前言
目前大多数分布式追踪系统的思想模型都来自 Google's Dapper 论文。
全链路追踪工具一览:
- Drapper(google--未开源):最早的APM;
- 鹰眼(阿里--未开源):
- CAT(大众点评--开源):跨服务的跟踪功能与点评内部的RPC框架集成,这部分未开源且项目在2014.1已经停止维护。服务粒度的监控,通过代码埋点的方式来实现监控,比如: 拦截器,注解,过滤器等,对代码的侵入性较大,集成成本较高;
- Hydra(京东):与dubbo框架集成,对于服务级别的跟踪统计,现有业务可以无缝接入。对于细粒度的兴趣点,需要业务人员手动添加.开源项目已于2013年6月停止维护;
- PinPoint(naver--开源):字节码探针技术,代码无侵入,体系完善不易修改,支持java,技术栈支持dubbo.其他语言社区支援中;
- Zipkin(Twitter--开源):方便集成于spring cloud sleuth,社区支持的插件也包括dubbo,rabbit,mysql,httpclient等,同时支持php,go,js等语言客户端,界面功能较为简单,本身无告警功能,可能需要二次开发。代码入侵度小;
- Uber-jaeger:Jaeger支持java/c++/go/node/php,在界面上较为完善(对比zipkin),但是也无告警功能。代码入侵度小。dubbo目前无插件支持,可二次开发;
- Skywalking(华为--开源):类似于PinPoint,目前还在apache孵化中,网上吞吐量对比中强于pinpoint,实际未验证。本身支持dubbo;
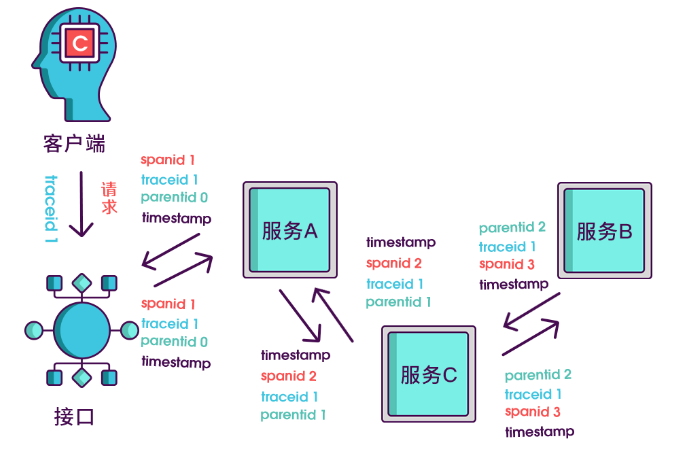
全链路追踪的核心思想:
- 为每条请求都单独分配一个唯一的
traceId用来标识一条请求链路,该traceId会贯穿整个请求处理过程的所有服务。 - 每个服务/线程都拥有自己的
spanId标识,代表请求的其中一段处理步骤。 - 一个请求包含一个
traceId和一个或多个spanId。
本文重点关注以下三种 APM 组件:
- Zipkin:由Twitter公司开源的调用链分析工具,目前基于springcloud sleuth得到了广泛的使用,特点是轻量,使用部署简单。
- Pinpoint:一款对Java编写的大规模分布式系统的APM工具,由韩国人开源的分布式跟踪组件,特点是支持多种插件,UI功能强大,接入端无代码侵入。
- Skywalking:是本土开源的基于字节码注入的调用链分析,以及应用监控分析工具。特点是支持多种插件,UI功能较强,接入端无代码侵入。目前已加入Apache孵化器。
1. 方案比较
主要从以下几个维度来对比三种组件:
- 探针的性能
主要是agent对服务的吞吐量、CPU和内存的影响。微服务的规模和动态性使得数据收集的成本大幅度提高。
- 对应用的入侵性
对应用是否有入侵性。
- collector的可扩展性
能够水平扩展以便支持大规模服务器集群。
- 全面的调用链路数据分析
提供代码级别的可见性以便轻松定位失败点和瓶颈。
- 对于开发透明,容易开关
添加新功能而无需修改代码,容易启用或者禁用。
- 完整的调用链应用拓扑
自动检测应用拓扑,帮助你搞清楚应用的架构。
1.1 探针的性能
摘自:https://juejin.im/post/5a7a9e0af265da4e914b46f1
比较关注探针的性能,毕竟 APM 定位还是工具,如果启用了链路监控组件后,直接导致吞吐量降低过半,那也是不能接受的。
对 skywalking、zipkin、pinpoint 进行了压测,并与基线(未使用探针)的情况进行了对比。
选用了一个常见的基于 Spring 的应用程序,包含 Spring Boot, Spring MVC,redis客户端,mysql。监控这个应用程序,每个trace,探针会抓取5个span(1 Tomcat, 1 SpringMVC, 2 Jedis, 1 Mysql)。
这边基本和 skywalkingtest 的测试应用差不多。
模拟了三种并发用户:500,750,1000。使用jmeter测试,每个线程发送30个请求,设置思考时间为10ms。使用的采样率为1,即100%,这边与生产可能有差别。
pinpoint默认的采样率为20,即50%,通过设置agent的配置文件改为100%。zipkin默认也是1。组合起来,一共有12种。下面看下汇总表:

从上表可以看出,在三种链路监控组件中,skywalking 的探针对吞吐量的影响最小,zipkin的吞吐量居中。pinpoint 的探针对吞吐量的影响较为明显,在500并发用户时,
测试服务的吞吐量从1385降低到774,影响很大。然后再看下CPU和memory的影响,在内部服务器进行的压测,对CPU和memory的影响都差不多在10%之内。
1.2 对应用的入侵性
- zipkin
没有采用javaagent方式,应用强依赖ZipKin,必须打包到应用中与应用一起运行,每个项目需要添加依赖项、配置,不同探针有不同的bean配置需求;
- skywalking
采用javaagent方式,普通功能对应用无侵入,以下两项功能需要应用稍作修改:
-
- 中添加自定义Tag项:应用代码在
SkyWalking Span中添加自定义Tag,可以按需输出方法参数值等关键信息,辅助应用排错和性能分析,PinPoint和ZipKin都不支持(可自行实现); - 日志中输出全局跟踪ID,需要添加
SkyWalking依赖项;
- 中添加自定义Tag项:应用代码在
- pinpoint
采用javaagent方式,对应用完全无侵入,项目无需添加任何额外依赖项,无需修改代码,这点做得最好;
1.3 collector的可扩展性
collector的可扩展性,使得能够水平扩展以便支持大规模服务器集群。
- zipkin
开发 zipkin-Server(其实就是提供的开箱即用包),zipkin-agent 与 zipkin-Server 通过 http 或者 mq 进行通信,http 通信会对正常的访问造成影响,
所以还是推荐基于mq异步方式通信,zipkin-Server 通过订阅具体的 topic 进行消费。这个当然是可以扩展的,多个 zipkin-Server 实例进行异步消费 mq 中的监控信息。
- skywalking
skywalking的collector支持两种部署方式:单机和集群模式。collector与agent之间的通信使用了gRPC。
当你使用-javaagent参数激活sky-walking的探针, 如果当前上下文中存在traceid,logback将在输出traceId。
如果探针没有被激活,将输出TID: N/A.而且SkyWalking是基于字节码增强的,traceId的传递依赖于SkyWalking的服务端,
如果服务端异常等客户端连接不上服务端的情况,就会出现TID: [Ignored Trace]的情况,就会丢失traceId。
- pinpoint
pinpoint也是支持集群和单机部署的。pinpoint agent通过thrift通信框架,发送链路信息到collector。
1.4 全面的调用链路数据分析
全面的调用链路数据分析,提供代码级别的可见性以便轻松定位失败点和瓶颈。
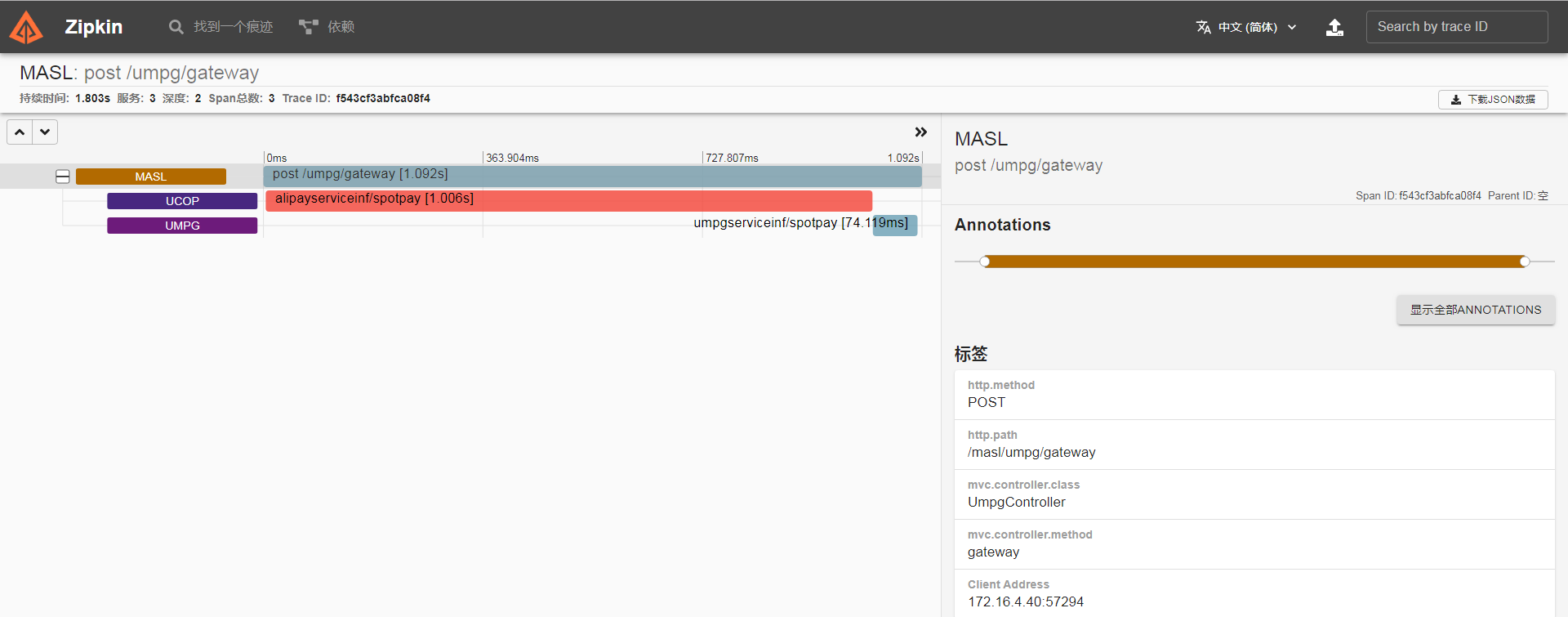
- zipkin
zipkin 的链路监控粒度相对没有那么细,从下图可以看到调用链中具体到接口级别,再进一步的调用信息并未涉及。
- skywalking
skywalking 支持20+的中间件、框架、类库,比如:主流的dubbo、Okhttp,还有DB和消息中间件。
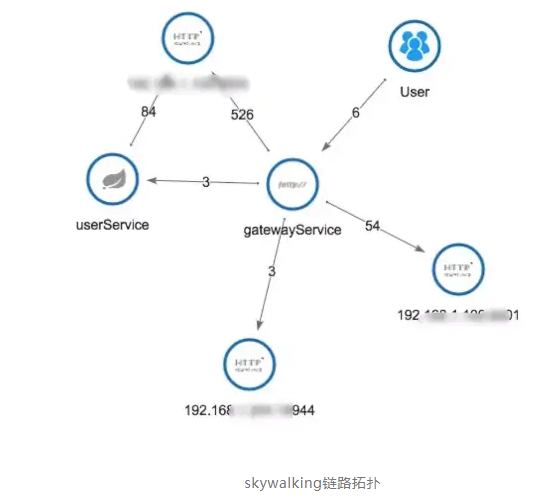
下图skywalking链路调用分析截取的比较简单,网关调用user服务,由于支持众多的中间件,所以skywalking链路调用分析比zipkin完备些。

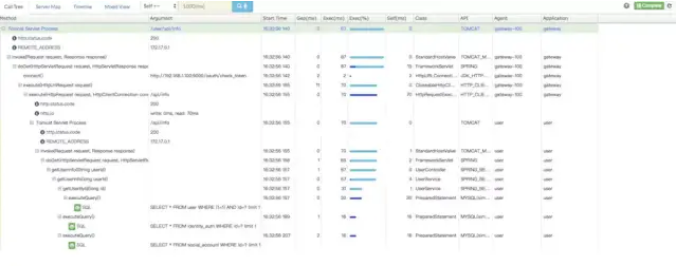
- pinpoint
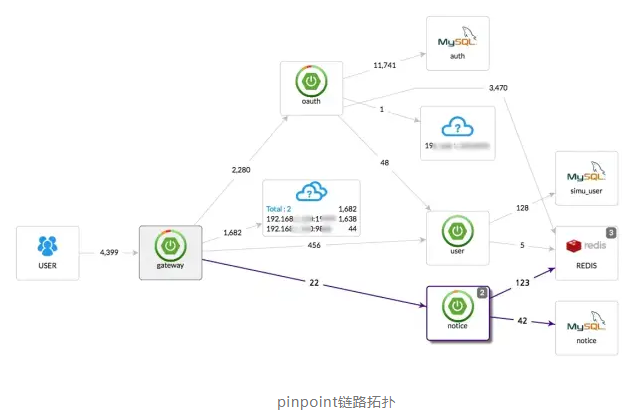
pinpoint应该是这三种APM组件中,数据分析最为完备的组件。提供代码级别的可见性以便轻松定位失败点和瓶颈,下图可以看到对于执行的sql语句,都进行了记录。
还可以配置报警规则等,设置每个应用对应的负责人,根据配置的规则报警,支持的中间件和框架也比较完备。
1.5 对于开发透明,容易开关
对于开发透明,容易开关,添加新功能而无需修改代码,容易启用或者禁用。我们期望功能可以不修改代码就工作并希望得到代码级别的可见性。
对于这一点,Zipkin 使用修改过的类库和它自己的容器(Finagle)来提供分布式事务跟踪的功能。但是,它要求在需要时修改代码。
skywalking和pinpoint都是基于字节码增强的方式,开发人员不需要修改代码,并且可以收集到更多精确的数据因为有字节码中的更多信息。
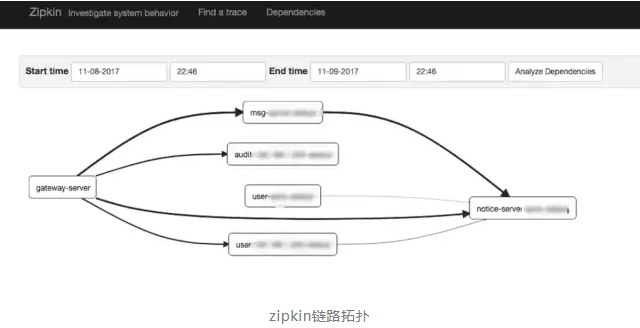
1.6 完整的调用链应用拓扑
自动检测应用拓扑,帮助你搞清楚应用的架构。
下面三幅图,分别展示了APM 组件各自的调用拓扑,都能实现完整的调用链应用拓扑。相对来说,pinpoint 界面显示的更加丰富,具体到调用的DB名,zipkin的拓扑局限于服务于服务之间。
- zipkin
- skywalking
- pingpoint
1.7 Pinpoint与Zipkin细化比较
- Pinpoint与Zipkin差异性
1、Pinpoint 是一个完整的性能监控解决方案:有从探针、收集器、存储到 Web 界面等全套体系;而 Zipkin 只侧重收集器和存储服务,虽然也有用户界面,但其功能与 Pinpoint 不可同日而语。
反而 Zipkin 提供有 Query 接口,更强大的用户界面和系统集成能力,可以基于该接口二次开发实现。
2、Zipkin 官方提供有基于 Finagle 框架(Scala 语言)的接口,而其他框架的接口由社区贡献,目前可以支持 Java、Scala、Node、Go、Python、Ruby 和 C# 等主流开发语言和框架;
但是 Pinpoint 目前只有官方提供的 Java Agent 探针,其他的都在请求社区支援中(请参见 #1759 和 #1760)。
3、Pinpoint 提供有 Java Agent 探针,通过字节码注入的方式实现调用拦截和数据收集,可以做到真正的代码无侵入,只需要在启动服务器的时候添加一些参数,就可以完成探针的部署;
而 Zipkin 的 Java 接口实现 Brave,只提供了基本的操作 API,如果需要与框架或者项目集成的话,就需要手动添加配置文件或增加代码。
4、Pinpoint 的后端存储基于 HBase,而 Zipkin 基于 Cassandra。
- Pinpoint 与 Zipkin 相似性
Pinpoint 与 Zipkin 都是基于 Google Dapper 的那篇论文,因此理论基础大致相同。两者都是将服务调用拆分成若干有级联关系的 Span,通过 SpanId 和 ParentSpanId 来进行调用关系的级联;
最后再将整个调用链流经的所有的 Span 汇聚成一个 Trace,报告给服务端的 collector 进行收集和存储。
即便在这一点上,Pinpoint 所采用的概念也不完全与那篇论文一致。比如他采用 TransactionId 来取代 TraceId,而真正的 TraceId 是一个结构,里面包含了 TransactionId, SpanId 和 ParentSpanId。
而且 Pinpoint 在 Span 下面又增加了一个 SpanEvent 结构,用来记录一个 Span 内部的调用细节(比如具体的方法调用等等),因此 Pinpoint 默认会比 Zipkin 记录更多的跟踪数据。
但是理论上并没有限定 Span 的粒度大小,所以一个服务调用可以是一个 Span,那么每个服务中的方法调用也可以是个 Span,
这样的话,其实 Brave 也可以跟踪到方法调用级别,只是具体实现并没有这样做而已。
- 字节码注入 vs API 调用
Pinpoint 实现了基于字节码注入的 Java Agent 探针,而 Zipkin 的 Brave 框架仅仅提供了应用层面的 API,但是细想问题远不那么简单。
字节码注入是一种简单粗暴的解决方案,理论上来说无论任何方法调用,都可以通过注入代码的方式实现拦截,也就是说没有实现不了的,只有不会实现的。
但 Brave 则不同,其提供的应用层面的 API 还需要框架底层驱动的支持,才能实现拦截。
比如,MySQL 的 JDBC 驱动,就提供有注入 interceptor 的方法,因此只需要实现 StatementInterceptor 接口,并在 Connection String 中进行配置,就可以很简单的实现相关拦截;
而与此相对的,低版本的 MongoDB 的驱动或者是 Spring Data MongoDB 的实现就没有如此接口,想要实现拦截查询语句的功能,就比较困难。
因此在这一点上,Brave 是硬伤,无论使用字节码注入多么困难,但至少也是可以实现的,
但是 Brave 却有无从下手的可能,而且是否可以注入,能够多大程度上注入,更多的取决于框架的 API 而不是自身的能力。
- 难度及成本
经过简单阅读 Pinpoint 和 Brave 插件的代码,可以发现两者的实现难度有天壤之别。在都没有任何开发文档支撑的前提下,Brave 比 Pinpoint 更容易上手。
Brave 的代码量很少,核心功能都集中在 brave-core 这个模块下,一个中等水平的开发人员,可以在一天之内读懂其内容,并且能对 API 的结构有非常清晰的认识。
Pinpoint 的代码封装也是非常好的,尤其是针对字节码注入的上层 API 的封装非常出色,但是这依然要求阅读人员对字节码注入多少有一些了解,
虽然其用于注入代码的核心 API 并不多,但要想了解透彻,恐怕还得深入 Agent 的相关代码,
比如很难一目了然的理解 addInterceptor 和 addScopedInterceptor 的区别,而这两个方法就是位于 Agent 的有关类型中。
因为 Brave 的注入需要依赖底层框架提供相关接口,因此并不需要对框架有一个全面的了解,只需要知道能在什么地方注入,能够在注入的时候取得什么数据就可以了。
就像上面的例子,我们根本不需要知道 MySQL 的 JDBC Driver 是如何实现的也可以做到拦截 SQL 的能力。但是 Pinpoint 就不然,因为 Pinpoint 几乎可以在任何地方注入任何代码,
这需要开发人员对所需注入的库的代码实现有非常深入的了解,通过查看其 MySQL 和 Http Client 插件的实现就可以洞察这一点,
当然这也从另外一个层面说明 Pinpoint 的能力确实可以非常强大,而且其默认实现的很多插件已经做到了非常细粒度的拦截。
针对底层框架没有公开 API 的时候,其实 Brave 也并不完全无计可施,我们可以采取 AOP 的方式,一样能够将相关拦截注入到指定的代码中,
而且显然 AOP 的应用要比字节码注入简单很多。
以上这些直接关系到实现一个监控的成本,在 Pinpoint 的官方技术文档中,给出了一个参考数据。如果对一个系统集成的话,那么用于开发 Pinpoint 插件的成本是 100,将此插件集成入系统的成本是 0;
但对于 Brave,插件开发的成本只有 20,而集成成本是 10。从这一点上可以看出官方给出的成本参考数据是 5:1。
但是官方又强调了,如果有 10 个系统需要集成的话,那么总成本就是 10 * 10 + 20 = 120,就超出了 Pinpoint 的开发成本 100,而且需要集成的服务越多,这个差距就越大。
- 通用性和扩展性
很显然,这一点上 Pinpoint 完全处于劣势,从社区所开发出来的集成接口就可见一斑。
Pinpoint 的数据接口缺乏文档,而且也不太标准(参考论坛讨论帖),需要阅读很多代码才可能实现一个自己的探针(比如 Node 的或者 PHP 的)。
而且团队为了性能考虑使用了 Thrift 作为数据传输协议标准,比起 HTTP 和 JSON 而言难度增加了不少。
- 社区支持
这一点也不必多说,Zipkin 由 Twitter 开发,可以算得上是明星团队,而 Naver 的团队只是一个默默无闻的小团队(从 #1759 的讨论中可以看出)。
虽然说这个项目在短期内不太可能消失或停止更新,但毕竟不如前者用起来更加放心。
而且没有更多社区开发出来的插件,让 Pinpoint 只依靠团队自身的力量完成诸多框架的集成实属困难,而且他们目前的工作重点依然是在提升性能和稳定性上。
- 其他
Pinpoint 在实现之初就考虑到了性能问题,www.naver.com 网站的后端某些服务每天要处理超过 200 亿次的请求,因此他们会选择 Thrift 的二进制变长编码格式、
而且使用 UDP 作为传输链路,同时在传递常量的时候也尽量使用数据参考字典,传递一个数字而不是直接传递字符串等等。
这些优化也增加了系统的复杂度:包括使用 Thrift 接口的难度、UDP 数据传输的问题、以及数据常量字典的注册问题等等。
相比之下,Zipkin 使用熟悉的 Restful 接口加 JSON,几乎没有任何学习成本和集成难度,只要知道数据传输结构,就可以轻易的为一个新的框架开发出相应的接口。
另外 Pinpoint 缺乏针对请求的采样能力,显然在大流量的生产环境下,不太可能将所有的请求全部记录,这就要求对请求进行采样,以决定什么样的请求是我需要记录的。
Pinpoint 和 Brave 都支持采样百分比,也就是百分之多少的请求会被记录下来。但是,除此之外 Brave 还提供了 Sampler 接口,可以自定义采样策略,尤其是当进行 A/B 测试的时候,这样的功能就非常有意义了。
- 总结
从短期目标来看,Pinpoint 确实具有压倒性的优势:无需对项目代码进行任何改动就可以部署探针、追踪数据细粒化到方法调用级别、功能强大的用户界面以及几乎比较全面的 Java 框架支持。
但是长远来看,学习 Pinpoint 的开发接口,以及未来为不同的框架实现接口的成本都还是个未知数。
相反,掌握 Brave 就相对容易,而且 Zipkin 的社区更加强大,更有可能在未来开发出更多的接口。在最坏的情况下,
我们也可以自己通过 AOP 的方式添加适合于我们自己的监控代码,而并不需要引入太多的新技术和新概念。
而且在未来业务发生变化的时候,Pinpoint 官方提供的报表是否能满足要求也不好说,增加新的报表也会带来不可以预测的工作难度和工作量。
1.8 Pinpoint与Skywalking细化比较
首先,上个别人的研究成果,我也是踩着巨人的肩膀继续前进的。
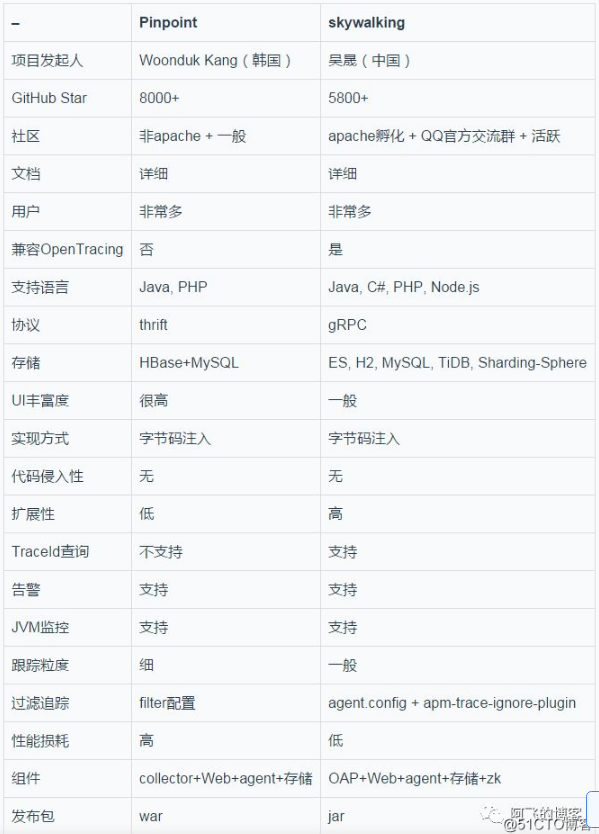
随着pinpoint版本的迭代更新,这图上的结论有些已经过时了,比如pinpoint方面:
- 协议,最新2.2.2版本也是默认使用gRPC的;
- TraceId查询,最新2.2.2版本也是支持的;
- 发布包,最新2.2.2版本同样也是采用jar包部署的;
- 异步跟踪执行,最新2.2.2版本也已经支持了;
接着说我们今天具体要对比的内容:
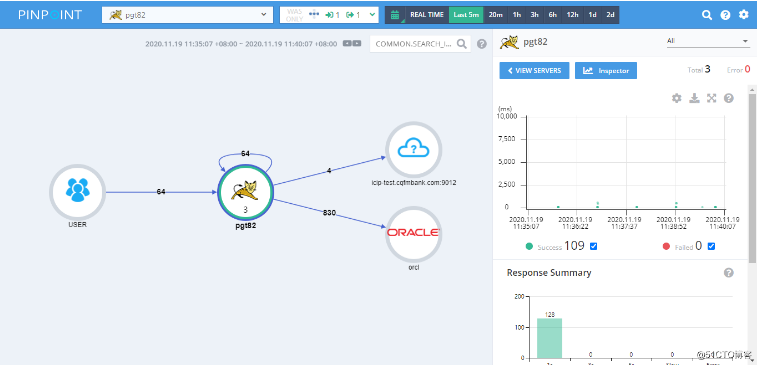
- UI比较
pinpoint的UI看上去更加的美观、友好、方便,pinpoint确实胜skywalking好几分,来两张图,各位看官自己比较。
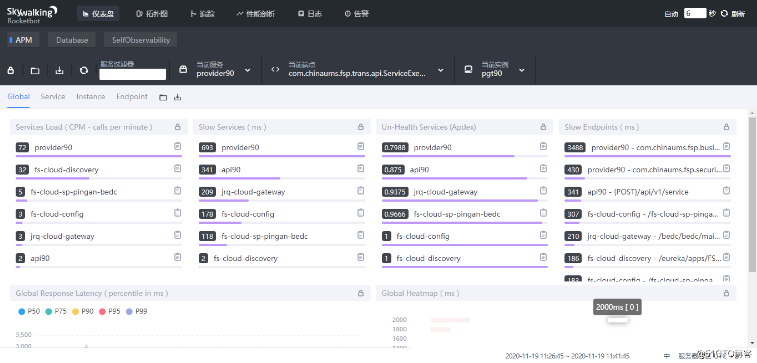
- 跟踪粒度
看完了外观,我们再来对比下它们各自的内功,毕竟这类工具是要干活的,光当花瓶没有用,关键时候得派的上用场才行。
同样,我们先上两张图,来看看pinpoint和skywalking的跟踪粒度如何。
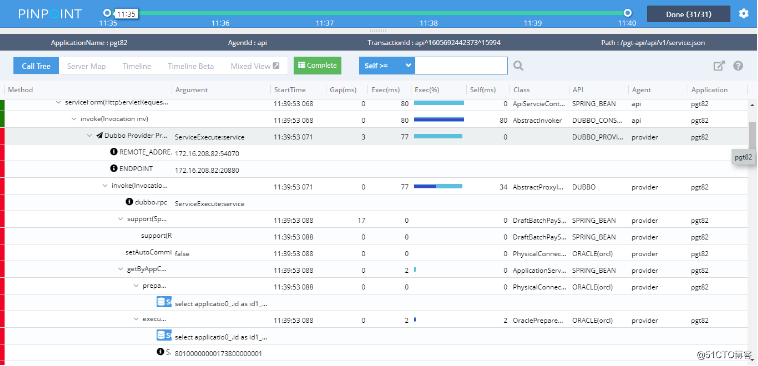
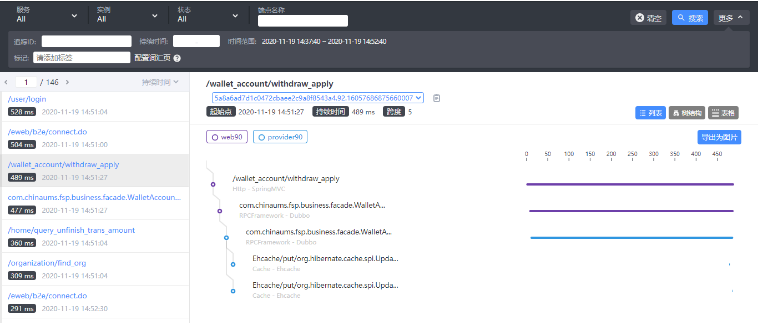
可以看出pinpoint可以监控到每个链路过程的耗时情况,包括SQL执行耗时、第三方服务响应耗时等,甚至连SQL的变量参数都跟踪出来了。
而skywalking只监控到了接口耗时,并没有监控更多一点的链路耗时信息,有群友告知说skywalking能监控到方法级,但是需要侵入代码,在每个要跟踪的方法上面加注解,
所以我直接放弃了,因为这样的代价实在太大了点。而且即使监控到方法级,也只能知道哪个方法慢了,方法下面可能还有数据库调用、第三方方法调用等,还是没法定位出真正的问题。
所以skywalking这款APM监控工具,个人理解,更多地是用来监控接口响应耗时并提出告警,至于具体的性能问题嘛,只能通过其他手段再进一步定位了。
所以,在监控粒度上面,skywalking差pinpoint不是一点半点,这是差了好几个量级啊。
- JVM监控
接下来我们再来对比下这类APM工具的另外一个非常好用的功能,监控JVM。
这边就简单罗列下它们都能监控到那些JVM指标
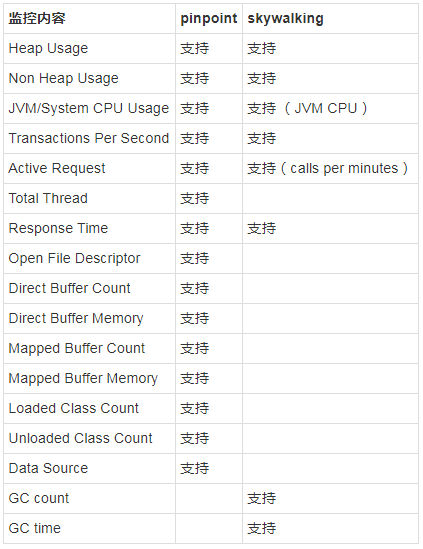
从上面对比结果来看,pinpoint在JVM监控方面要更强大得多,比如对Thread、Open File Descriptor、Data Source的支持,尤其是Data Source,实在是太方便了,数据库连接池的使用情况一目了然。
而skywaling的唯一得分点,是支持GC指标的查看。
- 性能损耗
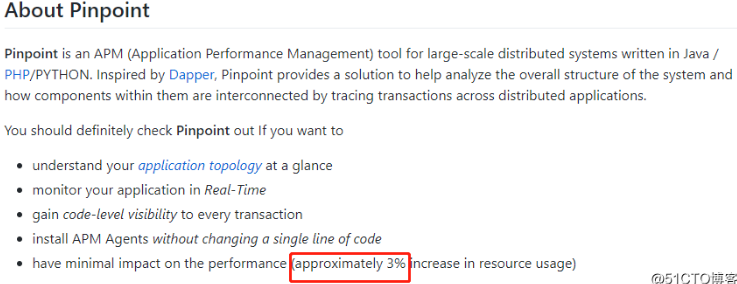
既然pinpoint跟踪粒度比skywalking详细了好几个量级,那么对应地,它的性能损耗是否要大得多呢?翻看有些网友(比如下面参考链接)的测试结果,
pinpoint的性能损耗可以达到50%左右,这也太恐怖了,但是根据官方宣传,它的性能损耗是在3%以内的,那么到底谁是靠谱的呢?
本人平时都是开着APM在做压测的,并没有感觉会有很大的性能损耗,总体损耗应该在8%以内,并且性能测试结果指标还都蛮OK的,所以,对于性能损耗这块,我对pinpoint还是挺有信心的。
贴个官方性能损耗说明:
- 总结
主要从UI、跟踪粒度、JVM监控这三个方面对pinpoint和skywalking做了个人使用体验上的对比,从对比结果来看,pinpoint无论在操作简便性还是性能问题定位上,还是要优胜于skywalking的。
毕竟作为一款APM工具,能够更好更快更全面地发现性能问题,才是它们最大的价值所在。
也可能是我对skywalking了解的还太肤浅,还没发现skywalking真正的强大和美好。各位如果持有不同看法和意见的,欢迎留言探讨。
2. 方案总结
基本
|
方案 |
扩展性 |
实现方式 |
代码侵入性 |
性能损失 |
传输协议 |
客户端支持 | 存储 |
|---|---|---|---|---|---|---|---|
|
skywalking |
中 |
java探针
字节码注入
|
部分侵入(生成TraceId) |
低 |
gRPC | Java, .NET, PHP等 | es,mysql,H2,TIDB |
|
sleuth+zipkin |
高 |
拦截请求 |
侵入(强依赖zipkin) |
中 |
Http,MQ | java,c#,go,php等 | es,mysql,cassandra,内存 |
|
pingpoint |
低 |
java探针
字节码注入
|
无侵入 |
高 |
Thrift,gRPC | java、php | hbase+mysql |
分析
|
方案 |
颗粒度 |
调用链应用拓扑 |
UI丰富程度 | 告警支持 | jvm监控 | trace查询 |
全局调用统计 |
|---|---|---|---|---|---|---|---|
|
skywalking |
方法级 | 服务+中间件 | 中 | 支持 | 支持 | 支持 | 支持 |
|
sleuth+zipkin |
接口级 |
服务 | 低 | 不支持 | 不支持 | 支持 | 不支持 |
|
pingpoint |
代码级 |
服务+中间件 | 高 | 支持 | 支持 | 支持 | 支持 |
引用: