>
<name>yarn.nodemanager.pmem-check-enabled</name>
<value>false</value>
</property>
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
</configuration>
/**/
其他操作(所有节点,包括master与slave)
#执行hadoop 命令报WARNING解决办法
vim log4j.properties添加如下行
log4j.logger.org.apache.hadoop.util.NativeCodeLoader=ERROR
启动操作
安装并配置完成后返回master节点格式化namenode
cd /data/hadoop_data/hdfs/namenode
hadoop namenode -format
在master节点执行命令
start-all.sh //启动
stop-all.sh //关闭
异常处理
hadoop数据节点查看hdfs文件时:
ls: No Route to Host from hadoop-data-002/10.0.15.98 to hadoop-master-001:9000 failed on socket timeout exception: java.net.NoRouteToHostException: 没有到主机的路由; For more details see: http://wiki.apache.org/hadoop/NoRouteToHost
解决方式数据节点telnet namenode的9000端口
正常原因/etc/hosts中主机名与ip地址不符或者端口未开放防火墙引起
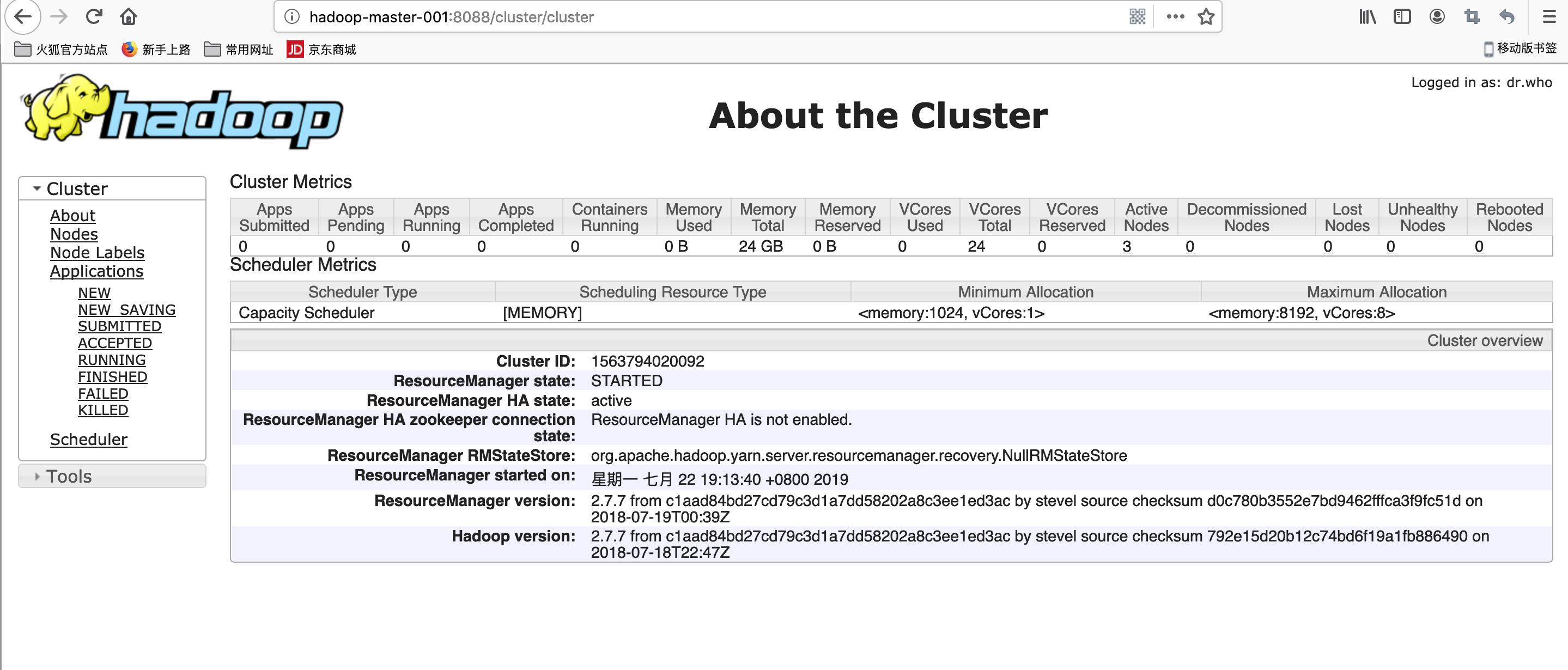
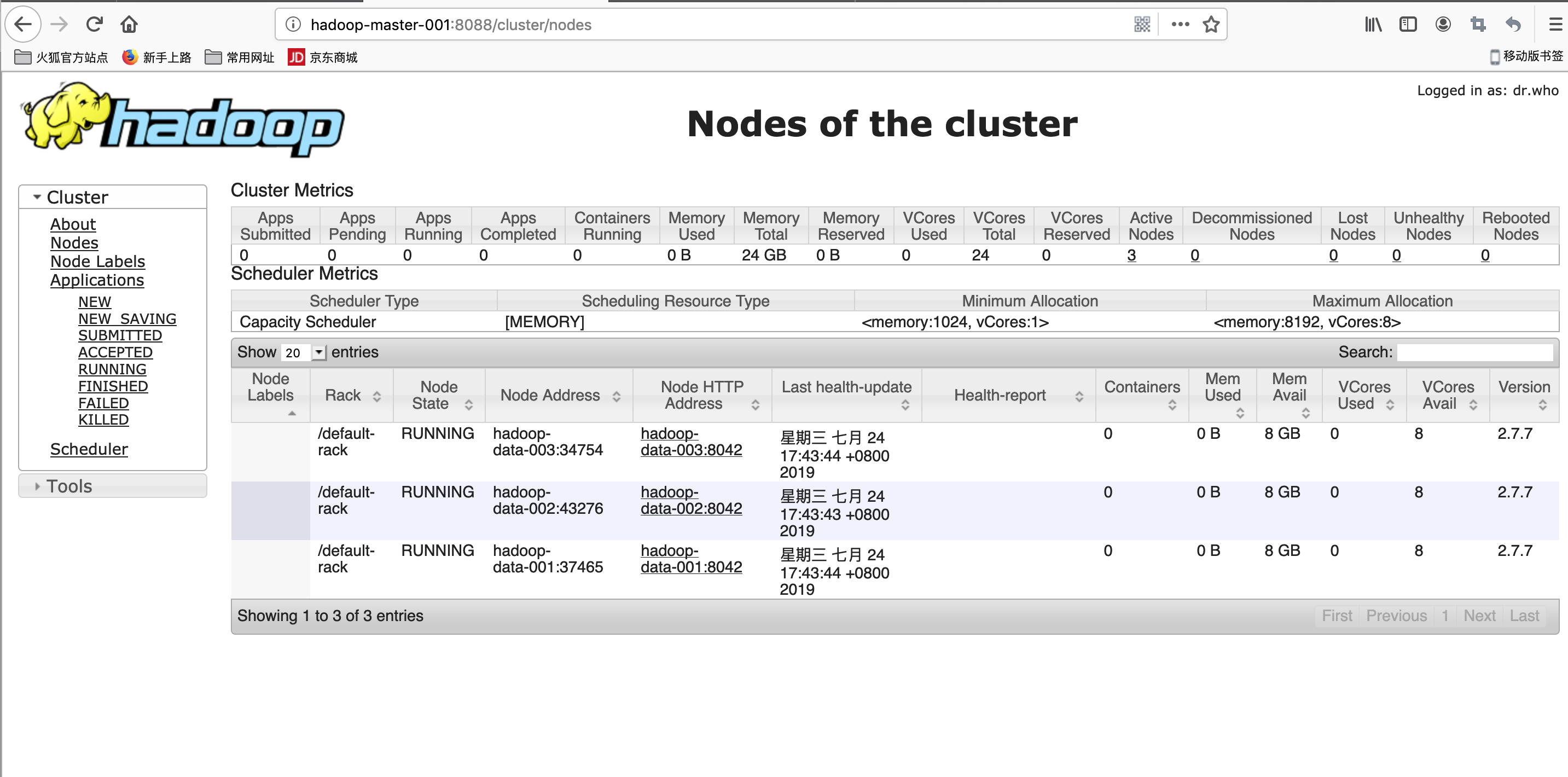
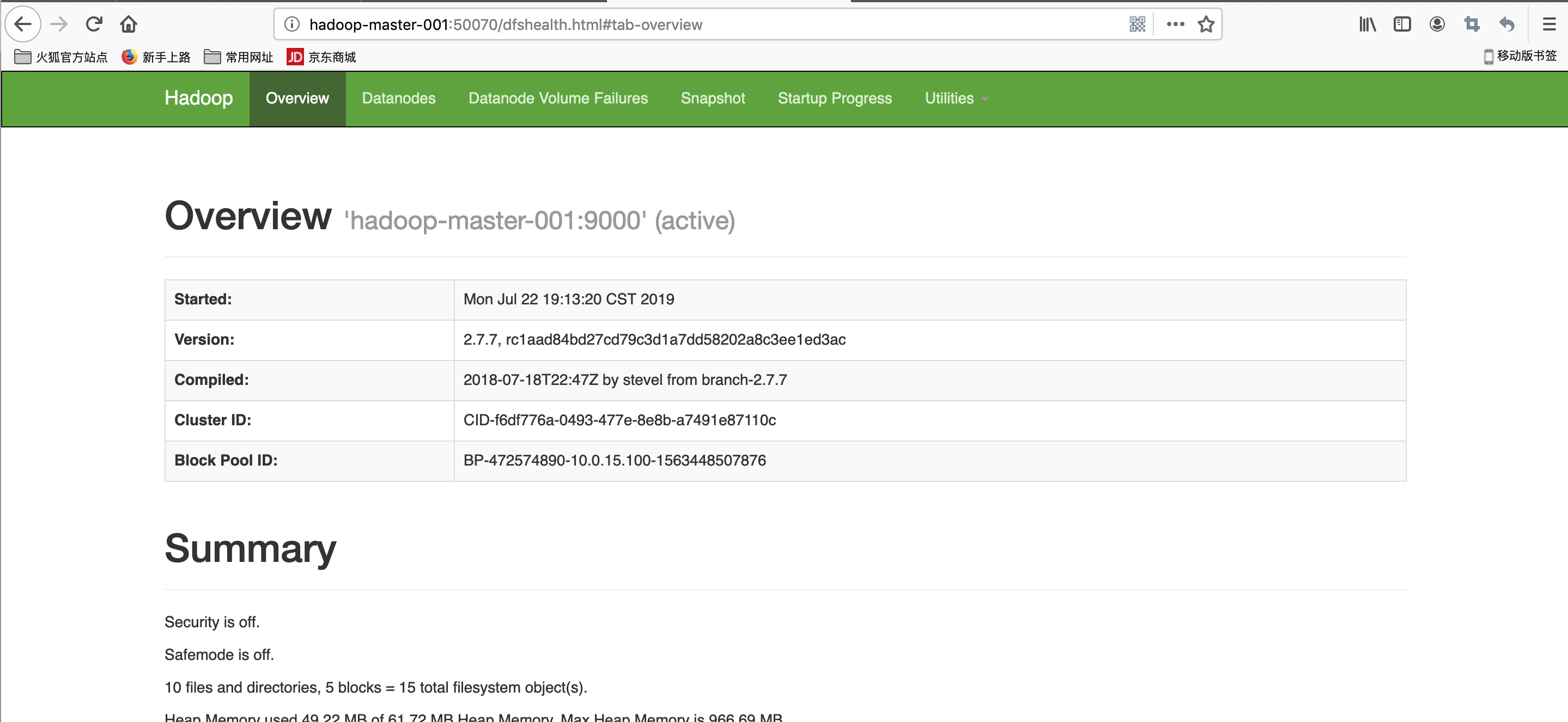
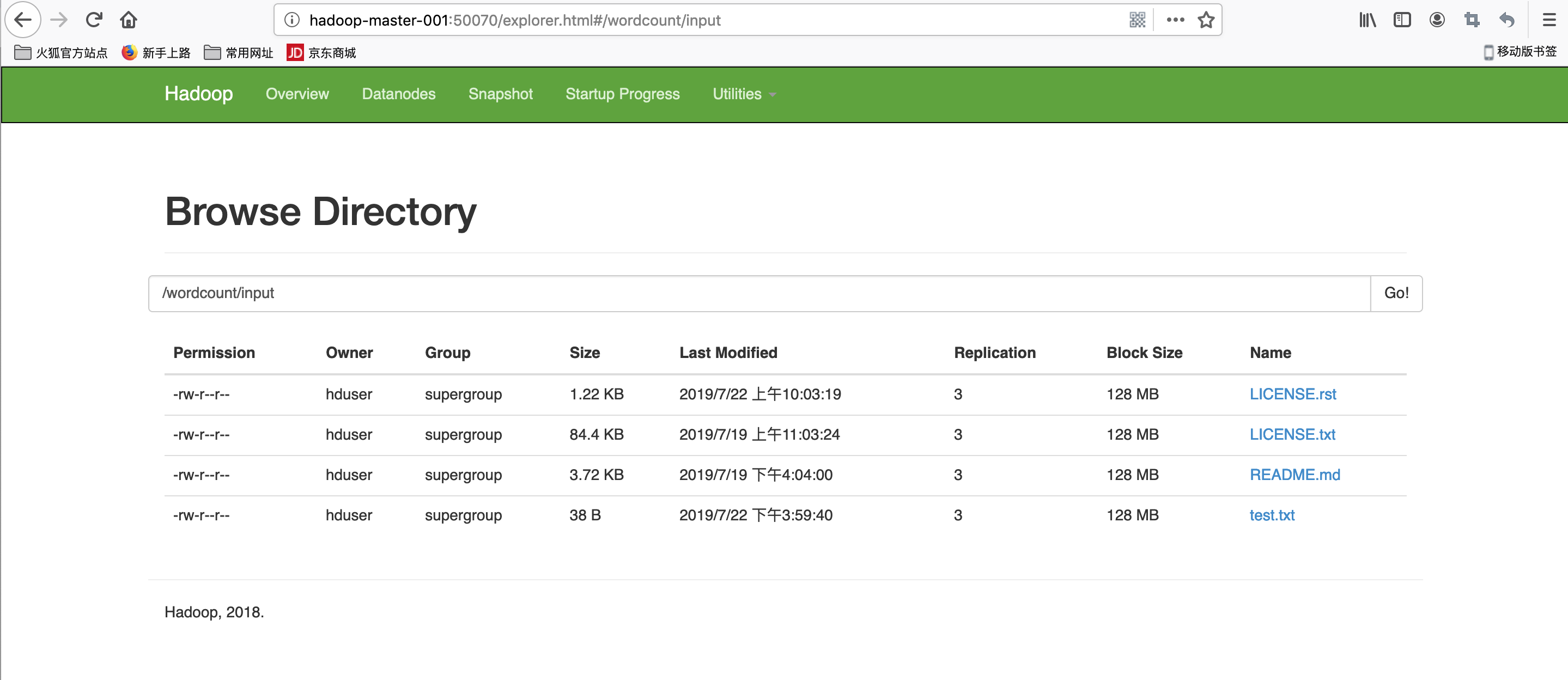
效果图