本文要介绍的是SSE4.1指令集中的几条整数指令及其在视频编码中的应用。
1. 单指令32字节差分绝对值求和指令 MPSADBW
这条指令类似于SSE的PSADBW,但它实现的功能更强大。包括微软官方网站上对这条指令的说明都不是能够让人一目了然。下面这张图也许可以帮助我们理解:
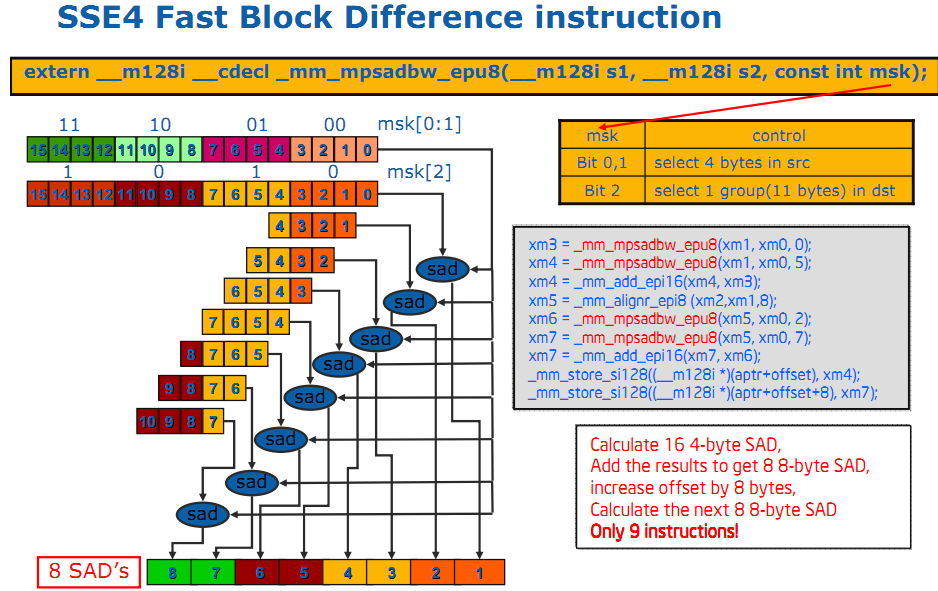
这条指令的灵活之处在于源操作数和目的操作数的位置都是可选的。如何选择关键在于后面那个mask常量。这个常量是一个立即数,但只用到了其中的低三位。
其中,最低2位,用于选择源操作数的连续4个字节的起始位置。由于两位二进制有4中状态,所以源操作数的可选起始位置共有4种,具体见上图。
mask的第三位用于选择目的操作时连续11个字节的起始位置。很显然,共有两个起始位置可供选择。
下面的c代码更清楚的描述了这条指令的功能。
static __m128i compute_mpsadbw (unsigned char *v1, unsigned char *v2, int mask)
{
union
{
__m128i x;
unsigned short s[8];
} ret;
unsigned char s[4];
int i, j;
int offs1, offs2;
offs2 = 4 * (mask & 3);
for (i = 0; i < 4; i++)
s[i] = v2[offs2 + i];
offs1 = 4 * ((mask & 4) >> 2);
for (j = 0; j < 8; j++)
{
ret.s[j] = 0;
for (i = 0; i < 4; i++)
ret.s[j] += abs (v1[offs1 + j + i] - s[i]);
}
return ret.x;
}
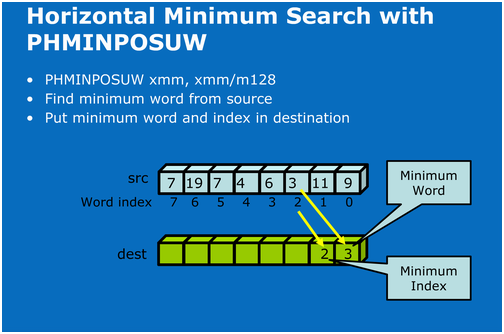
2. 水平方向上最小值查找指令 PHMINPOSUW
这条指令相对而言比较好理解,下面这张图很好的描述了这条指令的执行过程:
3. 整数格式转换指令
整数格式转换,例如,把一个8位的字节型变量转换为16位字变量,或者32位的双字变量等。这种运算在图像,语音信号处理中的经常碰到。例如,图像数据是8位的字节 型变量,如果运算过程中的浮点变量定点化采用的Q15格式,则需要将8位无符号扩展为16位以适应SIMD的并行运算,如果为了更高的精度,Q15格式显然太低,例如采用Q24是一个不错的选择,这时候需要将8位无符号扩展为32位双字变量以适应SIMD的并行运算。
SSE4.1提供了12条不同的指令来完成各种不同整数格式之间的转换。详见下图:

从上图可以看出,把8位的字节型变量扩展为32位的双字变量,SSE4.1用了一条指令
PMOVSXBD xmm0, m32
而SSE2指令用了4条指令,即:
movd xmm0, m32
punpcklbw xmm0,xmm0
punpcklwd xmm0,xmm0
psrad xmm0, 24
4. 视频编码中运动估计
运动估计占视频编码30%以上的时间,采用SSE的SIMD指令可有效加速运动估计的计算过程。
4.1 4x4块匹配运动估计代码
int blockMatch4x4(const unsigned char* refFrame, int stepBytesRF,
const unsigned char* curBlock, int stepBytesCB, int* matchBlock,
int frameWidth, int frameHeight)
{
int lowSum = INT_MAX;
int i,j,k,l;
int temSum = 0;
int blockHeight = 4;
int blockWidth = 4;
const unsigned char *pRef, *pCur;
for (i = 0; i <= frameHeight - blockHeight; i++)
{
for (j = 0; j <= frameWidth - blockWidth; j++)
{
temSum = 0;
pCur = curBlock;
pRef = refFrame + i * stepBytesRF + j;
for (k=0; k < 4; k++)
{
for (l=0; l < 4; l++)
{
temSum += labs(*pRef-*pCur);
pCur++;
pRef++;
}
pCur += stepBytesCB - 4;
pRef += stepBytesRF - 4;
}
if (temSum < lowSum)
{
lowSum = temSum;
*matchBlock = j;
*(matchBlock+1) = i;
}
}
}
return 0;
}4.2 4x4块匹配运动估计SSE2指令优化
1 int blockMatch4x4SSE2_opted(const unsigned char* refFrame, int stepBytesRF, const unsigned 2 char* curBlock, int stepBytesCB, int* matchBlock, int frameWidth, int frameHeight) 3 { 4 unsigned int lowSum[4] = {UINT_MAX, UINT_MAX, UINT_MAX, UINT_MAX}; 5 unsigned int temSum = 0; 6 int blockHeight = 4; 7 int blockWidth = 4; 8 int i,j,k,l; 9 const unsigned char *pRef, *pCur; 10 __m128i s0, s1, s2, s3, s4, s5, s6, s7, s8, s9, s10, s11; 11 12 pCur = curBlock; 13 s0 = _mm_loadu_si128((__m128i*)pCur); 14 s1 = _mm_loadu_si128((__m128i*)(pCur + stepBytesCB)); 15 s2 = _mm_loadu_si128((__m128i*)(pCur + 2 * stepBytesCB)); 16 s3 = _mm_loadu_si128((__m128i*)(pCur + 3 * stepBytesCB)); 17 18 19 s8 = _mm_unpacklo_epi32(s0, s1); 20 s9 = _mm_unpacklo_epi32(s2, s3); 21 s10 = _mm_unpackhi_epi32(s0, s1); 22 s11 = _mm_unpackhi_epi32(s2, s3); 23 24 for (i = 0; i <= frameHeight - blockHeight; i++) 25 { 26 for (j = 0; j <= frameWidth - blockWidth; j++) 27 { 28 pRef = refFrame + i * stepBytesRF + j; 29 s6 = _mm_unpacklo_epi32( 30 _mm_cvtsi32_si128(*(unsigned int*)pRef), 31 _mm_cvtsi32_si128(*(unsigned int*)(pRef + stepBytesRF))); 32 33 s6 = _mm_shuffle_epi32(s6, 0x44); 34 35 s7 = _mm_unpacklo_epi32( 36 _mm_cvtsi32_si128(*(unsigned int*)(pRef + 2 * stepBytesRF)), 37 _mm_cvtsi32_si128(*(unsigned int*)(pRef + 3 * stepBytesRF))); 38 39 s7 = _mm_shuffle_epi32(s7, 0x44); 40 41 42 s0 = _mm_adds_epu16(_mm_sad_epu8(s6, s8), _mm_sad_epu8(s7, s9)); 43 44 s1 = _mm_adds_epu16( 45 _mm_sad_epu8(s6, s10), 46 _mm_sad_epu8(s7, s11)); 47 48 49 temSum = _mm_extract_epi16(s0,0); 50 51 if (temSum < lowSum[0]) 52 { 53 lowSum[0] = temSum; 54 *matchBlock = j; 55 *(matchBlock+1) = i; 56 } 57 58 temSum = _mm_extract_epi16(s0,4); 59 if (temSum < lowSum[1]) 60 { 61 lowSum[1] = temSum; 62 *(matchBlock+2) = j; 63 *(matchBlock+3) = i; 64 } 65 66 temSum = _mm_extract_epi16(s1,0); 67 if (temSum < lowSum[2]) 68 { 69 lowSum[2] = temSum; 70 *(matchBlock+4) = j; 71 *(matchBlock+5) = i; 72 } 73 74 temSum = _mm_extract_epi16(s1,4); 75 if (temSum < lowSum[3]) 76 { 77 lowSum[3] = temSum; 78 *(matchBlock+6) = j; 79 *(matchBlock+7) = i; 80 } 81 } 82 } 83 return 0; 84 85 }
4.3 4x4块匹配运动估计SSE4.1指令优化
1 int blockMatch4x4SSE4_opted(const unsigned char* refFrame, int stepBytesRF, const unsigned 2 char* curBlock, int stepBytesCB, int* matchBlock, int frameWidth, int frameHeight) 3 { 4 unsigned int lowSum[4] = {UINT_MAX, UINT_MAX, UINT_MAX, UINT_MAX}; 5 unsigned int temSum = 0; 6 int blockHeight = 4; 7 int blockWidth = 4; 8 int i,j,k; 9 const unsigned char *pRef, *pCur; 10 11 __m128i s0, s1, s2, s3, s4, s5, s6, s7, s8, s9, s10, s11; 12 13 14 pCur = curBlock; 15 s0 = _mm_loadu_si128((__m128i*)pCur); 16 s1 = _mm_loadu_si128((__m128i*)(pCur+stepBytesCB)); 17 s2 = _mm_loadu_si128((__m128i*)(pCur+2*stepBytesCB)); 18 s3 = _mm_loadu_si128((__m128i*)(pCur+3*stepBytesCB)); 19 s8 = _mm_unpacklo_epi32(s0, s1); 20 s9 = _mm_unpacklo_epi32(s2, s3); 21 s10 = _mm_unpackhi_epi32(s0, s1); 22 s11 = _mm_unpackhi_epi32(s2, s3); 23 24 for (i = 0; i <= frameHeight-blockHeight; i++) 25 { 26 for (j = 0; j <= frameWidth-16; j += 8) 27 { 28 pCur = curBlock; 29 pRef = refFrame+i*stepBytesRF+j; 30 s2 = _mm_setzero_si128(); 31 s3 = _mm_setzero_si128(); 32 s4 = _mm_setzero_si128(); 33 s5 = _mm_setzero_si128(); 34 for (k = 0; k < blockHeight; k++) 35 { 36 s0 = _mm_loadu_si128((__m128i*)pRef); 37 s1 = _mm_loadu_si128((__m128i*)pCur); 38 s2 = _mm_adds_epu16(s2, _mm_mpsadbw_epu8(s0, s1, 0)); 39 s3 = _mm_adds_epu16(s3, _mm_mpsadbw_epu8(s0, s1, 1)); 40 s4 = _mm_adds_epu16(s4, _mm_mpsadbw_epu8(s0, s1, 2)); 41 s5 = _mm_adds_epu16(s5, _mm_mpsadbw_epu8(s0, s1, 3)); 42 pCur+=stepBytesCB; 43 pRef+=stepBytesRF; 44 } 45 s6 = _mm_minpos_epu16(s2); 46 temSum = _mm_extract_epi16(s6,0); 47 if (temSum < lowSum[0]) 48 { 49 lowSum[0] = temSum; 50 k = _mm_extract_epi16(s6,1); 51 *matchBlock = j+k; 52 *(matchBlock+1) = i; 53 } 54 55 s6 = _mm_minpos_epu16(s3); 56 temSum = _mm_extract_epi16(s6,0); 57 if (temSum < lowSum[1]) 58 { 59 lowSum[1] = temSum; 60 k = _mm_extract_epi16(s6,1); 61 *(matchBlock+2) = j+k; 62 *(matchBlock+3) = i; 63 } 64 65 s6 = _mm_minpos_epu16(s4); 66 temSum = _mm_extract_epi16(s6,0); 67 if (temSum < lowSum[2]) 68 { 69 lowSum[2] = temSum; 70 k = _mm_extract_epi16(s6,1); 71 *(matchBlock+4) = j+k; 72 *(matchBlock+5) = i; 73 } 74 75 s6 = _mm_minpos_epu16(s5); 76 temSum = _mm_extract_epi16(s6,0); 77 if (temSum < lowSum[3]) 78 { 79 lowSum[3] = temSum; 80 k = _mm_extract_epi16(s6,1); 81 *(matchBlock+6) = j+k; 82 *(matchBlock+7) = i; 83 } 84 } 85 86 for (; j <= frameWidth - blockWidth; j++) 87 { 88 pRef = refFrame+i*stepBytesRF+j; 89 s6 = _mm_unpacklo_epi32( 90 _mm_cvtsi32_si128(*(unsigned int*)pRef), 91 _mm_cvtsi32_si128(*(unsigned int*)(pRef+stepBytesRF)) 92 ); 93 94 s6 = _mm_shuffle_epi32(s6, 0x44); 95 s7 = _mm_unpacklo_epi32( 96 _mm_cvtsi32_si128(*(unsigned int*)(pRef+2*stepBytesRF)), 97 _mm_cvtsi32_si128(*(unsigned int*)(pRef+3*stepBytesRF)) 98 ); 99 100 s7 = _mm_shuffle_epi32(s7, 0x44); 101 s0 = _mm_adds_epu16(_mm_sad_epu8(s6, s8), _mm_sad_epu8(s7, s9)); 102 s1 = _mm_adds_epu16( 103 _mm_sad_epu8(s6, s10), 104 _mm_sad_epu8(s7, s11) 105 ); 106 107 temSum = _mm_extract_epi16(s0,0); 108 if (temSum < lowSum[0]) 109 { 110 lowSum[0] = temSum; 111 *matchBlock = j; 112 *(matchBlock+1) = i; 113 } 114 115 temSum = _mm_extract_epi16(s0,4); 116 if (temSum < lowSum[1]) 117 { 118 lowSum[1] = temSum; 119 *(matchBlock+2) = j; 120 *(matchBlock+3) = i; 121 } 122 123 temSum = _mm_extract_epi16(s1,0); 124 if (temSum < lowSum[2]) 125 { 126 lowSum[2] = temSum; 127 *(matchBlock+4) = j; 128 *(matchBlock+5) = i; 129 } 130 131 temSum = _mm_extract_epi16(s1,4); 132 if (temSum < lowSum[3]) 133 { 134 lowSum[3] = temSum; 135 *(matchBlock+6) = j; 136 *(matchBlock+7) = i; 137 } 138 } 139 } 140 return 0; 141 }