一、REDIS_INCODING_HT (dict字典,hashtable)
dict是一个用于维护key和value映射关系的数据结构。redis的一个database中所有的key到value的映射,就是使用一个dict来维护的。不过,他在redis被使用的地方还很多,比如,一个redis hash结构,当它的field较多的时候,便会采用dict来存储。再比如,redis配合使用dict和skiplist来共同维护一个zset。
在redis中,dict也是一个基于哈希表的算法。和传统的哈希算法类似,它采用某个哈希函数从key计算得到哈希表中的位置,用拉链发解决冲突,并在元素数量超过装载因子的时候rehash。redis的hash表最显著的一个特点,就在于它哈希表的重哈希,采用了一种增量式重哈希的方法,可以避免在需要扩容时一次性对所有hash表中元素重哈希,导致正常iud操作阻塞。
dict的数据结构
typedef struct dictEntry {
void *key;
union {
void *val;
uint64_t u64;
int64_t s64;
double d;
} v;
struct dictEntry *next;
} dictEntry;
typedef struct dictType {
unsigned int (*hashFunction)(const void *key);
void *(*keyDup)(void *privdata, const void *key);
void *(*valDup)(void *privdata, const void *obj);
int (*keyCompare)(void *privdata, const void *key1, const void *key2);
void (*keyDestructor)(void *privdata, void *key);
void (*valDestructor)(void *privdata, void *obj);
} dictType;
/* This is our hash table structure. Every dictionary has two of this as we
* implement incremental rehashing, for the old to the new table. */
typedef struct dictht {
dictEntry **table;
unsigned long size;
unsigned long sizemask;
unsigned long used;
} dictht;
typedef struct dict {
dictType *type;
void *privdata;
dictht ht[2];
long rehashidx; /* rehashing not in progress if rehashidx == -1 */
int iterators; /* number of iterators currently running */
} dict;
具体结构图如下
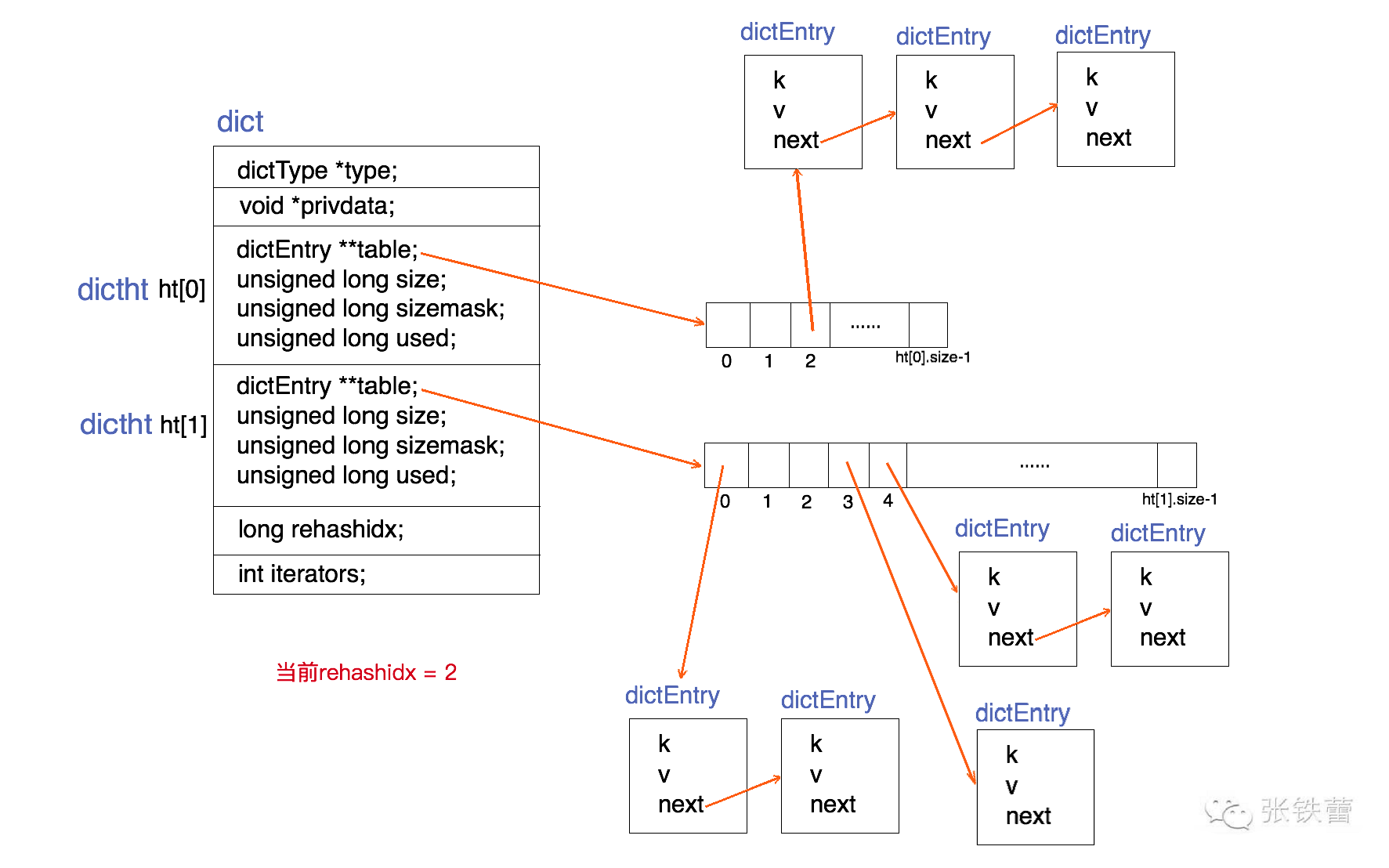
dict
- dictType* type 一个指向dictType 结构的指针。表示key和value存储何种数据类型的数据
- void* privdata 私有数据指针,由调用者在创建dict的时候传入。
- dictht ht[1] 两个hash表(dictht)。只有在rehash的过程中,ht[1]才有效,平常情况下 只有ht[0]生效。上图就是表示rehash进行到中间某一步的情况。
- long rehashidx 重哈希(rehash)索引,当没在重hash时 rehashidx =-1 否则表示正在rehash
- int iterators
dictType 包含若干函数指针,用于对dict设计的key和value的各种操作进行自定义
- hashFunction 对key进行hash的算法
- keyDup和valDup key和value的拷贝函数,深拷贝。
- keyCompare 定义两个key的比较操作
- keyDestructor 和 valDestructor key和value的析构函数
dictht 表示一个哈希表的结构
- 一个dictEntry数组,保存key和value,key的hash值映射到某个位置上,当冲突时,链表解决冲突。
- size 表示dictEntry数组的长度 总是2^x
- sizemask =size-1 取模时(hashcode&sizemask超快)
- used 记录dictht中现有的数据个数,当过大时冲突会变高,超过size*load factor,会rehash。
dictEntry 表示一个key-value对
- key 保存键的指针,通常指向一个sds
- v(value) 是一个union 当它的值是uint64_t/int64_t/double时可以直接存储,不需要额外内存,当然也可以是void* 以便保存任何类型的数据。
增量式哈希
static void _dictRehashStep(dict *d) {
if (d->iterators == 0) dictRehash(d,1);
}
int dictRehash(dict *d, int n) {
int empty_visits = n*10; /* Max number of empty buckets to visit. */
if (!dictIsRehashing(d)) return 0;
while(n-- && d->ht[0].used != 0) {
dictEntry *de, *nextde;
/* Note that rehashidx can't overflow as we are sure there are more
* elements because ht[0].used != 0 */
assert(d->ht[0].size > (unsigned long)d->rehashidx);
while(d->ht[0].table[d->rehashidx] == NULL) {
d->rehashidx++;
if (--empty_visits == 0) return 1;
}
de = d->ht[0].table[d->rehashidx];
/* Move all the keys in this bucket from the old to the new hash HT */
while(de) {
unsigned int h;
nextde = de->next;
/* Get the index in the new hash table */
h = dictHashKey(d, de->key) & d->ht[1].sizemask;
de->next = d->ht[1].table[h];
d->ht[1].table[h] = de;
d->ht[0].used--;
d->ht[1].used++;
de = nextde;
}
d->ht[0].table[d->rehashidx] = NULL;
d->rehashidx++;
}
/* Check if we already rehashed the whole table... */
if (d->ht[0].used == 0) {
zfree(d->ht[0].table);
d->ht[0] = d->ht[1];
_dictReset(&d->ht[1]);
d->rehashidx = -1;
return 0;
}
/* More to rehash... */
return 1;
}
上文说道,渐进性rehash不是一次性完成的,是穿插在每次对于hash操作的时候,渐进的完成的。
1.为ht[1] 分配空间,让字典同时持有ht[0] ht[1]两个hash表
2.在dict中把rehashidx设置为0,表示下一个rehash操作ht[0]->table[0],rehash工作开始。
3.在rehash进行期间,每次对hash执行crud操作时,程序除了执行指定的操作前,要先调用_dictRehashStep(dict *d) 执行单次rehash。
4.dictRehash传入的n表示每次rehash一个桶(有元素的桶,当没有元素时,最多遍历10*n个),当找到一个非空桶时,开始把桶中的链表拆分成两半,分别存入ht[1]->table[]的两个位置(取决于更高一个bit的值),然后把rehashidx的值更新(其实是在遍历桶的时候更新的) 返回1 表示还需rehash。
5.随着rehash的不断操作,最终在某个操作后,rehash完成,rehashidx设置为-1,返回 0.
在rehash期间 delete find update 会在ht[0]和ht[1]中都进行查找,add的操作只会添加到ht[1]中。
二、REDIS_ENCODING_SKIPLIST 跳表
redis里面是用skiplist是为了实现zset这种对外的数据结构。zset提供的操作非常丰富,可以满足许多业务场景,同时也意味着zset相对来说实现比较复杂。
skiplist数据结构简介

如图,跳表的底层是一个顺序链表,每隔一个节点有一个上层的指针指向下下一个节点,并层层向上递归。这样设计成类似树形的结构,可以使得对于链表的查找可以到达二分查找的时间复杂度。
按照上面的生成跳表的方式上面每一层节点的个数是下层节点个数的一半,这种方式在插入数据的时候有很大的问题。就是插入一个新节点会打乱上下相邻两层链表节点个数严格的2:1的对应关系。如果要维持这种严格对应关系,就必须重新调整整个跳表,这会让插入/删除的时间复杂度重新退化为O(n)。
为了解决这一问题,skiplist他不要求上下两层链表之间个数的严格对应关系,他为每个节点随机出一个层数。比如,一个节点的随机出的层数是3,那么就把它插入到三层的空间上,如下图。
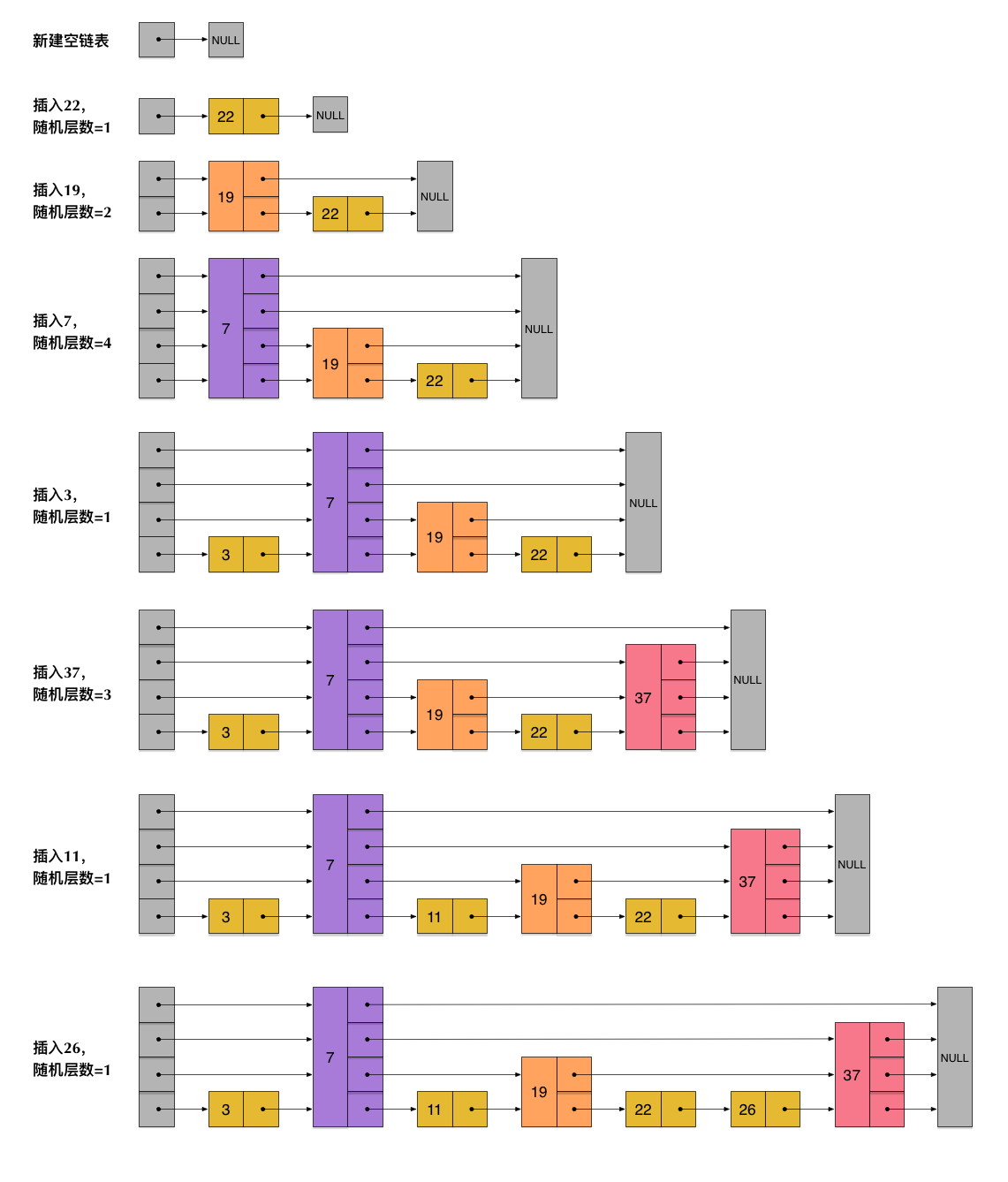
那么,这就产生了一个问题,每次插入节点时随机出一个层数,真的能保证跳表良好的性能能么,
首先跳表随机数的产生,不是一次执行就产生的,他有自己严格的计算过程,
1首先每个节点都有最下层(第1层)指针
2如果一个节点有第i层指针,那么他有第i层指针的概率为p。
3节点的最大层数不超过MaxLevel
我们注意到,每个节点的插入过程都是随机的,他不依赖于其他节点的情况,即skiplist形成的结构和节点插入的顺序无关。
这样形成的skiplist查找的时间复杂度约为O(log n)。
redis中的skiplist
- 当数据较少的时候,zset是由一个ziplist来实现的
- 当数据较多的时候,zset是一个由dict 和一个 skiplist来实现的,dict用来查询数据到分数的对应关系,而skiplist用来根据分数查询数据。
为了支持排名rank查询,redis中对skiplist做了扩展,使得根据排名能够快速查到数据,或者根据分数查到数据之后容易获得排名,二者都是O(log n)。
typedef struct zset{
//跳跃表
zskiplist *zsl;
//字典
dict *dice;
} zset;
dict的key保存元素的值,字典的value保存元素的score,跳表节点的robj保存元素的成员,节点的score保存对应score。并且会通过指针来共享元素相同的robj和score。
skiplist的数据结构定义
//server.h
#define ZSKIPLIST_MAXLEVEL 32 #define ZSKIPLIST_P 0.25 typedef struct zskiplistNode { robj *obj; double score; struct zskiplistNode *backward; struct zskiplistLevel { struct zskiplistNode *forward; unsigned int span; } level[]; } zskiplistNode; typedef struct zskiplist { struct zskiplistNode *header, *tail; unsigned long length; int level; } zskiplist;
开头定义了两个常量 ZSKIPLIST_MAXLEVEL和ZSKIPLIST_P,即上文所提到的p和maxlevel。
zskiplistNode表示skiplist的节点结构
- obj字段存放节点数据,存放string robj。
- score字段对应的是节点的分数。
- backward字段是指向前一个节点的指针,节点只有一个向前指针,最底层是一个双向链表。
- level[]存放各层链表的向后指针结构,包含一个forward ,指向对应层后一个节点;span字段指的是这层的指针跨越了多少个节点值,用于计算排名。(level是一个柔性数组,因此他占用的内存不在zskiplistNode里,也需要单独为其分配内存。)
zskiplist 定义了skiplist的外观,包含
- header和tail指针
- 链表长度 length
- level表示 跳表的最大层数
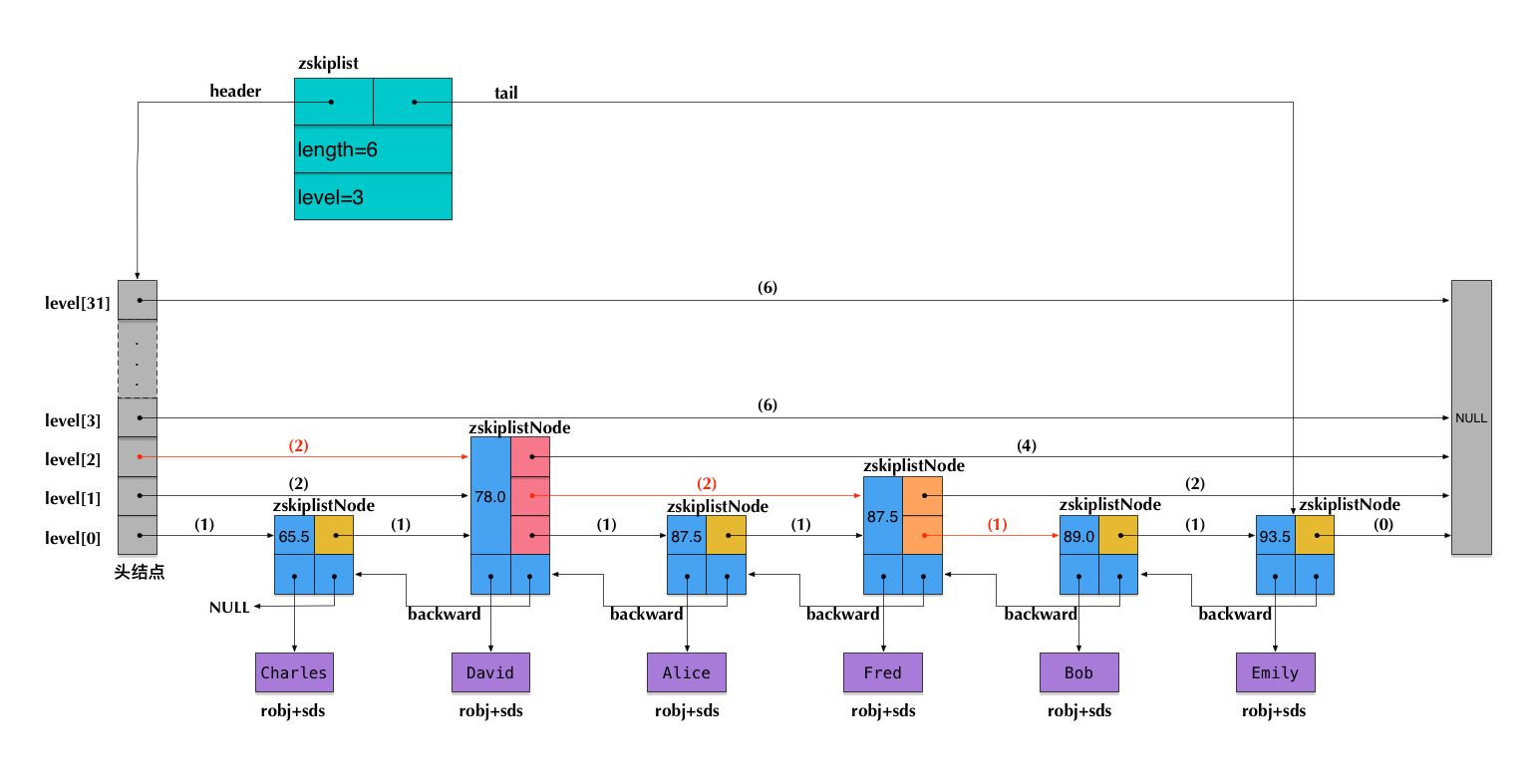
上图就是redis中一个skiplist可能的结构,括号中的数字代表 level数组中span的值,即跨越了多少个节点。
假设我们在这个skiplist中查找score=89的元素,在查找路径上,我们只需要吧所有的level指针对应的span值求和,就可以得到对应的排名;相反,如果查找排名的时候,只需要不断累加span保证他不超过指定的值就可以求得对应的节点元素。
三、REDIS_ENCODING_INTSET
redis中使用intset实现数量较少数字的set。
set-max-intset-entries 512
实际上 intset是一个由整数组成的有序集合,为了快速查找元素,数组是有序的,用二分查找判断一个元素是否在这个结合上。在内存分配上与ziplist类似,用一块连续的内存保存数组元素,并且对于大整数和小证书 采用了不同的编码。
结构如下
//intset.h
typedef struct intset {
uint32_t encoding;
uint32_t length;
int8_t contents[];
} intset;
#define INTSET_ENC_INT16 (sizeof(int16_t))
#define INTSET_ENC_INT32 (sizeof(int32_t))
#define INTSET_ENC_INT64 (sizeof(int64_t))
encoding 数据编码 表示intset中的每个元素用几个字节存储。(INTSET_ENC_INT16 用两个字节存储,即两个contents数组位置 INTSET_ENC_INT32表示4个字节 INTSET_ENC_INT64表示8个字节)
length 表示inset中元素的个数
contents 柔性数组,表示存储的实际数据,数组长度 = encoding * length。
另外,intset可能会随着数据的添加改编他的编码,最开始创建的inset使用 INTSET_ENC_INT16编码。

如上图 intset采用小端存储。
关于插入逻辑。
intset *intsetAdd(intset *is, int64_t value, uint8_t *success) {
uint8_t valenc = _intsetValueEncoding(value);
uint32_t pos;
if (success) *success = 1;
/* Upgrade encoding if necessary. If we need to upgrade, we know that
* this value should be either appended (if > 0) or prepended (if < 0),
* because it lies outside the range of existing values. */
if (valenc > intrev32ifbe(is->encoding)) {
/* This always succeeds, so we don't need to curry *success. */
return intsetUpgradeAndAdd(is,value);
} else {
/* Abort if the value is already present in the set.
* This call will populate "pos" with the right position to insert
* the value when it cannot be found. */
if (intsetSearch(is,value,&pos)) {
if (success) *success = 0;
return is;
}
is = intsetResize(is,intrev32ifbe(is->length)+1);
if (pos < intrev32ifbe(is->length)) intsetMoveTail(is,pos,pos+1);
}
_intsetSet(is,pos,value);
is->length = intrev32ifbe(intrev32ifbe(is->length)+1);
return is;
}
intsetadd在intset中添加新元素value。如果value在添加前已经存在,则不会重复添加,这个时候success设置值为0
如果要添加的元素编码比当前intset的编码大。调用intsetUpgradeAndAdd将intset的编码进行增长,然后插入。
调用intsetSearch 如果能查找到,不会重复添加。没查到调用intsetResize对其进行扩容(realloc),同时intsetMoveTail将带插入位置后面的元素统一向后移动一个位置。返回值是一个新的intset指针,替换原来的intset指针,总的时间复杂度为O(n)。