V8 是怎么跑起来的 —— V8 中的对象表示
本文创作于 2019-04-30,2019-12-20 迁移至此
本文基于 Chrome 73 进行测试。
前言
V8,可能是前端开发人员熟悉而又陌生的领域。
当你看到这篇文章时,它已经迭代了三版了。目的只有一个,在保证尽可能准确的前提下,用更直观的方式呈现出来,让大家更加容易接受。本文不需要太多的预备知识,只需要你对 JavaScript 对象有基本的了解。
为了让文章不那么枯燥,也为了证实观点的准确性,文章中包含了很多的小实验,大家可以在控制台中尽情把玩。
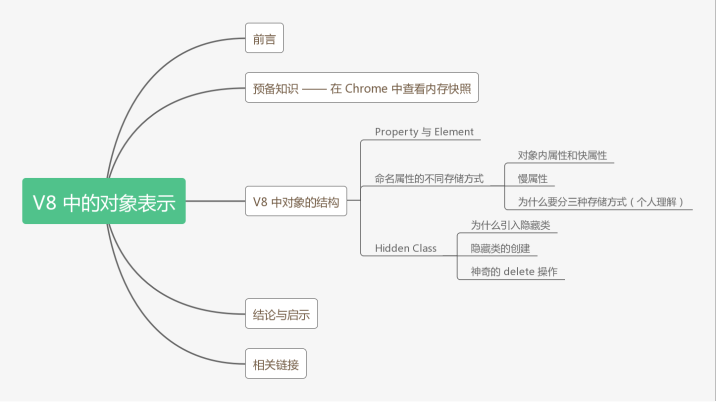
预备知识 —— 在 Chrome 中查看内存快照
首先我们在控制台运行这样一段程序。
function Food(name, type) {
this.name = name;
this.type = type;
}
var beef = new Food('beef', 'meat');切换到 Memory 中,点击左侧的小圈圈就可以捕获当前的内存快照。
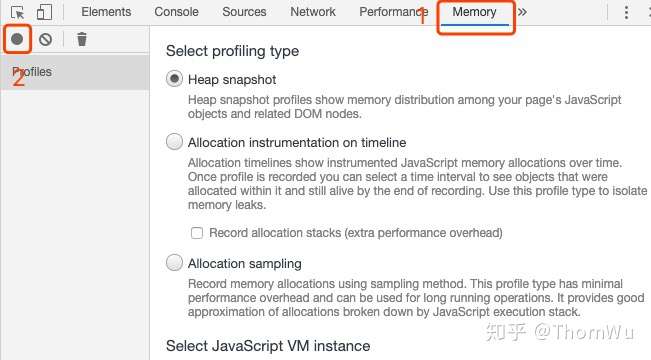
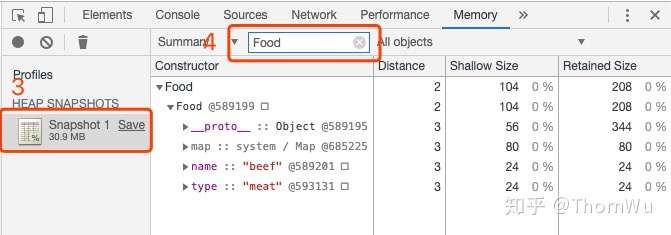
通过构造函数创建对象,主要是为了更方便地在快照中找到它。点开快照后,在过滤器中输入 Food 就可以找到由 Food 构造的所有对象了,神奇吧。
V8 中对象的结构
在 V8 中,对象主要由三个指针构成,分别是隐藏类(Hidden Class),Property 还有 Element。
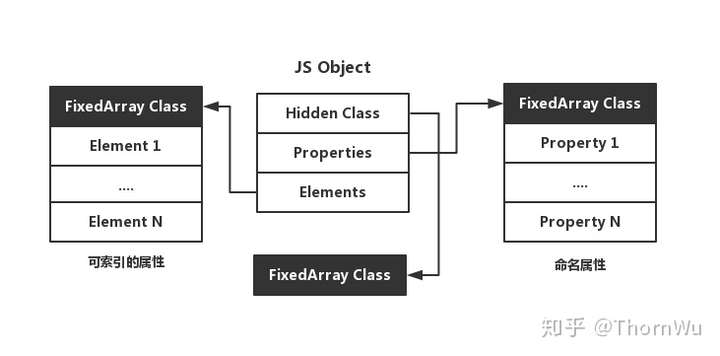
其中,隐藏类用于描述对象的结构。Property 和 Element 用于存放对象的属性,它们的区别主要体现在键名能否被索引。
Property 与 Element
// 可索引属性会被存储到 Elements 指针指向的区域
{ 1: "a", 2: "b" }
// 命名属性会被存储到 Properties 指针指向的区域
{ "first": 1, "second": 2 }事实上,这是为了满足 ECMA 规范 要求所进行的设计。按照规范中的描述,可索引的属性应该按照索引值大小升序排列,而命名属性根据创建的顺序升序排列。
我们来做个简单的小实验。
var a = { 1: "a", 2: "b", "first": 1, 3: "c", "second": 2 }
var b = { "second": 2, 1: "a", 3: "c", 2: "b", "first": 1 }
console.log(a)
// { 1: "a", 2: "b", 3: "c", first: 1, second: 2 }
console.log(b)
// { 1: "a", 2: "b", 3: "c", second: 2, first: 1 }a 和 b 的区别在于 a 以一个可索引属性开头,b 以一个命名属性开头。在 a 中,可索引属性升序排列,命名属性先有 first 后有 second。在 b 中,可索引属性乱序排列,命名属性先有 second 后有 first。
可以看到
- 索引的属性按照索引值大小升序排列,而命名属性根据创建的顺序升序排列。
- 在同时使用可索引属性和命名属性的情况下,控制台打印的结果中,两种不同属性之间存在的明显分隔。
- 无论是可索引属性还是命名属性先声明,在控制台中总是以相同的顺序出现(在我的浏览器中,可索引属性总是先出现)。
这两点都可以从侧面印证这两种属性是分开存储的。
侧面印证完了,我们来看看正面。我们用预备知识中的方法,查看这两种属性的快照。
// 实验1 可索引属性和命名属性的存放
function Foo1 () {}
var a = new Foo1()
var b = new Foo1()
a.name = 'aaa'
a.text = 'aaa'
b.name = 'bbb'
b.text = 'bbb'
a[1] = 'aaa'
a[2] = 'aaa'
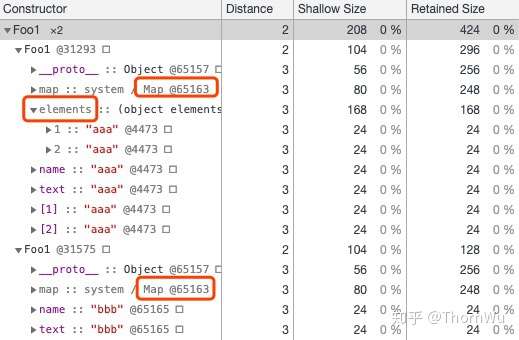
a、b 都有命名属性 name 和 text,此外 a 还额外多了两个可索引属性。从快照中可以明显的看到,可索引属性是存放在 Elements 中的,此外,a 和 b 具有相同的结构(这个结构会在下文中介绍)。
你可能会有点好奇,这两个对象的属性不一样,怎么会有相同的结构呢?要理解这个问题,首先可以问自己三个问题。
- 为什么要把对象存起来?当然是为了之后要用呀。
- 要用的时候需要做什么?找到这个属性咯。
- 描述结构是为了做什么呢?按图索骥,方便查找呀。
那么,对于可索引属性来说,它本身已经是有序地进行排列了,我们为什么还要多次一举通过它的结构去查找呢。既然不用通过它的结构查找,那么我们也不需要再去描述它的结构了是吧。这样,应该就不难理解为什么 a 和 b 具有相同的结构了,因为它们的结构中只描述了它们都具有 name 和 text 这样的情况。
当然,这也是有例外的。我们在上面的代码中再加入一行。
a[1111] = 'aaa'
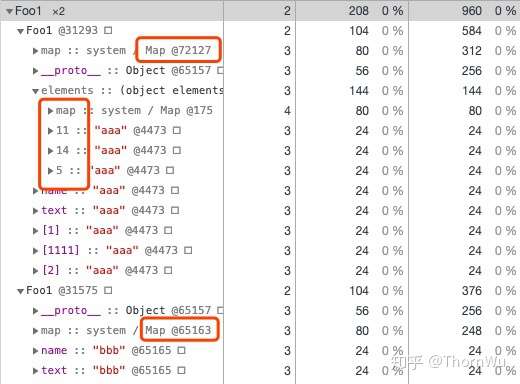
可以看到,此时隐藏类发生了变化,Element 中的数据存放也变得没有规律了。这是因为,当我们添加了 a[1111] 之后,数组会变成稀疏数组。为了节省空间,稀疏数组会转换为哈希存储的方式,而不再是用一个完整的数组描述这块空间的存储。所以,这几个可索引属性也不能再直接通过它的索引值计算得出内存的偏移量。至于隐藏类发生变化,可能是为了描述 Element 的结构发生改变(这个图片可以与下文中慢属性的配图进行比较,可以看到 Foo1 的 Property 并没有退化为哈希存储,只是 Element 退化为哈希存储导致隐藏类发生改变)。
命名属性的不同存储方式
V8 中命名属性有三种的不同存储方式:对象内属性(in-object)、快属性(fast)和慢属性(slow)。
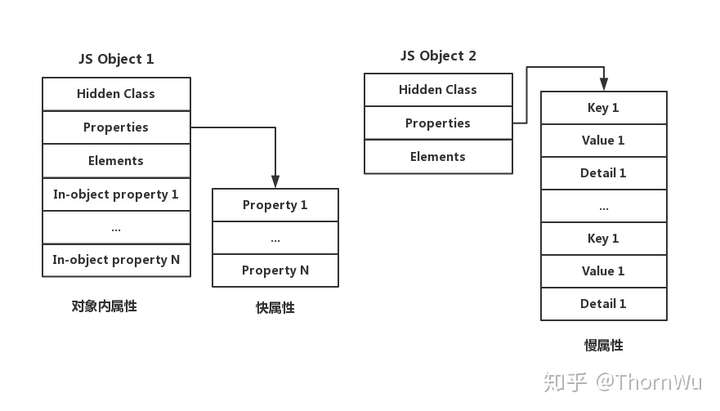
- 对象内属性保存在对象本身,提供最快的访问速度。
- 快属性比对象内属性多了一次寻址时间。
- 慢属性与前面的两种属性相比,会将属性的完整结构存储(另外两种属性的结构会在隐藏类中描述,隐藏类将在下文说明),速度最慢(在下文或其它相关文章中,慢属性、属性字典、哈希存储说的都是一回事)。
这样是不是有点抽象。别急,我们通过一个例子来说明。
// 实验2 三种不同类型的 Property 存储模式
function Foo2() {}
var a = new Foo2()
var b = new Foo2()
var c = new Foo2()
for (var i = 0; i < 10; i ++) {
a[new Array(i+2).join('a')] = 'aaa'
}
for (var i = 0; i < 12; i ++) {
b[new Array(i+2).join('b')] = 'bbb'
}
for (var i = 0; i < 30; i ++) {
c[new Array(i+2).join('c')] = 'ccc'
}a、b 和 c 分别拥有 10 个,12 个和 30 个属性,在目前的 Chrome 73 版本中,分别会以对象内属性、对象内属性 + 快属性、慢属性三种方式存储。这块的运行快照有点长,我们分别看一看。
对象内属性和快属性
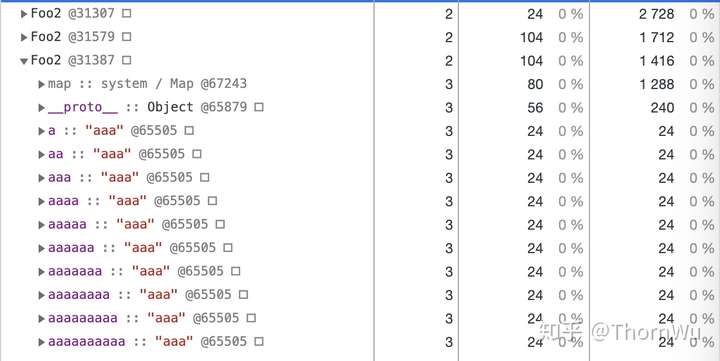
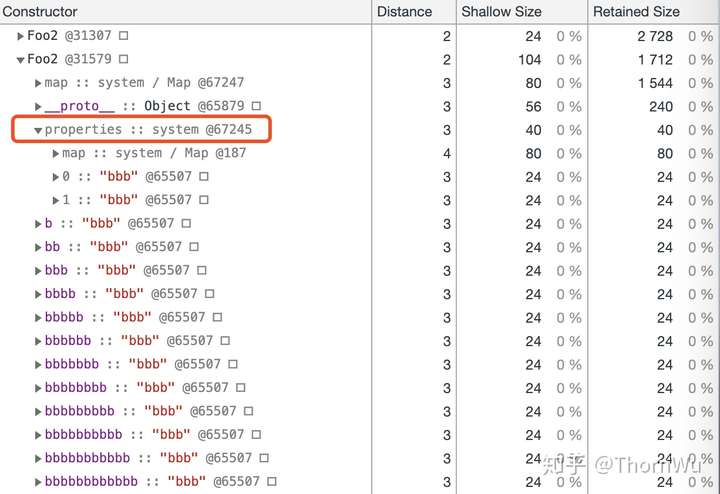
首先我们看一下 a 和 b。从某种程度上讲,对象内属性和快属性实际上是一致的。只不过,对象内属性是在对象创建时就固定分配的,空间有限。在我的实验条件下,对象内属性的数量固定为十个,且这十个空间大小相同(可以理解为十个指针)。当对象内属性放满之后,会以快属性的方式,在 properties 下按创建顺序存放。相较于对象内属性,快属性需要额外多一次 properties 的寻址时间,之后便是与对象内属性一致的线性查找。
慢属性
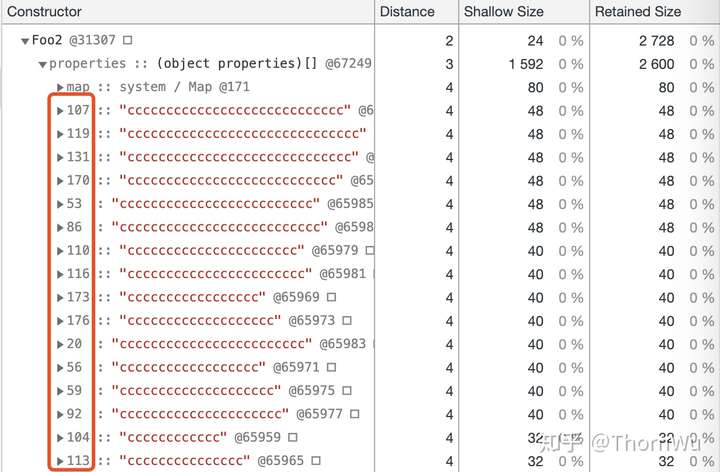
接着我们来看看 c。这个实在是太长了,只截取了一部分。可以看到,和 b (快属性)相比,properties 中的索引变成了毫无规律的数,意味着这个对象已经变成了哈希存取结构了。
所以,问题来了,为什么要分这么几种存储方式呢?我来说说我的理解。
为什么要分三种存储方式?(个人理解)
这其实是在公司内部分享的时候,有同学提出的问题。我相信大家读到这里的时候也会有类似的疑惑。当时的我也并不能很好的解释为什么,直到我看到一张哈希存储的图(图片来自于网络)。
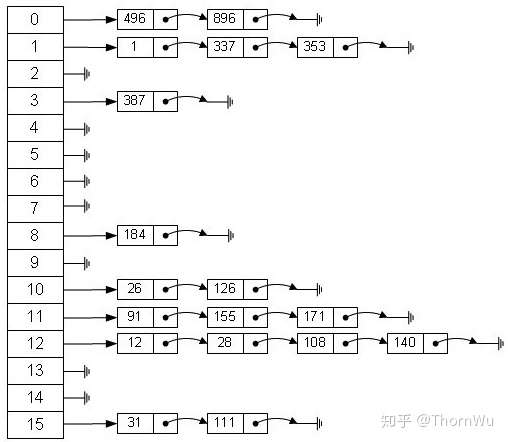
在 V8 里,一切看似匪夷所思的优化,最根本的原因就是为了更快。—— 本人
可以这么看,早期的 JS 引擎都是用慢属性存储,前两者都是出于优化这个存储方式而出现的。
我们知道,所有的数据在底层都会表示为二进制。我们又知道,如果程序逻辑只涉及二进制的位运算(包含与、或、非),速度是最快的。下面我们忽略寻址的等方面的耗时,单纯从计算的次数来比较这三种(两类)方式。
对象内属性和快属性做的事情很简单,线性查找每一个位置是不是指定的位置,这部分的耗时可以理解为至多 N 次简单位运算(N 为属性的总数)的耗时。而慢属性需要先经过哈希算法计算。这是一个复杂运算,时间上若干倍于简单位运算。另外,哈希表是个二维空间,所以通过哈希算法计算出其中一维的坐标后,在另一维上仍需要线性查找。所以,当属性非常少的时候为什么不用慢属性应该就不难理解了吧。
附上一段 V8 中字符串的哈希算法,其中光是左移和右移就有 60 次(60 次简单位运算)。
// V8 中字符串的哈希值生成器
uint32_t StringHasher::GetHashCore(uint32_t running_hash) {
running_hash += (running_hash << 3);
running_hash ^= (running_hash >> 11);
running_hash += (running_hash << 15);
int32_t hash = static_cast<int32_t>(running_hash & String::kHashBitMask);
int32_t mask = (hash - 1) >> 31;
return running_hash | (kZeroHash & mask);
}那为什么不一直用对象内属性或快属性呢?
这是因为属性太多的时候,这两种方式可能就没有慢属性快了。假设哈希运算的代价为 60 次简单位运算,哈希算法的表现良好。如果只用对象内属性或快属性的方式存,当我需要访问第 120 个属性,就需要 120 次简单位运算。而使用慢属性,我们需要一次哈希计算(60 次简单位运算)+ 第二维的线性比较(远小于 60 次,已假设哈希算法表现良好,那属性在哈希表中是均匀分布的)。
单方面友情推荐程序员小灰的《漫画:什么是HashMap?》
隐藏类
上面提到的描述命名属性是怎么存放的,也就是 “按图索骥” 中的 “图”,在 V8 中被称为 Map,更出名的称呼是隐藏类(Hidden Class)。
在 SpiderMonkey (火狐引擎)中,类似的设计被称为 Shape。
为什么要引入隐藏类?
首先当然是更快。
JavaScript 是一门动态编程语言,它允许开发者使用非常灵活的方式定义对象。对象可以在运行时改变类型,添加或删除属性。相比之下,像 Java 这样的静态语言,类型一旦创建变不可更改,属性可以通过固定的偏移量进行访问。
前面也提到,通过哈希表的方式存取属性,需要额外的哈希计算。为了提高对象属性的访问速度,实现对象属性的快速存取,V8 中引入了隐藏类。
隐藏类引入的另外一个意义,在于大大节省了内存空间。
在 ECMAScript 中,对象属性的 Attribute 被描述为以下结构。 - [[Value]]:属性的值 - [[Writable]]:定义属性是否可写(即是否能被重新分配) - [[Enumerable]]:定义属性是否可枚举 - [[Configurable]]:定义属性是否可配置(删除)
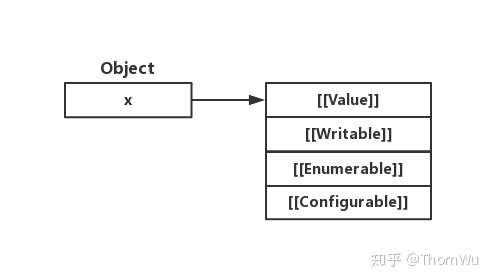
隐藏类的引入,将属性的 Value 与其它 Attribute 分开。一般情况下,对象的 Value 是经常会发生变动的,而 Attribute 是几乎不怎么会变的。那么,我们为什么要重复描述几乎不会改变的 Attribute 呢?显然这是一种内存浪费。
隐藏类的创建
对象创建过程中,每添加一个命名属性,都会对应一个生成一个新的隐藏类。在 V8 的底层实现了一个将隐藏类连接起来的转换树,如果以相同的顺序添加相同的属性,转换树会保证最后得到相同的隐藏类。
下面的例子中,a 在空对象时、添加 name 属性后、添加 text 属性后会分别对应不同的隐藏类。
// 实验3 隐藏类的创建
let a = {}
a.name = 'thorn1'
a.text = 'thorn2'下面是创建过程的示意图(仅描述过程,具体细节可能与实际实现有略微差异)。
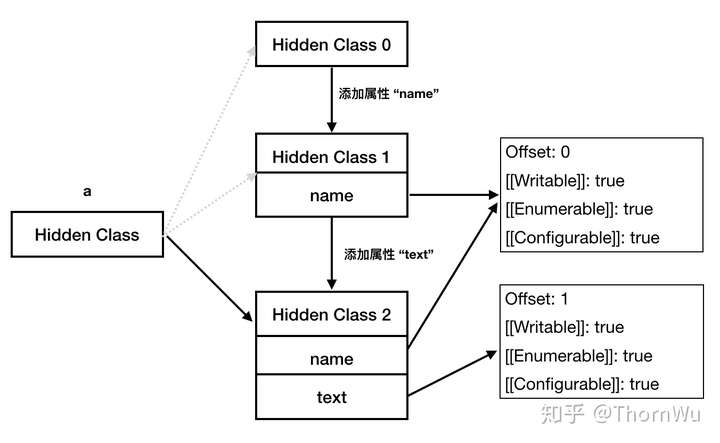
通过内存快照,我们也可以看到,Hidden Class 1 和 Hidden Class2 是不同的,并且后者的 back_pointer 指针指向前者,这也证实了上图中的流程分析。
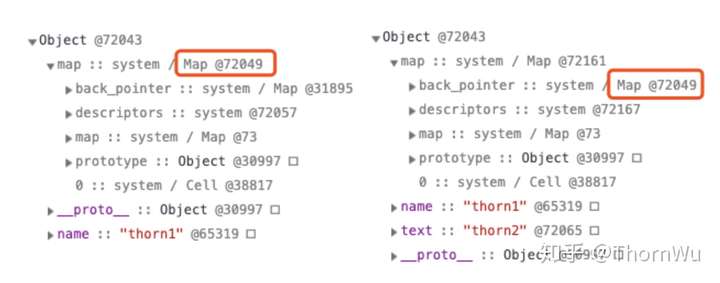
有的文章中提到,在实际存储中,每次添加属性时,新创建隐藏类实际上只会描述这个新添加的属性,而不会描述所有属性,也就是 Hidden Class 2 中实际上只会描述text,没有name。这点本人暂时没有通过内存快照的方式验证(流下了没有技术的眼泪),但从逻辑上分析应该是这样的。
此处还有一个小小的知识点。
// 实验4 隐藏类创建时的优化
let a = {};
a.name = 'thorn1'
let b = { name: 'thorn2' }
a 和 b 的区别是,a 首先创建一个空对象,然后给这个对象新增一个命名属性 name。而 b 中直接创建了一个含有命名属性 name 的对象。从内存快照我们可以看到,a 和 b 的隐藏类不一样,back_pointer 也不一样。这主要是因为,在创建 b 的隐藏类时,省略了为空对象单独创建隐藏类的一步。所以,要生成相同的隐藏类,更为准确的描述是 —— 从相同的起点,以相同的顺序,添加结构相同的属性(除 Value 外,属性的 Attribute 一致)。
如果对隐藏类的创建特别特别感兴趣,单方面友情推荐知乎 @hijiangtao 的译作《JavaScript 引擎基础:Shapes 和 Inline Caches》。
神奇的 delete 操作
上面我们讨论了增加属性对隐藏类的影响,下面我们来看看一下删除操作对于隐藏类的影响。
// 实验5 delete 操作的影响
function Foo5 () {}
var a = new Foo5()
var b = new Foo5()
for (var i = 1; i < 8; i ++) {
a[new Array(i+1).join('a')] = 'aaa'
b[new Array(i+1).join('b')] = 'bbb'
}
delete a.a

按照我们之前试验的,a 和 b 本身都是对象内属性。从快照可以看到,删除了 a.a 后,a 变成了慢属性,退回哈希存储。
但是,如果我们按照添加属性的顺序逆向删除属性,情况会有所不同。
// 实验6 按添加顺序删除属性
function Foo6 () {}
var a = new Foo6()
var b = new Foo6()
a.name = 'aaa'
a.color= 'aaa'
a.text = 'aaa'
b.name = 'bbb'
b.color = 'bbb'
delete a.text
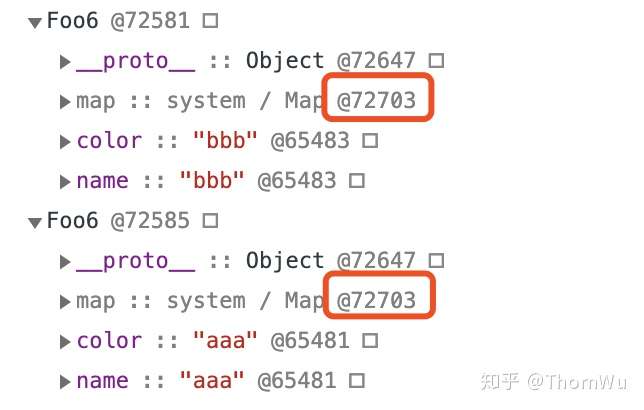
我们给 a 和 b 按相同属性添加相同的属性 name 和 color,再给 a 额外添加一个属性 text,然后删除这个属性。可以发现,此时 a 和 b 的隐藏类相同,a 也没有退回哈希存储。
结论与启示
- 属性分为命名属性和可索引属性,命名属性存放在
Properties中,可索引属性存放在Elements中。 - 命名属性有三种不同的存储方式:对象内属性、快属性和慢属性,前两者通过线性查找进行访问,慢属性通过哈希存储的方式进行访问。
- 总是以相同的顺序初始化对象成员,能充分利用相同的隐藏类,进而提高性能。
- 增加或删除可索引属性,不会引起隐藏类的变化,稀疏的可索引属性会退化为哈希存储。
- delete 操作可能会改变对象的结构,导致引擎将对象的存储方式降级为哈希表存储的方式,不利于 V8 的优化,应尽可能避免使用(当沿着属性添加的反方向删除属性时,对象不会退化为哈希存储)。
相关链接
参考资料
V8 是怎么跑起来的 —— V8 中的对象表示V8 是怎么跑起来的 —— V8 中的对象表示ThornWuThornWuThe best is yet to come30 人赞同了该文章本文创作于 2019-04-30,2019-12-20 迁移至此本文基于 Chrome 73 进行测试。前言V8,可能是前端开发人员熟悉而又陌生的领域。
当你看到这篇文章时,它已经迭代了三版了。目的只有一个,在保证尽可能准确的前提下,用更直观的方式呈现出来,让大家更加容易接受。本文不需要太多的预备知识,只需要你对 JavaScript 对象有基本的了解。
为了让文章不那么枯燥,也为了证实观点的准确性,文章中包含了很多的小实验,大家可以在控制台中尽情把玩。
预备知识 —— 在 Chrome 中查看内存快照首先我们在控制台运行这样一段程序。
function Food(name, type) { this.name = name; this.type = type;}var beef = new Food('beef', 'meat');切换到 Memory 中,点击左侧的小圈圈就可以捕获当前的内存快照。
通过构造函数创建对象,主要是为了更方便地在快照中找到它。点开快照后,在过滤器中输入 Food 就可以找到由 Food 构造的所有对象了,神奇吧。
V8 中对象的结构在 V8 中,对象主要由三个指针构成,分别是隐藏类(Hidden Class),Property 还有 Element。
其中,隐藏类用于描述对象的结构。Property 和 Element 用于存放对象的属性,它们的区别主要体现在键名能否被索引。
Property 与 Element// 可索引属性会被存储到 Elements 指针指向的区域{ 1: "a", 2: "b" }
// 命名属性会被存储到 Properties 指针指向的区域{ "first": 1, "second": 2 }事实上,这是为了满足 ECMA 规范 要求所进行的设计。按照规范中的描述,可索引的属性应该按照索引值大小升序排列,而命名属性根据创建的顺序升序排列。
我们来做个简单的小实验。
var a = { 1: "a", 2: "b", "first": 1, 3: "c", "second": 2 }
var b = { "second": 2, 1: "a", 3: "c", 2: "b", "first": 1 }
console.log(a) // { 1: "a", 2: "b", 3: "c", first: 1, second: 2 }
console.log(b)// { 1: "a", 2: "b", 3: "c", second: 2, first: 1 }a 和 b 的区别在于 a 以一个可索引属性开头,b 以一个命名属性开头。在 a 中,可索引属性升序排列,命名属性先有 first 后有 second。在 b 中,可索引属性乱序排列,命名属性先有 second 后有 first。
可以看到
索引的属性按照索引值大小升序排列,而命名属性根据创建的顺序升序排列。在同时使用可索引属性和命名属性的情况下,控制台打印的结果中,两种不同属性之间存在的明显分隔。无论是可索引属性还是命名属性先声明,在控制台中总是以相同的顺序出现(在我的浏览器中,可索引属性总是先出现)。这两点都可以从侧面印证这两种属性是分开存储的。
侧面印证完了,我们来看看正面。我们用预备知识中的方法,查看这两种属性的快照。
// 实验1 可索引属性和命名属性的存放function Foo1 () {}var a = new Foo1()var b = new Foo1()
a.name = 'aaa'a.text = 'aaa'b.name = 'bbb'b.text = 'bbb'
a[1] = 'aaa'a[2] = 'aaa'
a、b 都有命名属性 name 和 text,此外 a 还额外多了两个可索引属性。从快照中可以明显的看到,可索引属性是存放在 Elements 中的,此外,a 和 b 具有相同的结构(这个结构会在下文中介绍)。
你可能会有点好奇,这两个对象的属性不一样,怎么会有相同的结构呢?要理解这个问题,首先可以问自己三个问题。
为什么要把对象存起来?当然是为了之后要用呀。要用的时候需要做什么?找到这个属性咯。描述结构是为了做什么呢?按图索骥,方便查找呀。那么,对于可索引属性来说,它本身已经是有序地进行排列了,我们为什么还要多次一举通过它的结构去查找呢。既然不用通过它的结构查找,那么我们也不需要再去描述它的结构了是吧。这样,应该就不难理解为什么 a 和 b 具有相同的结构了,因为它们的结构中只描述了它们都具有 name 和 text 这样的情况。
当然,这也是有例外的。我们在上面的代码中再加入一行。
a[1111] = 'aaa'
可以看到,此时隐藏类发生了变化,Element 中的数据存放也变得没有规律了。这是因为,当我们添加了 a[1111] 之后,数组会变成稀疏数组。为了节省空间,稀疏数组会转换为哈希存储的方式,而不再是用一个完整的数组描述这块空间的存储。所以,这几个可索引属性也不能再直接通过它的索引值计算得出内存的偏移量。至于隐藏类发生变化,可能是为了描述 Element 的结构发生改变(这个图片可以与下文中慢属性的配图进行比较,可以看到 Foo1 的 Property 并没有退化为哈希存储,只是 Element 退化为哈希存储导致隐藏类发生改变)。
命名属性的不同存储方式V8 中命名属性有三种的不同存储方式:对象内属性(in-object)、快属性(fast)和慢属性(slow)。
对象内属性保存在对象本身,提供最快的访问速度。快属性比对象内属性多了一次寻址时间。慢属性与前面的两种属性相比,会将属性的完整结构存储(另外两种属性的结构会在隐藏类中描述,隐藏类将在下文说明),速度最慢(在下文或其它相关文章中,慢属性、属性字典、哈希存储说的都是一回事)。这样是不是有点抽象。别急,我们通过一个例子来说明。
// 实验2 三种不同类型的 Property 存储模式function Foo2() {}
var a = new Foo2()var b = new Foo2()var c = new Foo2()
for (var i = 0; i < 10; i ++) { a[new Array(i+2).join('a')] = 'aaa'}
for (var i = 0; i < 12; i ++) { b[new Array(i+2).join('b')] = 'bbb'}
for (var i = 0; i < 30; i ++) { c[new Array(i+2).join('c')] = 'ccc'}a、b 和 c 分别拥有 10 个,12 个和 30 个属性,在目前的 Chrome 73 版本中,分别会以对象内属性、对象内属性 + 快属性、慢属性三种方式存储。这块的运行快照有点长,我们分别看一看。
对象内属性和快属性
首先我们看一下 a 和 b。从某种程度上讲,对象内属性和快属性实际上是一致的。只不过,对象内属性是在对象创建时就固定分配的,空间有限。在我的实验条件下,对象内属性的数量固定为十个,且这十个空间大小相同(可以理解为十个指针)。当对象内属性放满之后,会以快属性的方式,在 properties 下按创建顺序存放。相较于对象内属性,快属性需要额外多一次 properties 的寻址时间,之后便是与对象内属性一致的线性查找。
慢属性
接着我们来看看 c。这个实在是太长了,只截取了一部分。可以看到,和 b (快属性)相比,properties 中的索引变成了毫无规律的数,意味着这个对象已经变成了哈希存取结构了。
所以,问题来了,为什么要分这么几种存储方式呢?我来说说我的理解。
为什么要分三种存储方式?(个人理解)这其实是在公司内部分享的时候,有同学提出的问题。我相信大家读到这里的时候也会有类似的疑惑。当时的我也并不能很好的解释为什么,直到我看到一张哈希存储的图(图片来自于网络)。
在 V8 里,一切看似匪夷所思的优化,最根本的原因就是为了更快。—— 本人可以这么看,早期的 JS 引擎都是用慢属性存储,前两者都是出于优化这个存储方式而出现的。
我们知道,所有的数据在底层都会表示为二进制。我们又知道,如果程序逻辑只涉及二进制的位运算(包含与、或、非),速度是最快的。下面我们忽略寻址的等方面的耗时,单纯从计算的次数来比较这三种(两类)方式。
对象内属性和快属性做的事情很简单,线性查找每一个位置是不是指定的位置,这部分的耗时可以理解为至多 N 次简单位运算(N 为属性的总数)的耗时。而慢属性需要先经过哈希算法计算。这是一个复杂运算,时间上若干倍于简单位运算。另外,哈希表是个二维空间,所以通过哈希算法计算出其中一维的坐标后,在另一维上仍需要线性查找。所以,当属性非常少的时候为什么不用慢属性应该就不难理解了吧。
附上一段 V8 中字符串的哈希算法,其中光是左移和右移就有 60 次(60 次简单位运算)。
// V8 中字符串的哈希值生成器uint32_t StringHasher::GetHashCore(uint32_t running_hash) { running_hash += (running_hash << 3); running_hash ^= (running_hash >> 11); running_hash += (running_hash << 15); int32_t hash = static_cast<int32_t>(running_hash & String::kHashBitMask); int32_t mask = (hash - 1) >> 31; return running_hash | (kZeroHash & mask);}那为什么不一直用对象内属性或快属性呢?
这是因为属性太多的时候,这两种方式可能就没有慢属性快了。假设哈希运算的代价为 60 次简单位运算,哈希算法的表现良好。如果只用对象内属性或快属性的方式存,当我需要访问第 120 个属性,就需要 120 次简单位运算。而使用慢属性,我们需要一次哈希计算(60 次简单位运算)+ 第二维的线性比较(远小于 60 次,已假设哈希算法表现良好,那属性在哈希表中是均匀分布的)。
单方面友情推荐程序员小灰的《漫画:什么是HashMap?》
隐藏类上面提到的描述命名属性是怎么存放的,也就是 “按图索骥” 中的 “图”,在 V8 中被称为 Map,更出名的称呼是隐藏类(Hidden Class)。
在 SpiderMonkey (火狐引擎)中,类似的设计被称为 Shape。为什么要引入隐藏类?首先当然是更快。
JavaScript 是一门动态编程语言,它允许开发者使用非常灵活的方式定义对象。对象可以在运行时改变类型,添加或删除属性。相比之下,像 Java 这样的静态语言,类型一旦创建变不可更改,属性可以通过固定的偏移量进行访问。
前面也提到,通过哈希表的方式存取属性,需要额外的哈希计算。为了提高对象属性的访问速度,实现对象属性的快速存取,V8 中引入了隐藏类。
隐藏类引入的另外一个意义,在于大大节省了内存空间。
在 ECMAScript 中,对象属性的 Attribute 被描述为以下结构。 - [[Value]]:属性的值 - [[Writable]]:定义属性是否可写(即是否能被重新分配) - [[Enumerable]]:定义属性是否可枚举 - [[Configurable]]:定义属性是否可配置(删除)
隐藏类的引入,将属性的 Value 与其它 Attribute 分开。一般情况下,对象的 Value 是经常会发生变动的,而 Attribute 是几乎不怎么会变的。那么,我们为什么要重复描述几乎不会改变的 Attribute 呢?显然这是一种内存浪费。
隐藏类的创建对象创建过程中,每添加一个命名属性,都会对应一个生成一个新的隐藏类。在 V8 的底层实现了一个将隐藏类连接起来的转换树,如果以相同的顺序添加相同的属性,转换树会保证最后得到相同的隐藏类。
下面的例子中,a 在空对象时、添加 name 属性后、添加 text 属性后会分别对应不同的隐藏类。
// 实验3 隐藏类的创建let a = {}a.name = 'thorn1'a.text = 'thorn2'下面是创建过程的示意图(仅描述过程,具体细节可能与实际实现有略微差异)。
通过内存快照,我们也可以看到,Hidden Class 1 和 Hidden Class2 是不同的,并且后者的 back_pointer 指针指向前者,这也证实了上图中的流程分析。
有的文章中提到,在实际存储中,每次添加属性时,新创建隐藏类实际上只会描述这个新添加的属性,而不会描述所有属性,也就是 Hidden Class 2 中实际上只会描述 text,没有 name。这点本人暂时没有通过内存快照的方式验证(流下了没有技术的眼泪),但从逻辑上分析应该是这样的。此处还有一个小小的知识点。
// 实验4 隐藏类创建时的优化let a = {};a.name = 'thorn1'let b = { name: 'thorn2' }
a 和 b 的区别是,a 首先创建一个空对象,然后给这个对象新增一个命名属性 name。而 b 中直接创建了一个含有命名属性 name 的对象。从内存快照我们可以看到,a 和 b 的隐藏类不一样,back_pointer 也不一样。这主要是因为,在创建 b 的隐藏类时,省略了为空对象单独创建隐藏类的一步。所以,要生成相同的隐藏类,更为准确的描述是 —— 从相同的起点,以相同的顺序,添加结构相同的属性(除 Value 外,属性的 Attribute 一致)。
如果对隐藏类的创建特别特别感兴趣,单方面友情推荐知乎 @hijiangtao 的译作《JavaScript 引擎基础:Shapes 和 Inline Caches》。
神奇的 delete 操作上面我们讨论了增加属性对隐藏类的影响,下面我们来看看一下删除操作对于隐藏类的影响。
// 实验5 delete 操作的影响function Foo5 () {}var a = new Foo5()var b = new Foo5()
for (var i = 1; i < 8; i ++) { a[new Array(i+1).join('a')] = 'aaa' b[new Array(i+1).join('b')] = 'bbb'}
delete a.a
按照我们之前试验的,a 和 b 本身都是对象内属性。从快照可以看到,删除了 a.a 后,a 变成了慢属性,退回哈希存储。
但是,如果我们按照添加属性的顺序逆向删除属性,情况会有所不同。
// 实验6 按添加顺序删除属性function Foo6 () {}var a = new Foo6()var b = new Foo6()
a.name = 'aaa'a.color= 'aaa'a.text = 'aaa'
b.name = 'bbb'b.color = 'bbb'
delete a.text
我们给 a 和 b 按相同属性添加相同的属性 name 和 color,再给 a 额外添加一个属性 text,然后删除这个属性。可以发现,此时 a 和 b 的隐藏类相同,a 也没有退回哈希存储。
结论与启示属性分为命名属性和可索引属性,命名属性存放在 Properties 中,可索引属性存放在 Elements 中。命名属性有三种不同的存储方式:对象内属性、快属性和慢属性,前两者通过线性查找进行访问,慢属性通过哈希存储的方式进行访问。总是以相同的顺序初始化对象成员,能充分利用相同的隐藏类,进而提高性能。增加或删除可索引属性,不会引起隐藏类的变化,稀疏的可索引属性会退化为哈希存储。delete 操作可能会改变对象的结构,导致引擎将对象的存储方式降级为哈希表存储的方式,不利于 V8 的优化,应尽可能避免使用(当沿着属性添加的反方向删除属性时,对象不会退化为哈希存储)。相关链接参考资料V8之旅:对象表示JavaScript 引擎基础:Shapes 和 Inline Caches - 知乎V8 Hidden Class - w3ctechV8 Hidden class - LINE ENGINEERINGHidden classes in JavaScript and Inline CachingFast properties in V8 · V8发布于 2019-12-20