因为公司业务需要,做python开发的我,需要准备前端开发,所以想要做好,必须基础扎实,从基本的做起,我会记录我在学习过程中的学到的知识点。
一、html简介
-html是超文本标记(标签)语言
-它负责网页的三个要素之中的结构
-HTML使用标签的形式来标识网页中的不同组成部分
-所谓超文本指的是超链接,使用超链接可以让我们从一个页面跳转到另一个页面
(1)元素
我们将一个完整的标签称为元素
元素和标签可以认为是一个同义词
根据w3c(万维网联盟,定义了html,dom,xml等标准)标准,一个网页主要由三个部分组成:结构、表现、行为
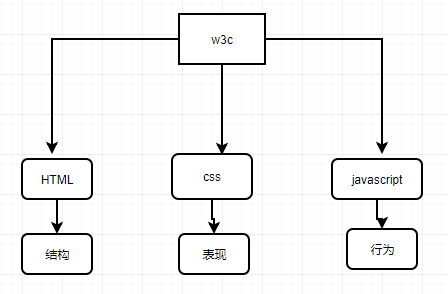
其中分开解释的话:
结构:
-》html用于描述页面的结构
表现
-》css用于控制页面中的元素的样式
行为
-》JavaScript用于响应用户的操作
html两个子标签是head和body,body是网页可见的内容
head=》meta(元素可提供有关页面的元信息(meta-information),比如针对搜索引擎和更新频度的描述和关键词。)和title
body=》h1,div等
html先有实现再有标准
HTML的注释不会在网页上显示,格式为:<!--...-->
根据html的版本。有99htm4l和00年的xhtml和14年的html5
如何让浏览器知道是哪个版本的html呢?
就需要在网页最上边加上doctype
由于xhtm和html4文档说明都太长,太麻烦了,但是我们现在都是用html5,所以HTML5的声明而且简单
HTML5的声明为<!doctype html>
如果不写文档说明,浏览器就会进去一个怪异模式,进入怪异模式之后,浏览器解析页会导致页面无法正常显示,所以避免进入怪异模式,必须写文档说明。
乱码问题:
由于计算机是一个非常笨的机器,它只认识两个东西0和1
在计算中保存的内容最终都要转换为二进制来保存,包括网页中的内容。
编码:是根据一定的规则,将字符转换为二进制编码的过程
解码:依据一定的规则,将二进制编码转换为字符的过程
字符集:编码和解码所采用的规则,我们称之为字符集
常见的字符集:(ASCII(美国),ISO-8859-1(欧洲),GBK(中国),GB2312(中国,中文系统默认的编码),UTF-8(现在是万国码,差不多很多国家都可以使用,所以一般都是用这个))
在中文系统的浏览器中,默认都是使用GB2312进行解码的。
所以需要告诉浏览器解码的字符集是什么,meta就是用来设置网页的元数据,比如网页的字符集,关键字和简介
meta是一个自结束标签,编写自结束标签时,可以在开始标签中添加一个/
具体实现<meta charset='utf-8'>
产生乱码的根本原因,编码和解码采用的字符集不同