逻辑斯谛回归是统计学习中的经典分类方法,和最大熵模型相比,具有以下的共同点和区别:
- 共同点
- 都属于概率模型,该模型要寻找的是给定一个x,得到输出变量Y的概率分布P(Y|x),如果是二分类,Y取值为0或1,如果是多分类,Y有K个不同的类别。
- 都属于对数线性模型,对概率分布P(Y|x)取对数,可得lnP(Y|x)=w * x关于x的线性函数。
- 两个模型之前的区别和联系是Logistic回归和最大熵模型都属于判别模型。在最大熵模型中,不仅x有随机性,Y也具有随机性,是一个随机变量。
Logistic回归模型(Logistic Regression Model)
给定输入变量,输出变量为
,将
的概率记作
,我们已经知道该模型是一个线性模型,可以用
线性 函数来表示,由于
,那么要如何将
与
对应起来呢?这就需要用到一个变换,该变换称为Logit变换。
Logit变换:
,这个就是Logistic回归模型的一个形式。
,其中
就是给定
的条件下,
的概率。
所以可得下面两个公式:
有了这个模型之后,需要求解参数,一旦求出
,那么任意给定一个输入变量
,就可以得到
的概率,如果该概率值大于0.5,就将该类判定为1,如果小于0.5,将该类判定为0。
求解使用的方法是极大似然估计,给定参数
,求样本的联合概率密度,最大化该联合概率,从而求出参数
。
已知,
可得
似然函数为
多项Logistic回归模型
在多分类Logistic回归模型中,取值为
,那么Logit变换是
,因为
的取值为
,所以
变为
,一共需要求取
个参数向量。
所以可得下面两个公式:
最大熵模型(Maximum Entropy Model)
最大熵模型主要是在自然语言处理中应用的比较广泛。最大熵模型是由最大熵原理推导实现的。而最大熵原理指的是在满足约束条件的模型集合中选择熵最大的模型。那么我们为何需要选择熵最大的模型呢?在决策树中,我们已经提到熵的概念,熵其实表示的是数据的混乱程度。在我们不知道任何信息的情况下,我们就只能假设数据在各个取值上比较平均,比较散乱,即比较数据的混乱程度。这样描述,可能不太清楚,直接看下面的一个例题:
假设随机变量X由5个取值{A,B,C,D,E},要估计取各个值的概率P(A),P(B),P(C),P(D),P(E)。
对于一个概率问题,我们可以知道:
P(A) + P(B)+ P(C) + P(D) + P(E) =1
根据最大熵原理,取值随机且平均,那么P(A)=P(B)=P(C)=P(D)=P(E)=1/5。
当然有时候我们也能得到一些先验条件,比如:P(A)+P(B)=3/10。对于这种问题,我们在问题中就出现了一些约束条件,此时的熵就是条件熵,即:
对于一个训练数据集样本,我们可以确定联合分布P(X,Y)的经验分布和边缘分布P(X)的经验分布,但是求解条件熵仍然存在困难,因为在所有数据集中x的取值是不一样的,而且不固定。此时,我们可以采用经验分布的期望来进行比较。为何可以这样说呢?这就需要我们了解一个二值函数——特征函数(Feature Function)。该函数描述的是输入x和输出y之间的某一个事实,可以定义为:
直观的看,比较难以理解。可以举个例子,比如我们在做一个机器英译汉的翻译的时候,如果你输入一句话中带有take单词的英文句子I take a lot of money to buy a house.,此时take的含义表示花费,但是如果你输入She decided to take a bus to work since yesterday.,此时take的含义表示乘坐。take单词后面跟着不同单词,就需要翻译成不同的意思,此时next word是一个条件,在这种条件下,take翻译成不同的含义,满足这一个事实。由此,可以得到特征函数关于经验分布P(X,Y)和P(Y|X)与P(X)的期望值如下表述:
如果模型能够获取训练数据集中的信息,那么可以假设两个期望相等。得到以下最大熵模型。
最大熵模型的数学推导
最大熵模型学习过程中,最重要的是最大熵模型的学习,也就是求解约束条件下的最优化问题。
按照最优化的习惯问题,如果需要求H(P)的最大值,可以转化成求-H(P)的最小值。
此处可以将约束最优化问题转换成无约束最优化的对偶问题,通过求解对偶问题来求解原始问题。
-
第一步,首先针对原始问题定义拉格朗日乘子w0,w1...wn,拉格朗日函数为:
[L(P,w)=-H(p)+w_0(1-sum_yP(y|x))+sum_{i=1}^nw_i(E_p(f_i)-E_{widetilde{P}}(f_i))\ =sum_{x,y}widetilde{P}(x)P(y|x)logP(y|x)+w_0(1-sum_yP(y|x))+sum_{i=1}^nw_i(E_p(f_i)-E_{widetilde{P}}(f_i))\ 原始问题:min_{p in C}max_wL(P,w)\ =>对偶问题:max_wmin_{p in C}L(P,w) ] -
由于拉格朗日函数是凸函数,因此原始问题的解和对偶问题的解是等价的,即求解原始问题的极小极大值可以转换成极大极小值。对L(P,w)求偏导。
[令对偶函数为Psi(w)=min_{P in C} L(P,w)=L(P_w,w)\ 因此对偶函数求解得:P_w=argmin_{P in C}L(P,w)=P_w(y|x)\ frac{partial L(P,w)}{partial w} = sum_{x,y}(widetilde{P}(x)logP(y|x)+1)-sum_yw_0-sum_{x,y}(widetilde{P}(x)sum_{i=1}^nw_if_i(x,y))\ = sum_{x,y}widetilde{P}(x){logP(y|x)+1-sum_yw_0-sum_{x,y}(sum_{i=1}^nw_if_i(x,y)}\ 令偏导数为0,widetilde{P}(x) >0的情况下,可得到: \ P(y|x)=exp{sum_{i=1}^nw_if_i(x,y)+w_0-1}\ =frac{exp(sum_{i=1}^nw_if_i(x,y))}{exp(1-w_0)}\ 由于sum_y(P(y|x))=1,得:\ P_w(y|x)=frac{1}{Z_w(x)}exp(sum_{i=1}^nw_if_i(x,y)),其中Z_w(x)=exp(sum_{i=1}^nw_if_i(x,y)),\ 在这里,Z_w(x)被称为归一化因子,f_i是特征函数,w_i是特征的权值。 ] -
求解对偶问题的外部的极大值问题。
[w*=argmax_w Psi(w)\ 即:P*=P_{w*}=P_{w*}(y|x)是学习到的最优化模型,也就是最大熵模型。 ]
Python实现
自编程实现
## 使用梯度下降法实现逻辑斯蒂回归算法
import numpy as np
import time
import matplotlib.pyplot as plt
from mpl_toolkits.mplot3d import Axes3D
plt.rcParams['font.sans-serif']=['SimHei'] #用来正常显示中文标签
plt.rcParams['axes.unicode_minus']=False #用来正常显示负号
class LogisticRegression:
def __init__(self,learn_rate=0.1,max_iter=10000,tol=1e-2):
self.learn_rate=learn_rate #学习率
self.max_iter=max_iter #迭代次数
self.tol=tol #迭代停止阈值
self.w=None #权重
def preprocessing(self,X):
"""将原始X末尾加上一列,该列数值全部为1"""
row=X.shape[0]
y=np.ones(row).reshape(row, 1)
X_prepro =np.hstack((X,y))
return X_prepro
def sigmod(self,x):
return 1/(1+np.exp(-x))
def fit(self,X_train,y_train):
X=self.preprocessing(X_train)
y=y_train.T
#初始化权重w
self.w=np.array([[0]*X.shape[1]],dtype=np.float)
k=0
for loop in range(self.max_iter):
# 计算梯度
z=np.dot(X,self.w.T)
grad=X*(y-self.sigmod(z))
grad=grad.sum(axis=0)
# 利用梯度的绝对值作为迭代中止的条件
if (np.abs(grad)<=self.tol).all():
break
else:
# 更新权重w 梯度上升——求极大值
self.w+=self.learn_rate*grad
k+=1
print("迭代次数:{}次".format(k))
print("最终梯度:{}".format(grad))
print("最终权重:{}".format(self.w[0]))
def predict(self,x):
p=self.sigmod(np.dot(self.preprocessing(x),self.w.T))
print("Y=1的概率被估计为:{:.2%}".format(p[0][0])) #调用score时,注释掉
p[np.where(p>0.5)]=1
p[np.where(p<0.5)]=0
return p
def score(self,X,y):
y_c=self.predict(X)
error_rate=np.sum(np.abs(y_c-y.T))/y_c.shape[0]
return 1-error_rate
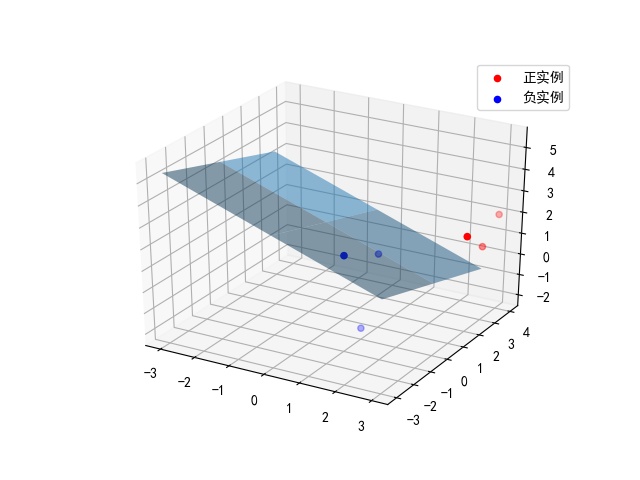
def draw(self,X,y):
# 分离正负实例点
y=y[0]
X_po=X[np.where(y==1)]
X_ne=X[np.where(y==0)]
# 绘制数据集散点图
ax=plt.axes(projection='3d')
x_1=X_po[0,:]
y_1=X_po[1,:]
z_1=X_po[2,:]
x_2=X_ne[0,:]
y_2=X_ne[1,:]
z_2=X_ne[2,:]
ax.scatter(x_1,y_1,z_1,c="r",label="正实例")
ax.scatter(x_2,y_2,z_2,c="b",label="负实例")
ax.legend(loc='best')
# 绘制p=0.5的区分平面
x = np.linspace(-3,3,3)
y = np.linspace(-3,3,3)
x_3, y_3 = np.meshgrid(x,y)
a,b,c,d=self.w[0]
z_3 =-(a*x_3+b*y_3+d)/c
ax.plot_surface(x_3,y_3,z_3,alpha=0.5) #调节透明度
plt.show()
Sklearn库实现
from sklearn.linear_model import LogisticRegression
import numpy as np
def main():
# 训练数据集
X_train=np.array([[3,3,3],[4,3,2],[2,1,2],[1,1,1],[-1,0,1],[2,-2,1]])
y_train=np.array([1,1,1,0,0,0])
# 选择不同solver,构建实例,进行训练、测试
methodes=["liblinear","newton-cg","lbfgs","sag","saga"]
res=[]
X_new = np.array([[1, 2, -2]])
for method in methodes:
clf=LogisticRegression(solver=method,intercept_scaling=2,max_iter=1000)
clf.fit(X_train,y_train)
# 预测新数据
y_predict=clf.predict(X_new)
#利用已有数据对训练模型进行评价
X_test=X_train
y_test=y_train
correct_rate=clf.score(X_test,y_test)
res.append((y_predict,correct_rate))
实现结果图: