Lucene是目前最为流行的开源全文搜索引擎工具包,提供了完整的查询引擎和索引引擎,部分文本分析引擎。
我们平时使用kibana、阿里云的日志查询或者其他一些lucene二次开发的产品,几乎都支持lucene语法。
下面给大家演示各种查询方式,更多请参考 Apache Lucene - Query Parser Syntax
一、单词查询
直接使用单词,例如chenqionghe
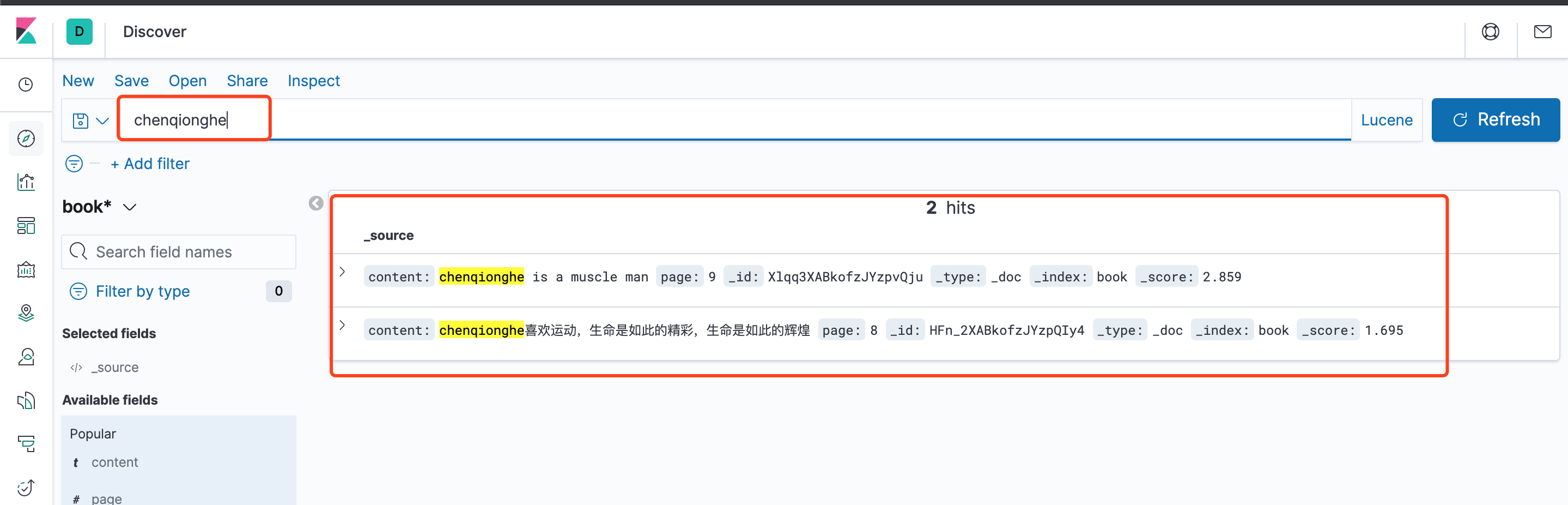
多个单词,可以用逗号或者空格隔开,例如chenqionghe,活动
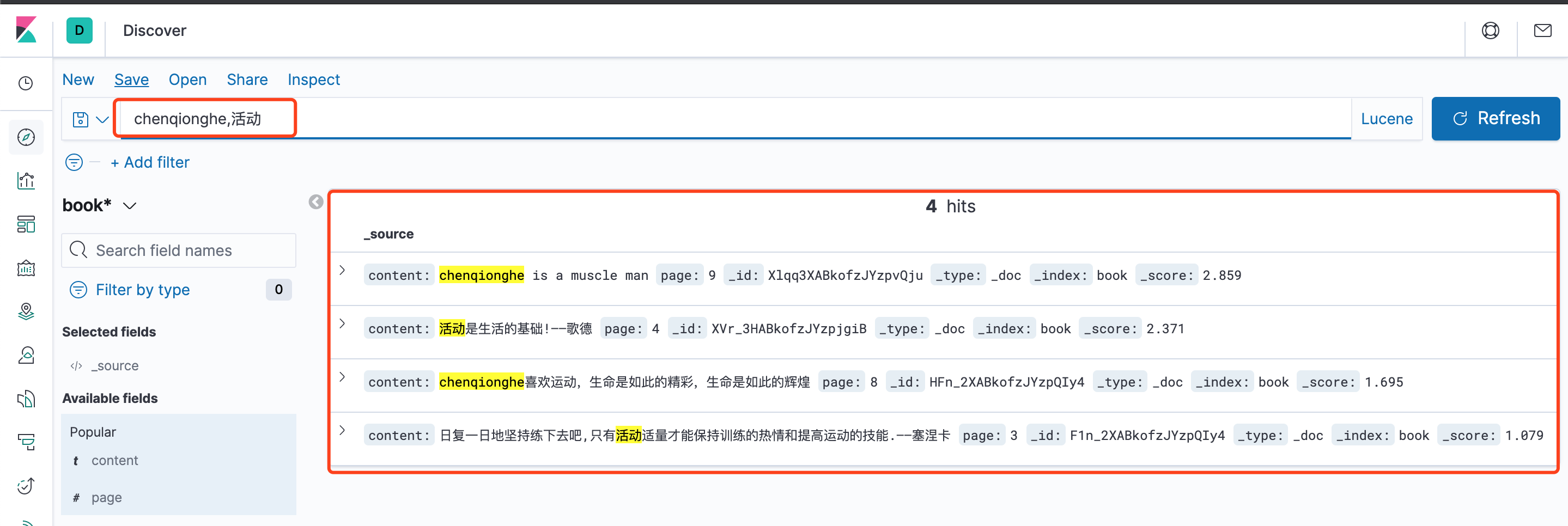
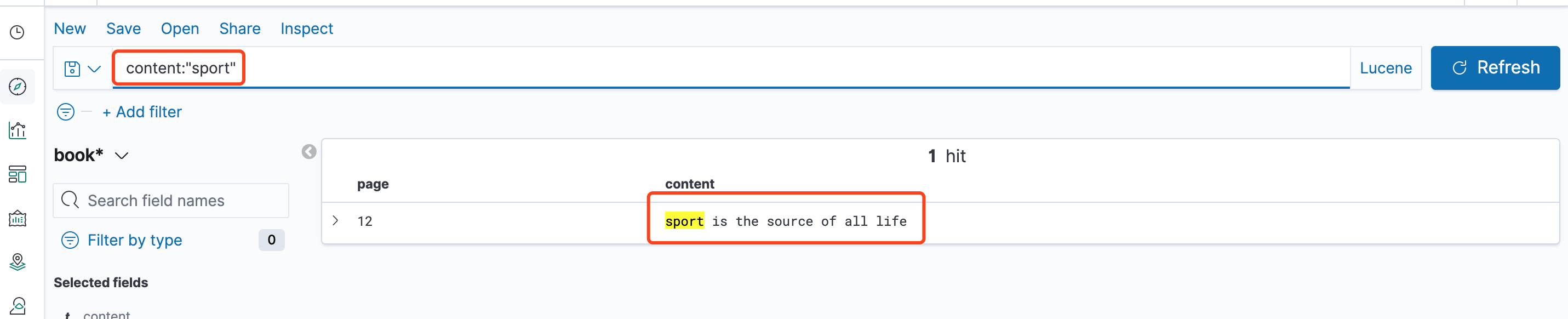
可以指定字段:空格来查询,例如page: 18、content:"sport"

二、通配符查询
- ?匹配单个字符
- *匹配0或多个字符
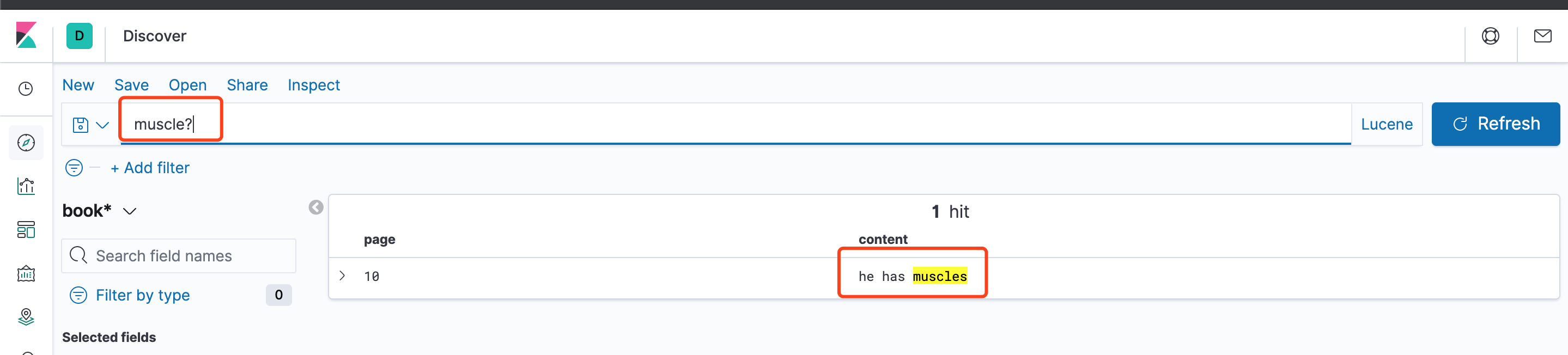
例如muscle?能匹配到muscles
搜索hi*er
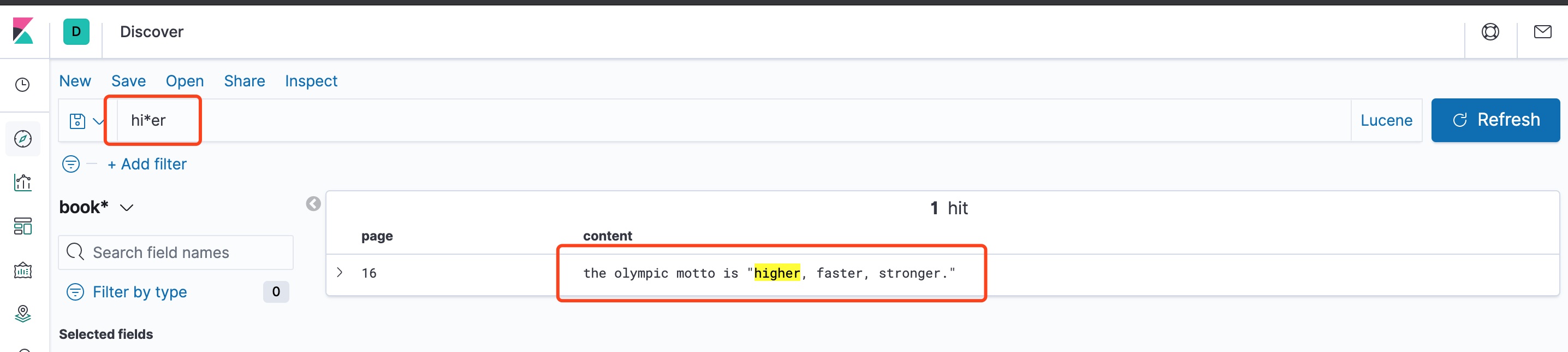
搜索 *er
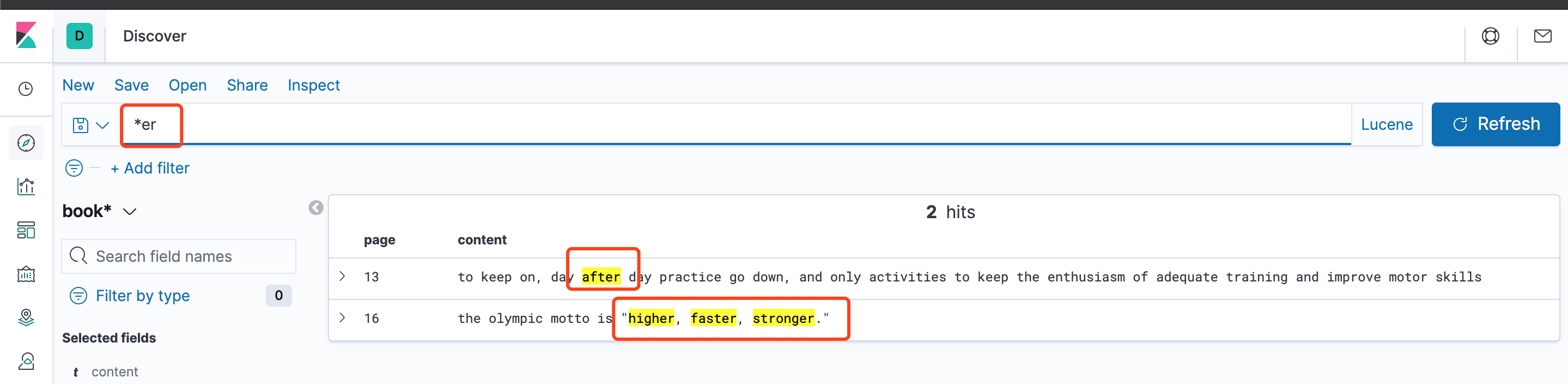
三、模糊查询
~:在一个单词后面加上~启用模糊搜索,可以搜到一些拼写错误的单词
例如first~能匹配到错误的单词frist
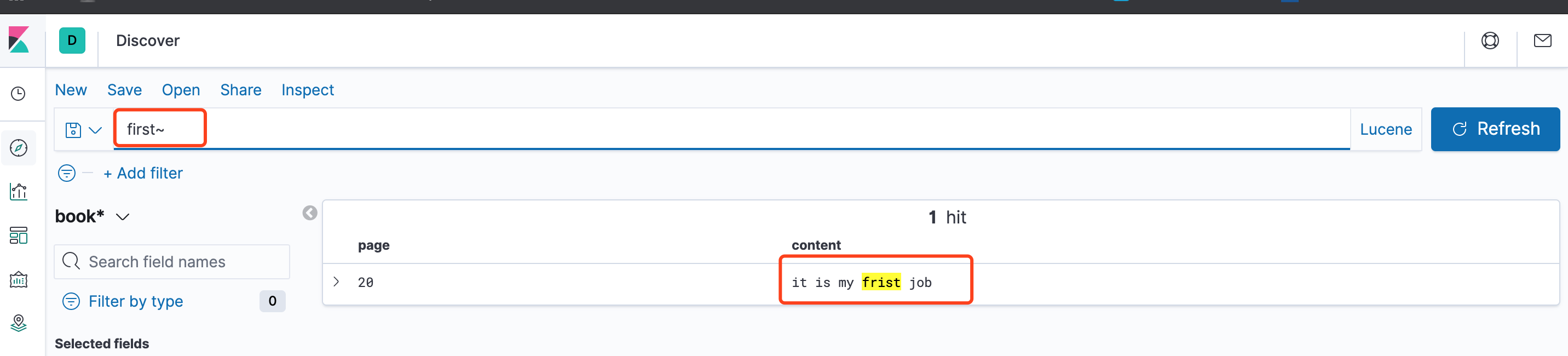
可以在~后面添加模糊系数,例如first~0.8,模糊系数[0-1],越靠近1表示越相近,默认模糊系数为0.5。
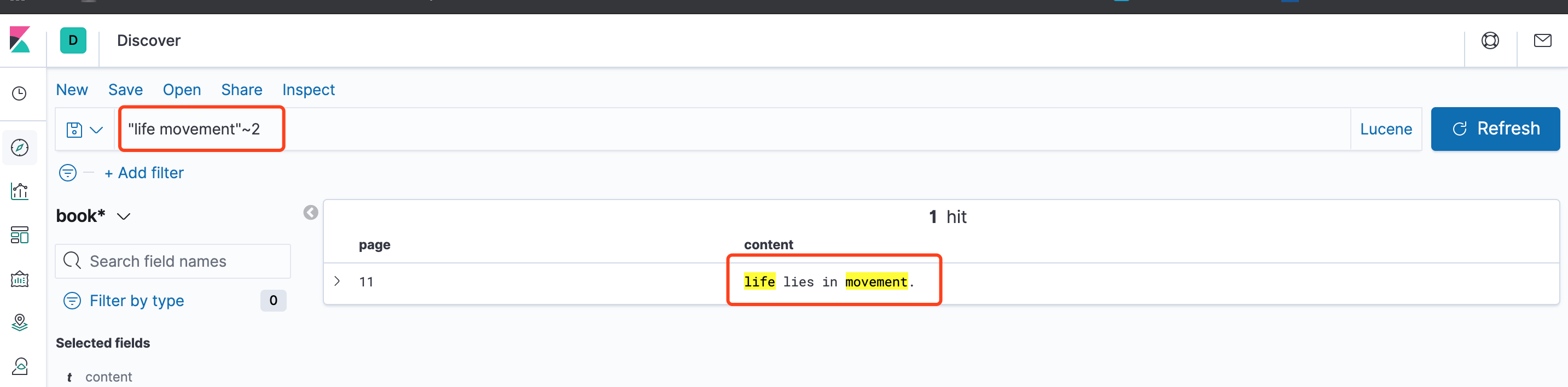
四、近似查询
在短语后面加上~,可以搜到被隔开或顺序不同的单词
"life movement"~2表示life和movement之间可以隔开2两个词
五、范围查询
page: [2 TO 8]page: {2 TO 8}
[]表示端点数值包含在范围内,{}表示端点不包含在范围内
搜索第2到第8页,包含两端点page: [2 TO 8]
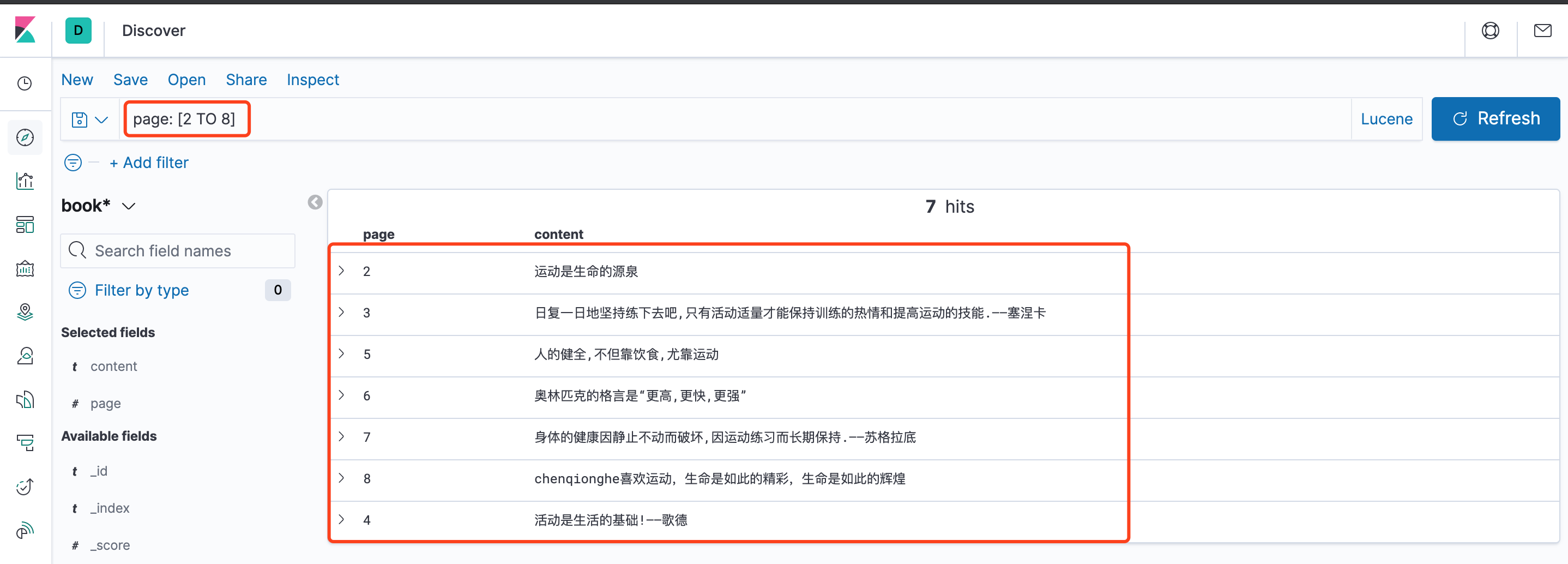
搜索第2到第8页,不包含两端点page: {2 TO 8}
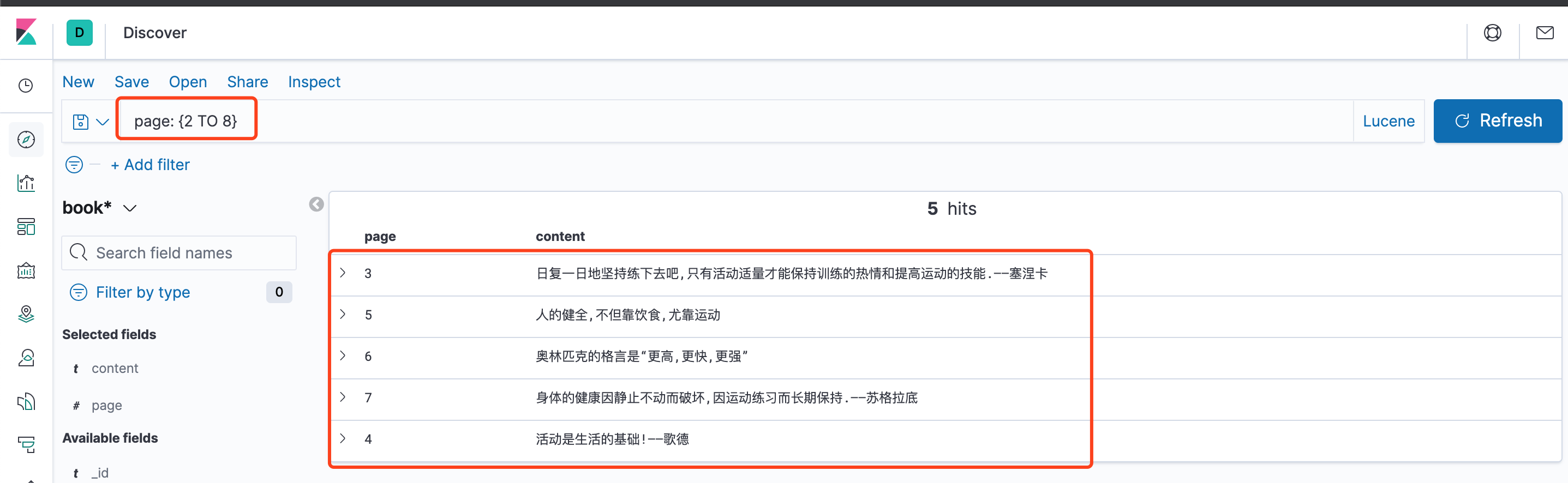
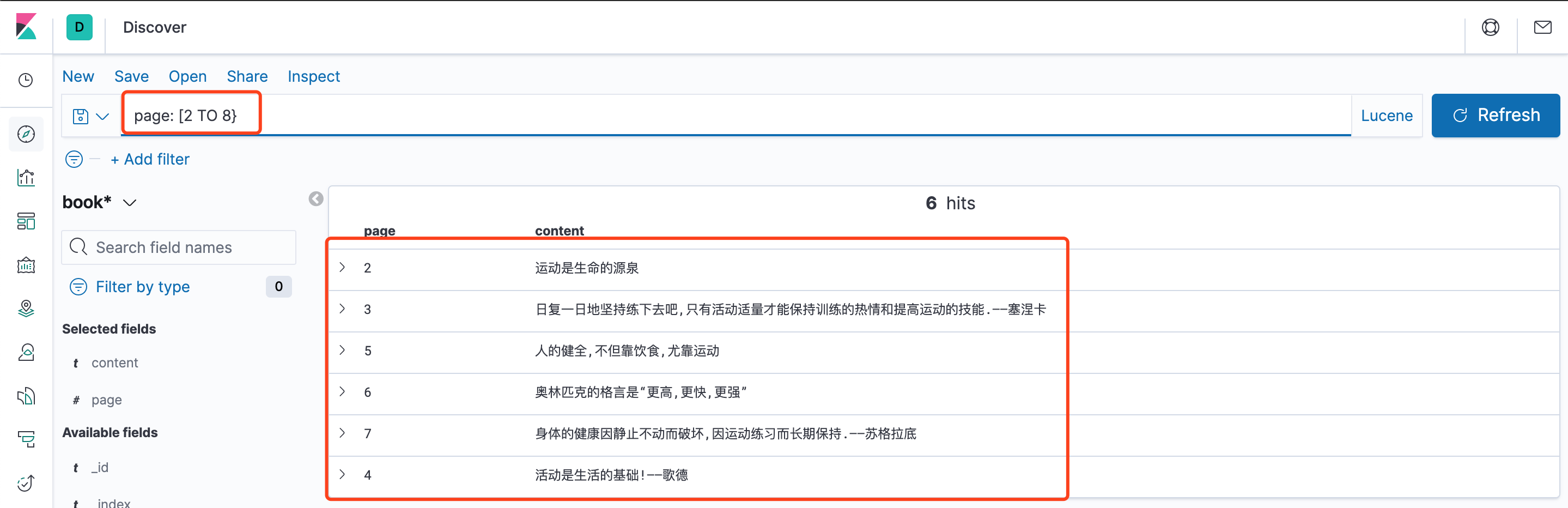
搜索第2到第8页,包含起始不包含末端page: [2 TO 8}
六、优先级查询
如果单词的匹配度很高,一个文档中或者一个字段中可以匹配多次,那么可以提升该词的相关度。使用符号^提高相关度。
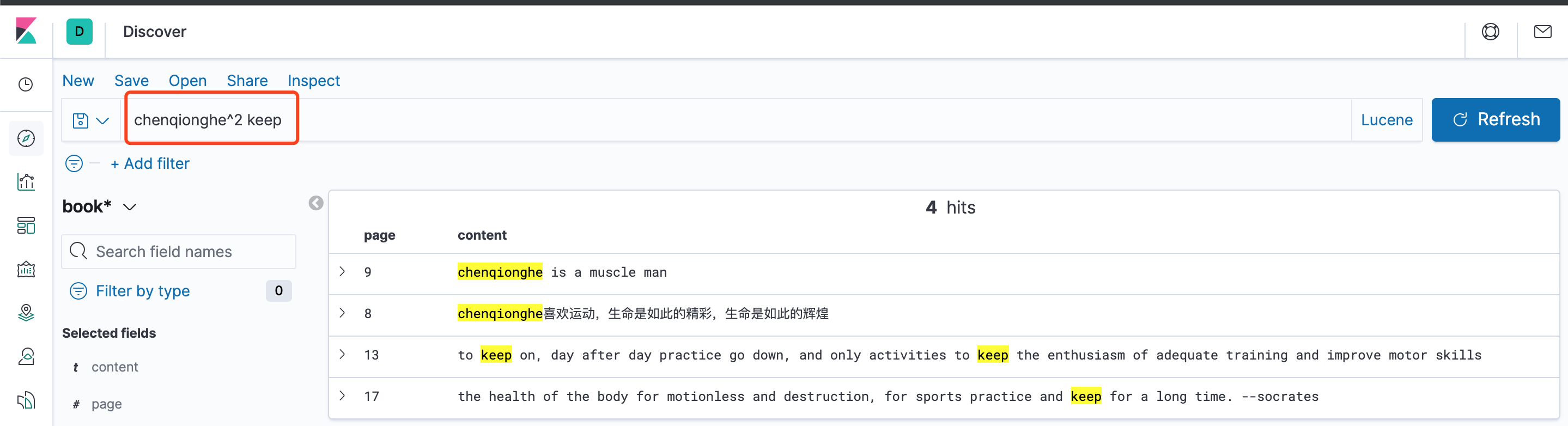
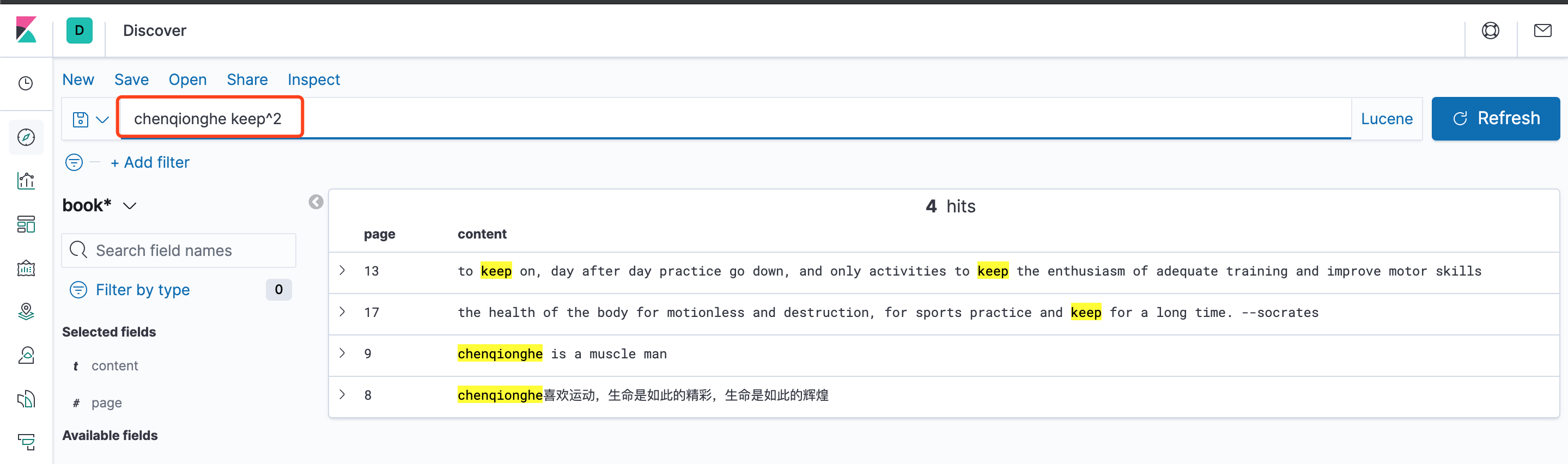
默认为1,可以为0~1之间的浮点数,来降低优先级
七、逻辑操作
AND:逻辑与,也可以用&&代替OR:逻辑或,也可以使用||代替NOT:逻辑非,也可以使用!代替- +:必须包含
- -:不能包含
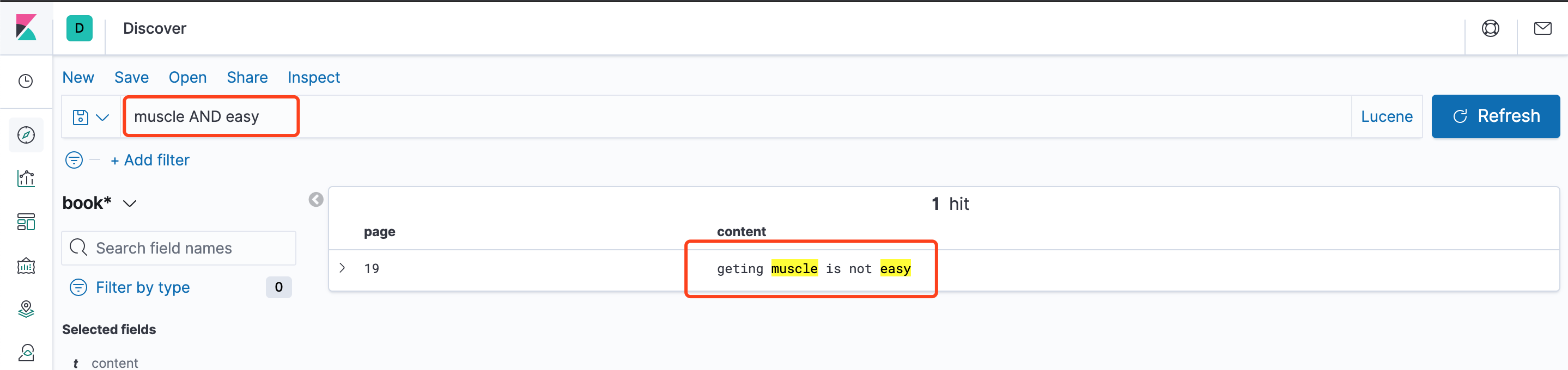
如muscle AND easy,muscle和easy必须同时存在
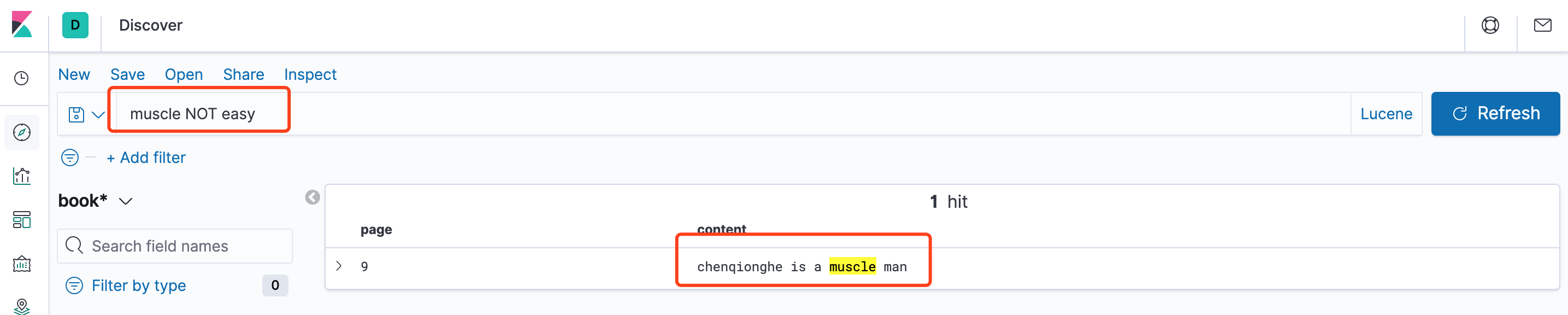
muscle NOT easy,muscle存在easy不存在
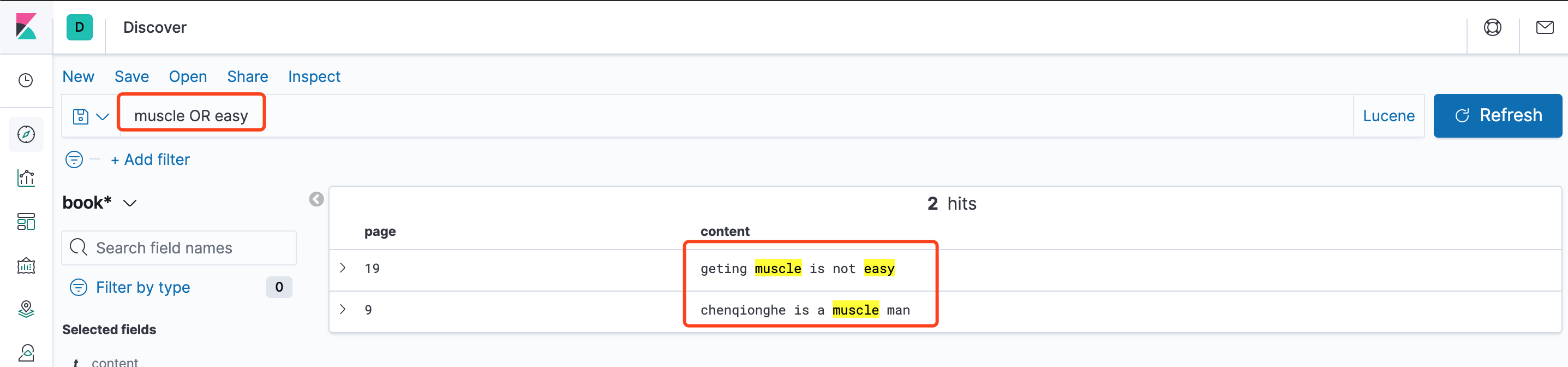
muscle OR easy,muscle或easy存在
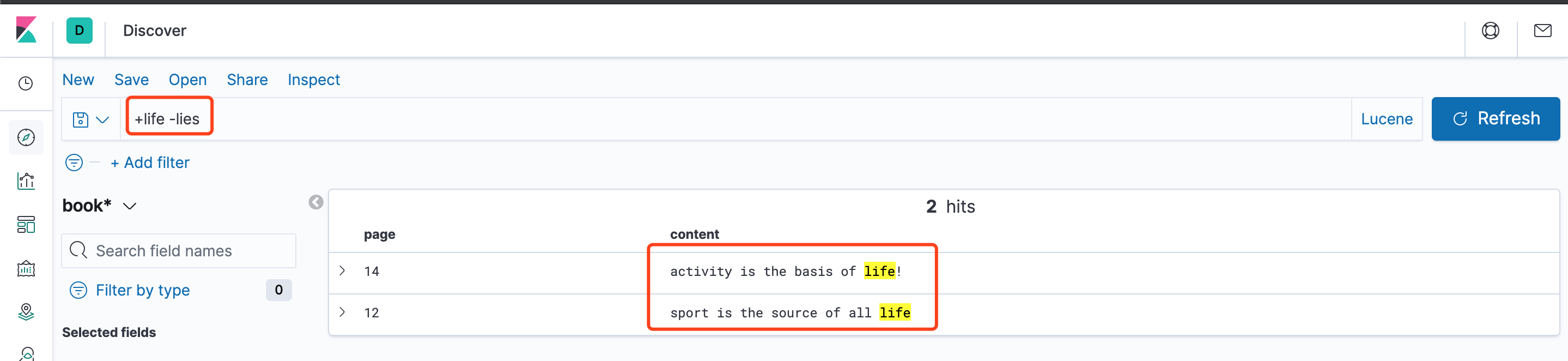
例如+life -lies:必须包含life,不包含lies
八、括号分组
可以使用小括号对子句进行分组,构造更复杂的查询逻辑
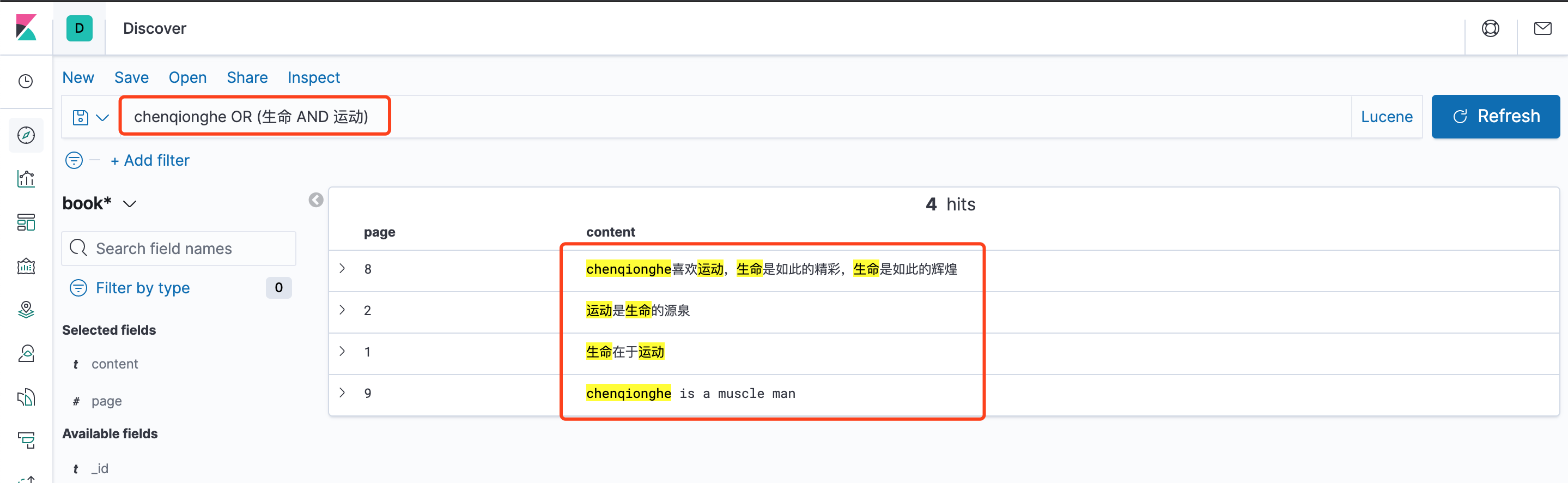
chenqionghe OR (生命 AND 运动)
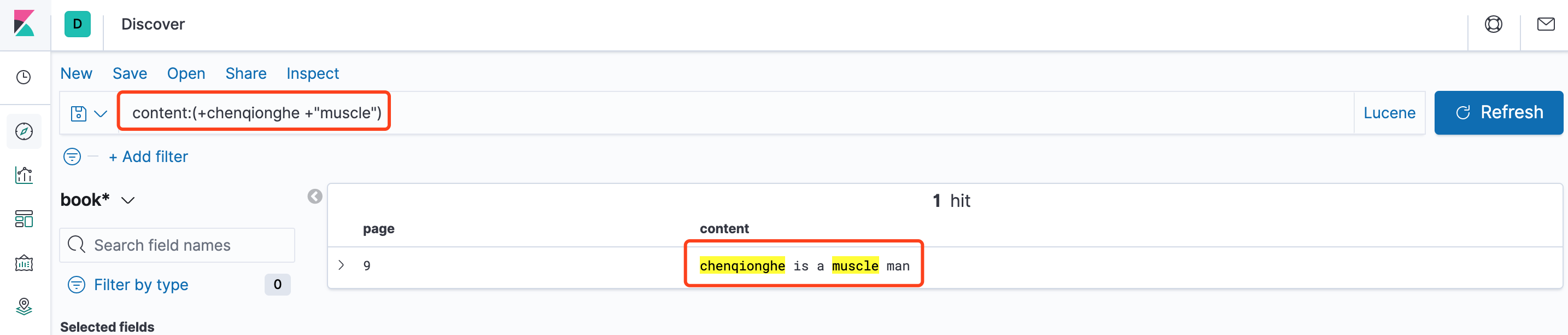
同时,也可以在字段中使用小括号分组,例如content:(+chenqionghe +"muscle")
九、转义特殊字符
+ - && || ! ( ) { } [ ] ^ " ~ * ? :
这些字符需要转义
例如(1+1):2用来查询(1+1):2
到这就讲完了,是不是觉得超简单,惊不惊喜,意不意外呀~