概述
数据库相对于其它存储软件一个核心的特征是它支持事务,所谓事务的ACID就是原子性,一致性,隔离性和持久性。其中原子性,一致性,持久性更多是关注单个事务本身,比如,原子性要求事务中的操作要么都提交,要么都不提交;一致性要求事务的操作必须满足定义的约束,包括触发器,外键约束等;持久性则要求如果事务成功提交了,无论发生什么异常,包括进程crash,主机掉电等,都应该确保事务不会丢失。而隔离性,则关注的是多个事务之间的并发。
如果所有的事务都串行执行,相互不影响,不会有隔离的级别的问题。但是,串行无法充分发挥多核的优势,因此需要并发执行多个事务,并且“尽量”做到并发执行的事务与串行执行等价。为什么是“尽量”?是因为数据库中实际上不只有一种隔离级别,可串行化,所以才有必要讨论数据库中的隔离级别。比如拿MySQL举例,隔离级别包括,读未提交,读提交,可重复读,和串行化4种,其中可串行化是最严格的隔离级别,意味着事务之间产生冲突的概率最高。理论上,只有“可串行化”的事务序列才是“正确的”,但是,由于数据库系统需要追求更好的性能,更高的系统吞吐,所以系统中会定义另外“比较弱”的隔离级别。每种“弱”的隔离级别定义,都会明确说明它会产生哪些“异常”,如果用户能容忍这些“异常”,很好,那么我们不用将数据库设置为最严的并发控制模式。所以,简单来说,通过隔离级别的设置,用户可以在“异常”和数据库性能之间做一个权衡。
数据库中异常
本文讨论的隔离级别主要源于论文A Critique of ANSI SQL Isolation Levels,论文中定义了一系列“异常”,并且说明了不同的隔离级别分别解决了哪些“异常”。说明下文中,w[n]表示事务n写,r[n]表示事务n读,a[n]表示事务n-abort,c[n]表示事务n-commit。A0,P1,P2,P3,A4,A5等异常命名编号均来源于论文。
1.脏写
A0,dirty-write(WW),脏写
访问模式:w1[x], w2[x],c1,c2
两个事务先后写x,这种会导致w2事务覆盖w1的写。
2.脏读
P1,dirty-read(WR),脏读
访问模式:w1[x], r2[x],a1,c2
事务2读到的x值,而最终事务1 abort了,这个x值根本不应该存在。
P1是区分Read Uncommitted和Read Committed隔离级别
3.不可重复读
P2,Non-repeatable Read【Fuzzy Read】
访问模式,r1[x],w2[x],w2[commit],r1[x]
事务r1两次访问x,返回的结果不一样。比如x=10,
r1[x=10],w2(x=50),w2[commit],r1[x=50]
事务r1两次读取x,读到了不同的值。
P2用于区分ReadCommitted和RepeatableRead隔离级别。
4.幻读
P3,Phantom
异常:同一个事务,两次读返回的结果集不一样,
这里主要是说的幻读,幻读比不可重复读要求更严格,即事务内的任何一个查询,都不应该受其他事务的更新操作影响(insert,update,delete),而出现结果不一致的现象。比如说,第一个查询select... where x>1 返回了3条记录(3,4,5);在这个时候,有另外的一个事务insert x=6;当再次查询时,发现x>1返回了(3,4,5,6)4条记录,这个就是幻读现象的一种。
P3用于区别Repeatable Read和Serializable。
P1--P3是传统的根据异常区分而定义的隔离级别,读提交,可重复读,串行化。但这种分法描述的异常可能还不够多和完整,特别是对于普遍广泛流行的MVCC并发控制,于是论文中在标准隔离级别基础上将“异常”定义地更丰富,并且详细介绍了目前Snapshot-Isolation。
5.Lost Update(写覆盖)
A4, Lost Update
A4的访问模式r1[x], w2[x], w2[commit], w1[x], w1[commit]
这种访问模式下,w2的更新可能会丢失。因为w1可能基于一个比较old-x来做更新x的操作。
6.Read&Write Skew
A5, (Constraint Violation),考虑到两个相关联记录x,y,满足x+y=100,根据读写可以分为两种
A5A, Read Skew
r1[x]...w2[x]...w2[y]...c2...r1[y]...(c1 or a1)
事务1读取x后,事务2同时更新了x,y然后commit,那么事务1再读取y。
x=50, y=50
r1[x=50]...w2[x=20]...w2[y=80]...c2...r1[y=80]...(c1 or a1)
那么对于事务1,x+y=130
A5B, Write Skew(读后写)
A5B: r1[x]...r2[y]...w1[y]...w2[x]...(c1 and c2 occur)
C(x,y)满足x+y >= 0, x=10, y=0
r1[x=10,y=0],r2[x=10,y=0],w1[y=-10],w2[x=0],w1(commit),w2(commit)
最终结果是x=0,y=-10,导致不满足x+y>=0的约束
数据库的隔离级别
我们谈隔离级别,实际上是在谈并发控制。通常数据库实现并发控制主要有两类,基于锁的悲观并发控制(2PL)和乐观并发控制(OCC)。前者在操作数据的过程中加锁,直到事务提交时才释放。后者在事务读写的过程中不加锁,而是在提交的时候通过对比操作的readset和writeset来判断事务是否存在冲突,来决定是否提交。原始的基于锁的悲观并发控制,读和写都加锁,并发度比较低,因此目前主流的数据库系统都引入了多版本并发控制机制(MVCC),所谓MVCC,简单来说,通过冗余历史版本,达到读不加锁,读写不互斥的目的,这种读就是快照读,区别于加锁模式的当前读。这一改进大大提交的整个数据库系统的并发度,当然,如果要实现可串行化隔离级别,需要做额外的工作来保证。下面简单讨论下不同隔离级别下,分别有哪些异常,以及主流数据库的实现方式。
1.READ UNCOMMITTED
读写都不加锁,数据库完全不做并发控制,基本上没什么实用价值。
2.READ COMMITTED
写记录加锁,读基于快照读,并且事务中每个语句有独立的快照,确保读到最新的事务提交,解决了脏读的问题,但不解决可重复读问题,当然也无法避免幻读,ReadSkew&WriteSkew等问题。
3.REPEATABLE READ
提到REPEATABLE READ隔离级别,不得不提到SNAPSHOT,一般主流数据库里面都不提SNAPSHOT隔离级别,但是实际实现的时候又都是基于SNAPSHOT来做的,但这里又有一些细微的区别。对于MySQL(InnoDB)而言,读的时候仍然是快照读,相对于READ-COMMITED隔离级别,是一个事务一个快照,确保可重复读,也不存在幻读问题;但是写的时候,采用的当前读,也就是更新的时候,不再考虑快照,而是基于最新的版本来更新,这样就可能会造成LostUpdate问题。当然,解决办法也很简单,事务内的读也采用当前读,这样也就避免了LostUpdate问题。这里举个例子:假设t是一张库存表,pk='iphone'是主键,卖出一部iphone就减去一个库存,count=count-1;假设有两种写法
case1: begin: select var = count from t where pk = 'iphone'; var = var - 1; update count = var from t where pk = 'iphone'; commit; case2: begin: update count = count - 1 from t where pk = 'iphone'; commit;
对于case1,就会发生LostUpdate,试想下如果两个同类型的事务并发,快照读读到的是old count,就可能出现覆盖写的问题,导致库存少减了。
对于case2,则不会有LostUpdate问题,update场景下,读都是当前读,在RR隔离级别下,会加写锁,确保能读到最新的count。
对于MySQL(RocksDB)而言,读一样是基于同一个快照;写的时候,仍然是基于快照读(这个与RocksDB的LSM存储结构有关,只能基于一个快照去读取多版本数据),那么要更新记录时候,会判断记录中的版本是否比事务的快照版本新(ValidateSnapshot),如果是,说明在事务获取快照后,有其它事务执行了更新操作,这个时候事务会回滚,也就不会发生LostUpdate问题。PG也是采用类似的机制,与MySQL(InnoDB)的本质区别在于,写的时候,是基于快照读去写,而还是基于当前读去写。最终的效果是,MySQL(InnoDB)在RR隔离级别下,也会存在LostUpdate问题,同时因为快照读和当前读混用(select, select ... for update),实际上严格来说,也就没有解决幻读和可重复读的问题。Oracle没有实现RR隔离级别,只提供RC和SERIALIZABLE隔离级别。无论是MySQL(InnoDB,RocksDB),PG都没有解决WriteSkew问题。
4.SERIALIZABLE
最严格的隔离级别,自然是没有“异常”的,我们前面也说到,为了提供系统的并发度,才选择通过降低数据库的隔离级别,但必需要容忍部分“异常”。串行化解决了脏读/写,丢失更新,幻读,不可重复读,以及ReadSkew&WriteSkew等问题。MySQL(Innodb)通过将所有所有读都变为当前读,并结合(GAP,Next-Key,InsertIntention)lock来实现串行化隔离,PG则是事务提交时,根据readset和writeset检查是否与其它事务之间有读写依赖成环,最终确定事务能否提交。MySQL(Rocksdb)只支持RC和RR,不支持串行化隔离级别。下图来源于论文,整理了不同隔离级别对应的异常。
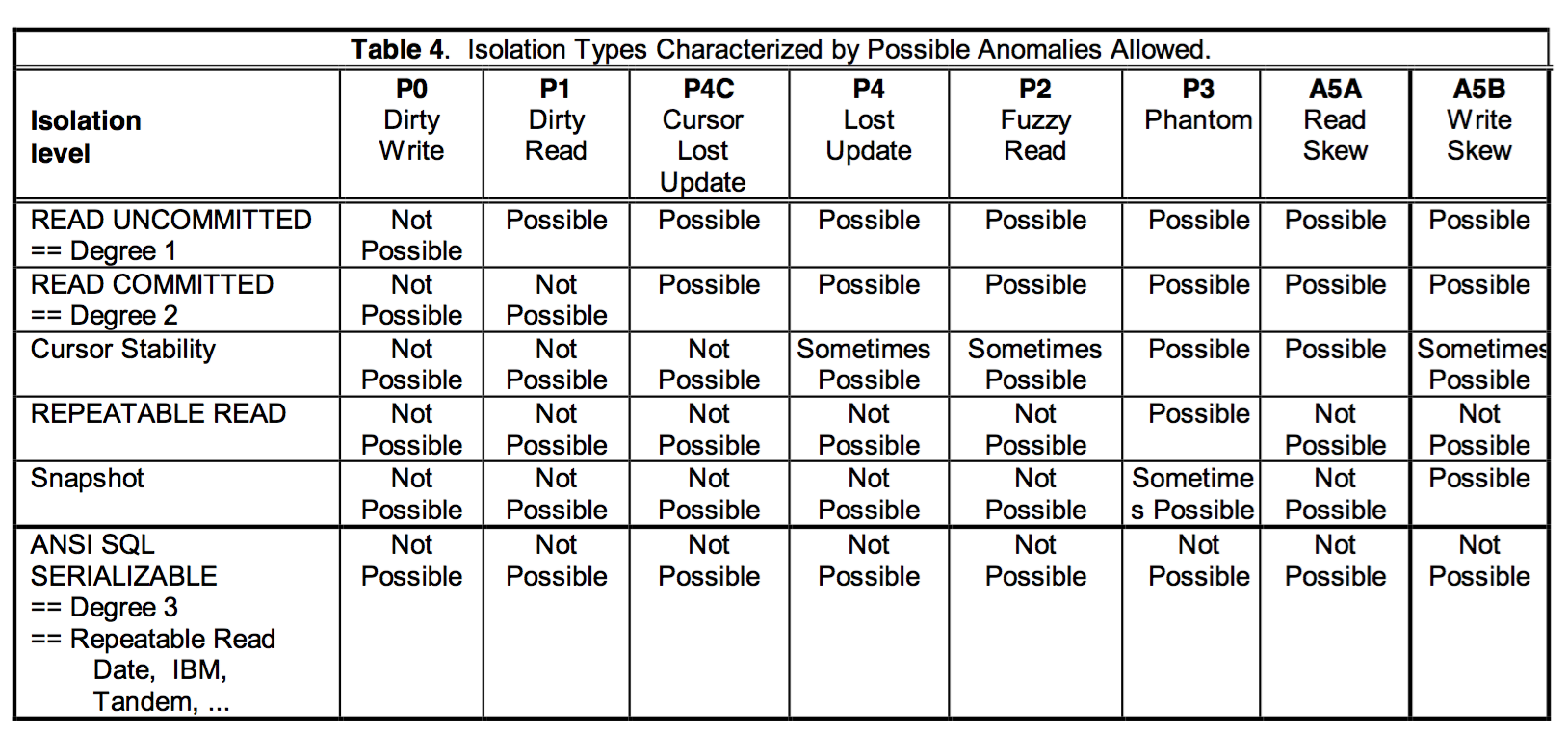
总结
本文结合论文和主流的数据库系统讨论了数据库的隔离级别。一般来说,生产环境中设置ReadCommit的居多,文章中也提到了,在读提交隔离级别下,会存在有不可重复读,幻读以及Read/Write Skew等问题。说明,生产环境是可以“容忍”这些“异常”的。当然,这不能说明隔离级别不重要,如果某些业务场景,不能容忍“异常”,就比如我文章中提到的减库存的例子,如果业务代码写法不正确,就可能导致问题。总之,我们需要在系统的并发度和隔离级别做一个权衡,确保业务正确的前提下,得到最好的性能。
参考文档