摘要:这篇文章主要向大家介绍深度学习分类任务评价指标,主要内容包括基础应用、实用技巧、原理机制等方面,希望对大家有所帮助。
本文分享自华为云社区《深度学习分类任务常用评估指标》,原文作者:lutianfei 。
这篇文章主要向大家介绍深度学习分类任务评价指标,主要内容包括基础应用、实用技巧、原理机制等方面,希望对大家有所帮助。
分类模型
混淆矩阵
sklearn实现:
sklearn.metrics.confusion_matrix(y_true, y_pred, labels=None) 返回值:一个格式化的字符串,给出了分类结果的混淆矩阵。 参数:参考classification_report 。 混淆矩阵的内容如下,其中Cij表示真实标记为i但是预测为j的样本的数量。 Confusion Matrix: [[5 0] [3 2]] def calc_confusion_matrix(y_true: list, y_pred: list, show=True, save=False, figsize=(16, 16), verbose=False): """ 计算混淆矩阵 :param y_true: :param y_pred: :param show: :param save: :param figsize: :param verbose: :return: """ confusion = confusion_matrix(y_true, y_pred) if verbose: print(confusion) if show: show_confusion_matrix(confusion, figsize=figsize, save=save) return confusion def show_confusion_matrix(confusion, classes=MY_CLASSES, x_rot=-60, figsize=None, save=False): """ 绘制混淆矩阵 :param confusion: :param classes: :param x_rot: :param figsize: :param save: :return: """ if figsize is not None: plt.rcParams['figure.figsize'] = figsize plt.imshow(confusion, cmap=plt.cm.YlOrRd) indices = range(len(confusion)) plt.xticks(indices, classes, rotation=x_rot, fontsize=12) plt.yticks(indices, classes, fontsize=12) plt.colorbar() plt.xlabel('y_pred') plt.ylabel('y_true') # 显示数据 for first_index in range(len(confusion)): for second_index in range(len(confusion[first_index])): plt.text(first_index, second_index, confusion[first_index][second_index]) if save: plt.savefig("./confusion_matrix.png") plt.show()
混淆矩阵是监督学习中的一种可视化工具,主要用于比较分类结果和实例的真实信息。矩阵中的每一行代表实例的预测类别,每一列代表实例的真实类别。
理解方法:
P(positive):预测为正样本
N(Negative):预测为负样本
T(True):预测正确
F(False):预测错误
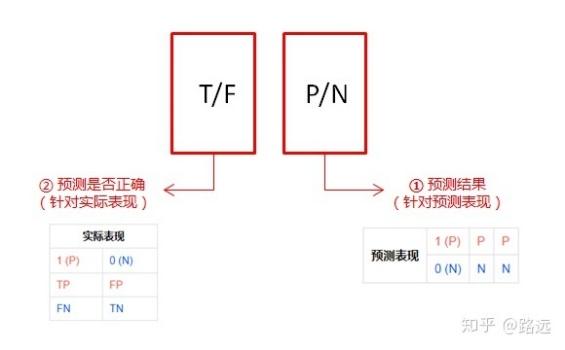
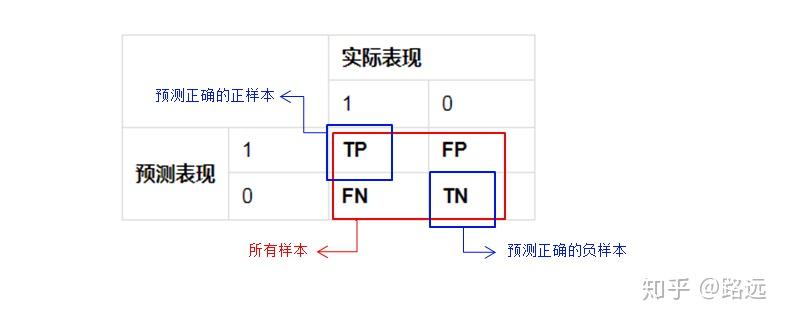
- 真正(True Positive, TP): 被模型预测为正的正样本。预测为1,预测正确,即实际1
- 假正(False Positive, FP): 被模型预测为正的负样本。预测为1,预测错误,即实际0
- 假负(False Negative, FN): 被模型预测为负的正样本。预测为0,预测错确,即实际1
- 真负(True Negative, TN): 被模型预测为负的负样本。预测为0,预测正确即,实际0
真正率(True Positive Rate, TPR)或灵敏率(sensitivity)
TPR= TP/(TP+FN) -> 正样本预测结果数/正样本实际数
由上述公式可知TPR等价于Recall

真负率(True Negative Rate, TNR)或 特指度/特异度(specificity)
TNR=TN/(TN+FP) -> 负样本预测结果数/负样本实际数
假正率(False Positive Rate, FPR)
FPR = FP/(FP+TN) -> 被预测为正的负样本结果数/负样本实际数
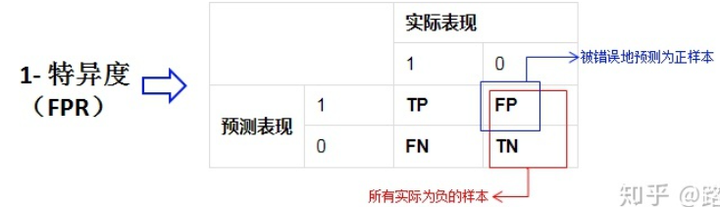
假负率(False Negative Rate, FNR)
FNR = FN/(TP+FN) -> 被预测为负的正样本结果数/正样本实际数
准确率(正确率,Accuracy)
也称正确率,预测正确的结果占总样本的百分比,最常用的分类性能指标。
公式:Accuracy = (TP+TN)/(TP+FN+FP+FN)
缺点:样本不均衡时有局限性,
例如:当负样本占99%时,分类器把所有样本都预测为负样本也可以获得99%的准确率。所以,当不同类别的样本比例非常不均衡时,占比大的类别往往成为影响准确率的最主要因素。
sklearn实现:
from sklearn.metrics import accuracy_score accuracy_score(y_true, y_pred, normalize=True, sample_weight=None) 返回值:如果normalize为True,则返回准确率;如果normalize为False,则返回正确分类的数量。 参数: y_true:真实的标记集合。 y_pred:预测的标记集合。 normalize:一个布尔值,指示是否需要归一化结果。 如果为True,则返回分类正确的比例(准确率)。 如果为False,则返回分类正确的样本数量。 sample_weight:样本权重,默认每个样本的权重为 1 。 # 方法封装 def calc_accuracy_score(y_true: list, y_pred: list, verbose=False): res = accuracy_score(y_true, y_pred) if verbose: print("accuracy:%s" % res) return res
错误率(Error rate)
即,错误预测的正反例数/总数。
正确率与错误率是分别从正反两方面进行评价的指标,两者数值相加刚好等于1。
ErrorRate = (FP+FN)/(TP+FN+FP+TN)
精确率(查准率,Precision)
精准率(Precision)又叫查准率,它是针对预测结果而言的,它的含义是在所有被预测为正的样本中实际为正的样本的概率,意思就是在预测为正样本的结果中,我们有多少把握可以预测正确,其公式如下:
Precision = TP/(TP+FP)
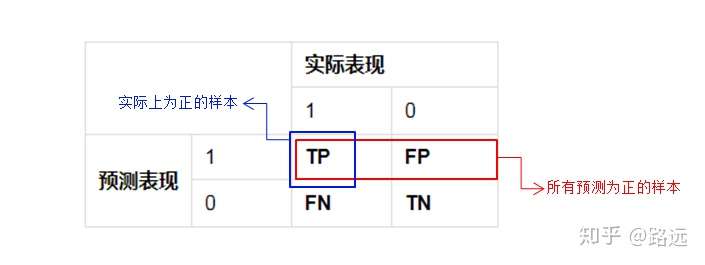
缺点:预测的结果只有1例正例,并且是正确的,精准率为100%。实际又很多预测错误的负例,即真实的正例。
场景:预测股票会涨,真实涨了10次,只预测到了两次会涨,预测这两次都对了,那么就是我们想要的精准度高,此时召回率不重要。
sklearn实现:
from sklearn.metrics import precision_score sklearn.metrics.precision_score(y_true, y_pred, labels=None, pos_label=1, average='binary', sample_weight=None) 返回值:查准率。即预测结果为正类的那些样本中,有多少比例确实是正类。 参数: y_true:真实的标记集合。 y_pred:预测的标记集合。 labels:一个列表。当average 不是'binary' 时使用。 对于多分类问题,它表示:将计算哪些类别。不在labels 中的类别,计算macro precision 时其成分为 0 。 对于多标签问题,它表示:待考察的标签的索引。 除了average=None 之外,labels 的元素的顺序也非常重要。 默认情况下,y_true 和 y_pred 中所有的类别都将被用到。 pos_label:一个字符串或者整数,指定哪个标记值属于正类。 如果是多分类或者多标签问题,则该参数被忽略。 如果设置label=[pos_label] 以及average!='binary' 则会仅仅计算该类别的precision 。 average:一个字符串或者None,用于指定二分类或者多类分类的precision 如何计算。 'binary':计算二类分类的precision。 此时由pos_label 指定的类为正类,报告其precision 。 它要求y_true、y_pred 的元素都是0,1 。 'micro':通过全局的正例和负例,计算precision 。 'macro':计算每个类别的precision,然后返回它们的均值。 'weighted':计算每个类别的precision,然后返回其加权均值,权重为每个类别的样本数。 'samples':计算每个样本的precision,然后返回其均值。该方法仅仅对于多标签分类问题有意义。 None:计算每个类别的precision,然后以数组的形式返回每个precision 。 sample_weight:样本权重,默认每个样本的权重为 1 # 方法封装 def calc_precision_score(y_true: list, y_pred: list, labels=MY_CLASSES, average=None, verbose=False): res = precision_score(y_true, y_pred, labels=labels, average=average) if verbose: print("precision:%s" % res) return res
召回率(查全率,Recall)
召回率(Recall)又叫查全率,它是针对原样本而言的,它的含义是在实际为正的样本中被预测为正样本的概率,其公式如下:
Recall = TP/(TP+FN)

缺点:都预测为正例时也会覆盖所有真实的正例,召回率也为100%。
召回率的应用场景:比如拿网贷违约率为例,相对好用户,我们更关心坏用户,不能错放过任何一个坏用户。因为如果我们过多的将坏用户当成好用户,这样后续可能发生的违约金额会远超过好用户偿还的借贷利息金额,造成严重偿失。召回率越高,代表实际坏用户被预测出来的概率越高,它的含义类似:宁可错杀一千,绝不放过一个。
sklearn实现:
from sklearn.metrics import recall_score sklearn.metrics.recall_score(y_true, y_pred, labels=None, pos_label=1,average='binary', sample_weight=None) 返回值:查全率。即真实的正类中,有多少比例被预测为正类。 参数:参考precision_score。 # 方法封装 def calc_recall_score(y_true: list, y_pred: list, labels=MY_CLASSES, average=None, verbose=False): res = recall_score(y_true, y_pred, labels=labels, average=average) if verbose: print("recall: %s" % res) return res
下图正精确率和召回率做了进一步说明
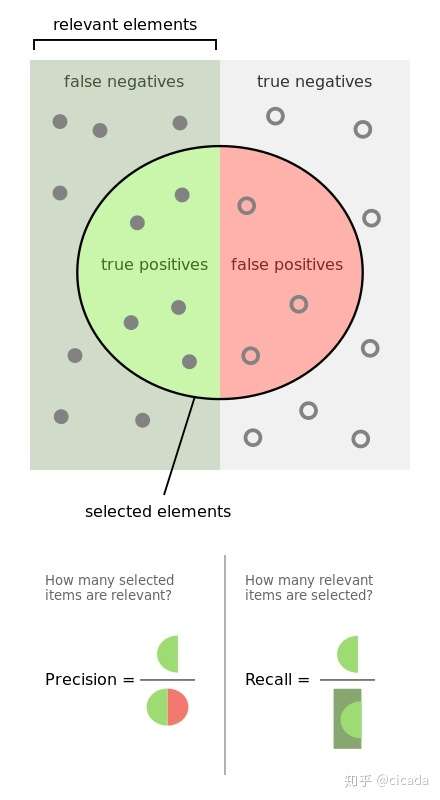
PR曲线
通过精确率和召回率的公式可知:精准率和召回率的分子是相同,都是TP,但分母是不同的,一个是(TP+FP),一个是(TP+FN)。两者的关系可以用一个P-R图来展示:

分类模型的最后输出往往是一个概率值,我们一般需要把概率值转换为具体的类别,对于二分类来说,我们设置一个阈值(threshold),然后大于此阈值判定为正类,反之负类。上述评价指标(Accuracy、Precision、Recall)都是针对某个特定阈值来说的,那么当不同模型取不同阈值时,如何全面的评价不同模型?因此这里需要引入PR曲线,即Precision-Recall曲线来进行评估。
为了找到一个最合适的阈值满足我们的要求,我们就必须遍历0到1之间所有的阈值,而每个阈值下都对应着一对查准率和查全率,从而我们就得到了这条曲线。
如下图所示,纵坐标是精确率P,横坐标是召回率R。对于一个模型来说,
其P-R曲线上的一个点代表着,在某一阈值下,模型将大于该阈值的结果判定为正样本,小于该阈值的结果判定为负样本,
此时返回结果对应一对儿召回率和精确率,作为PR坐标系上的一个坐标。
整条P-R曲线是通过将阈值从高到低移动而生成的。P-R曲线越靠近右上角(1,1)代表模型越好。在现实场景,需要根据不同决策要求综合判断不同模型的好坏。
评价标准:
先看平滑不平滑(越平滑越好)。一般来说,在同一测试集,上面的比下面的好(绿线比红线好)。当P和R的值接近时F1值最大。此时画连接(0,0)和(1,1)的线。线和PR曲线重合的地方F1值最大。此时的F1对于PR曲线就相当于AUC对于ROC一样。
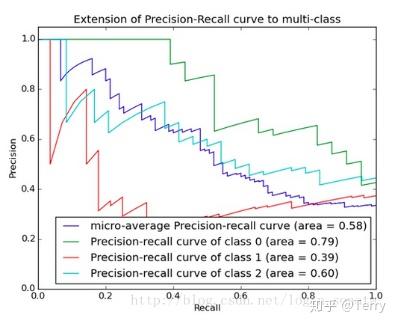
PR曲线下的面积称为AP(Average
Precision),表示召回率从0-1的平均精度值。AP可用积分进行计算。AP面积不会大于1。PR曲线下的面积越大,模型性能越好。
所谓性能优的模型应该是在召回率增长的同时保持精确度在一个较高水平。
sklearn实现:
sklearn.metrics.precision_recall_curve(y_true, probas_pred, pos_label=None, sample_weight=None) 返回值:一个元组,元组内的元素分别为: P-R曲线的查准率序列。该序列是递增序列,序列第 i 个元素是当正类概率的判定阈值为 thresholds[i]时的查准率。 P-R曲线的查全率序列。该序列是递减序列,序列第 i 个元素是当正类概率的判定阈值为 thresholds[i]时的查全率。 P-R曲线的阈值序列thresholds。该序列是一个递增序列,给出了判定为正例时的正类概率的阈值。 参数: y_true:真实的标记集合。 probas_pred:每个样本预测为正类的概率的集合。 pos_label:正类的类别标记。 sample_weight:样本权重,默认每个样本的权重为 1。 def calc_precision_recall_curve(class_info, class_name=None, show=True, save=False, verbose=False): """ 计算PR曲线 :param class_info: :param class_name: :param show: :param save: :param verbose: :return: """ precision, recall, thresholds = precision_recall_curve(class_info['gt_lbl'], class_info['score']) if verbose: print("%s precision:%s " % (class_name, precision,)) print("%s recall:%s " % (class_name, recall,)) print("%s thresholds:%s " % (class_name, thresholds,)) if show: show_PR_curve(recall, precision, class_name) return precision, recall, thresholds
PR曲线绘制方法:
def show_PR_curve(recall, precision, class_name=None, save=False): """ 绘制PR曲线 :param recall: :param precision: :param class_name: :param save: :return: """ plt.figure("%s P-R Curve" % class_name) plt.title('%s Precision/Recall Curve' % class_name) plt.xlabel('Recall') plt.ylabel('Precision') plt.plot(recall, precision) if save: plt.savefig("./%s_pr_curve.png") plt.show()
F1 score 调和平均值
F1
Score又称F-Measure,是精确率和召回率的调和值,更接近于两个数较小的那个,所以精确率和召回率接近时F1值最大。很多推荐系统的评测指标就是用F1
Score。
Precision和Recall是既矛盾又统一的两个指标, 为了提高Precision值,
分类器需要尽量在“更有把握”时才把样本预测为正样本,
但此时往往会因为过于保守而漏掉很多“没有把握”的正样本,
导致Recall值降低。那么当不同模型的Recall和Precision各有优势时该如何选择模型?如果想要找到二者之间的一个平衡点,我们就需要一个新的指标:F1分数。F1分数同时考虑了查准率和查全率,让二者同时达到最高,取一个平衡。F1分数的公式为
= 2*查准率*查全率 / (查准率 +
查全率)。我们在PR曲线图1中看到的平衡点就是F1分数得来的结果。
即
在现实场景,如果两个模型,一个precision特别高,recall特别低,另一个recall特别高,precision特别低的时候,f1-score可能是差不多的,可能不能通过一个f1
socre做出最终判断,此时就需要根据不同场景选择其他合适的指标做出评判。
sklearn实现:
from sklearn.metrics import f1_score #调和平均值F1 f1_score(y_true, y_pred, labels=None, pos_label=1, average='binary', sample_weight=None) 返回值: 值。即查准率和查全率的调和均值。 参数:参考precision_score。 #方法封装 def calc_f1_score(y_true: list, y_pred: list, labels=MY_CLASSES, average=None, verbose=False): res = f1_score(y_true, y_pred, labels=labels, average=average) if verbose: print("f1_score: %s" % res) return res
ROC曲线
ROC(Receiver Operating
Characteristic-受试者工作特征曲线,又称感受性曲线),用图形来描述二分类模型的性能表现,是一个全面评估模型的指标。
ROC和AUC可以无视样本不平衡的原因是:灵敏度和(1-特异度),也叫做真正率(TPR)和假正率(FPR)。由于TPR和FPR分别是基于实际表现1和0出发的,也就是说它们分别在实际的正样本和负样本中来观察相关概率问题。正因为如此,所以无论样本是否平衡,都不会被影响。
例如:总样本中,90%是正样本,10%是负样本。我们知道用准确率是有水分的,但是用TPR和FPR不一样。这里,TPR只关注90%正样本中有多少是被真正覆盖的,而与那10%毫无关系,同理,FPR只关注10%负样本中有多少是被错误覆盖的,也与那90%毫无关系,所以可以看出:如果我们从实际表现的各个结果角度出发,就可以避免样本不平衡的问题了,这也是为什么选用TPR和FPR作为ROC/AUC的指标的原因。
X轴:假正率(FPR),模型预测为假的正例在真实负例的占比。错误判断的正类占所有负类的比例,医学上等价于误诊率。
Y轴:真正率(TPR),模型预测为真的正例在真实正例的占比。
ROC 曲线离对角线越近,模型的准确率越低。
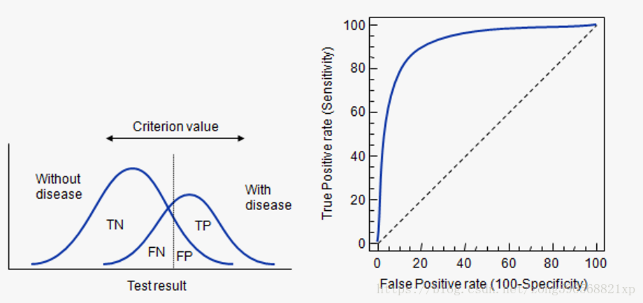
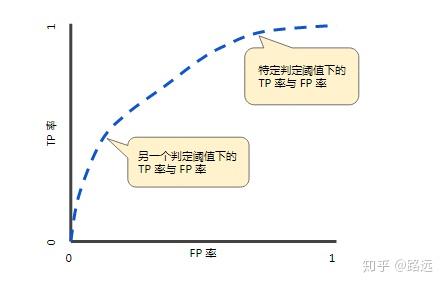
曲线说明:
ROC曲线是通过不同阈值下的FPR和TPR坐标所得到的。具体来说,通过动态地调整模型概率阈值(概率阈值的意思是模型多大概率判定为正类),
从最高的值开始( 比如1, 对应着ROC曲线的零点) , 逐渐调整到最低概率值,
每一个概率值都会对应一个FPR和TPR, 在ROC图上绘制出每个概率值对应的位置,
再连接所有点就得到最终的ROC曲线。
曲线特征:
- 通过调整判断分类的阈值(逻辑回归默认阈值0.5),TPR和FPR随之改变,进而在ROC曲线坐标上形成多个点,反应模型分类效果。
- TPR增长越快,同时FPR越低,曲线越凸,模型的分类性能越好,即预测为正确的正例越多。
- ROC曲线比过(0,0), (1,0)两点。原因:
逻辑回归模型默认阈值为0.5,sigmoid()结果即类别概率p默认≥0.5时,模型预测为类别1(正例)。那么修改阈值为0时,p≥0模型预测为类别1(正例),说明该模型该阈值下会将所有数据均预测为类别1(无论对错),此时FN=TN=0个,TPR=FPR=1
修改阈值为1时,p≥1模型预测为类别1(正例),p是不可能大于100%的,说明该模型该阈值下会将所有数据均预测为类别0(无论对错),此时FP=TP=0个,TPR=FPR=0
sklearn实现:
roc_curve函数用于计算分类结果的ROC曲线。其原型为: sklearn.metrics.roc_curve(y_true, y_score, pos_label=None, sample_weight=None, drop_intermediate=True) 返回值:一个元组,元组内的元素分别为: ROC曲线的FPR序列。该序列是递增序列,序列第 i 个元素是当正类概率的判定阈值为 thresholds[i]时的假正例率。 ROC曲线的TPR序列。该序列是递增序列,序列第 i 个元素是当正类概率的判定阈值为 thresholds[i]时的真正例率。 ROC曲线的阈值序列thresholds。该序列是一个递减序列,给出了判定为正例时的正类概率的阈值。 参数: y_true:真实的标记集合。 y_score:每个样本预测为正类的概率的集合。 pos_label:正类的类别标记。 sample_weight:样本权重,默认每个样本的权重为 1。 drop_intermediate:一个布尔值。如果为True,则抛弃某些不可能出现在ROC曲线上的阈值。 #方法封装 def calc_roc_curve(class_info, class_name=None, show=True, save=False, verbose=False): """ 计算roc曲线 :param class_info: :param class_name: :param show: :param save: :param verbose: :return: """ fpr, tpr, thresholds = roc_curve(class_info['gt_lbl'], class_info['score'], drop_intermediate=True) if verbose: print("%s fpr:%s " % (class_name, fpr,)) print("%s tpr:%s " % (class_name, tpr,)) print("%s thresholds:%s " % (class_name, thresholds,)) if show: auc_score = calc_auc_score(fpr, tpr) show_roc_curve(fpr, tpr, auc_score, class_name) return fpr, tpr, thresholds
ROC曲线绘制方法:
def show_roc_curve(fpr, tpr, auc_score, class_name=None, save=False): plt.figure("%s ROC Curve" % class_name) plt.title('%s ROC Curve' % class_name) plt.xlabel('False Positive Rate') # 横坐标是fpr plt.ylabel('True Positive Rate') # 纵坐标是tpr plt.plot(fpr, tpr, 'b', label='AUC = %0.2f' % auc_score) plt.legend(loc='lower right') plt.plot([0, 1], [0, 1], 'r--') plt.xlim([-0.1, 1.1]) plt.ylim([-0.1, 1.1]) if save: plt.savefig("./%s_auc_curve.png") plt.show()
AUC(ROC曲线的面积)
AUC (Area Under Curve
被定义为ROC曲线下的面积,显然这个面积的数值不会大于1。又由于ROC曲线一般都处于y=x这条直线的上方,所以AUC的取值范围一般在0.5和1之间。使用AUC值作为评价标准是因为很多时候ROC曲线并不能清晰的说明哪个分类器的效果更好,而作为一个数值,对应AUC更大的分类器效果更好。
sklearn实现:
roc_auc_score函数用于计算分类结果的ROC曲线的面积AUC。其原型为: sklearn.metrics.roc_auc_score(y_true, y_score, average='macro', sample_weight=None) 返回值:AUC值。 参数:参考 roc_curve。 #也可以通过如下方法计算得到 def calc_auc_score(fpr, tpr, verbose=False): res = auc(fpr, tpr) if verbose: print("auc:%s" % res) return res
AUC的计算有两种方式: 梯形法和ROC
AUCH法,都是以逼近法求近似值,具体见wikipedia。
从AUC判断分类器(预测模型)优劣的标准:
- AUC =
1,是完美分类器,采用这个预测模型时,存在至少一个阈值能得出完美预测。绝大多数预测的场合,不存在完美分类器。 - 0.5 < AUC <
1,优于随机猜测。这个分类器(模型)妥善设定阈值的话,能有预测价值。 - AUC = 0.5,跟随机猜测一样(例:丢铜板),模型没有预测价值。
- AUC < 0.5,比随机猜测还差;但只要总是反预测而行,就优于随机猜测。
三种AUC值示例:
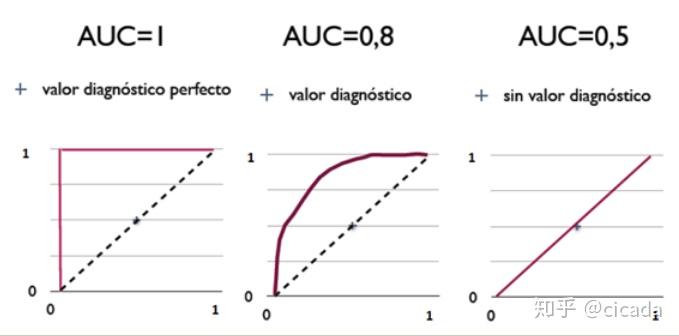
简单说:AUC值越大的分类器,正确率越高。
注:TPR、FPR、Precision、Recall的定义来对比,TPR、Recall的分母为样本中正类的个数,FPR的分母为样本中负类的个数,样本一旦确定分母即为定值,因此三个指标的变化随分子增加单调递增。但是Precision的分母为预测为正类的个数,会随着阈值的变化而变化,因此Precision的变化受TP和FP的综合影响,不单调,变化情况不可预测。
多类别情况下ROC-AUC曲线绘制方法
def show_roc_info(classdict, show=True, save=False, figsize=(30, 22), fontsize=12): """ 多类别情况下计算展示每个类别的roc-auc图 :param classdict: :param show: :param save: :param figsize: :param fontsize: :return: """ def sub_curve(fpr, tpr, auc_score, class_name, sub_idx): plt.subplot(6, 5, sub_idx) plt.title('%s ROC Curve' % class_name) plt.xlabel('False Positive Rate') # 横坐标是fpr plt.ylabel('True Positive Rate') # 纵坐标是tpr plt.plot(fpr, tpr, 'b', label='AUC = %0.2f' % auc_score) plt.legend(loc='lower right') plt.plot([0, 1], [0, 1], 'r--') plt.xlim([-0.1, 1.1]) plt.ylim([-0.1, 1.1]) if show: plt.figure("Maoyan video class AUC Curve", figsize=figsize) plt.subplots_adjust(bottom=0.02, right=0.98, top=0.98) for idx, cls in enumerate(MY_CLASSES): if cls in classdict: fpr, tpr, thresholds = calc_roc_curve(classdict[cls], class_name=cls, show=False) auc_score = calc_auc_score(fpr, tpr) print("%s auc: %.4f" % (cls, auc_score)) if show: sub_curve(fpr, tpr, auc_score, cls, idx + 1) else: print("%s auc: 0" % cls) sub_curve([0], [0], 0, cls, idx + 1) if save: plt.savefig("./maoyan_all_auc_curve.png") if show: plt.show()
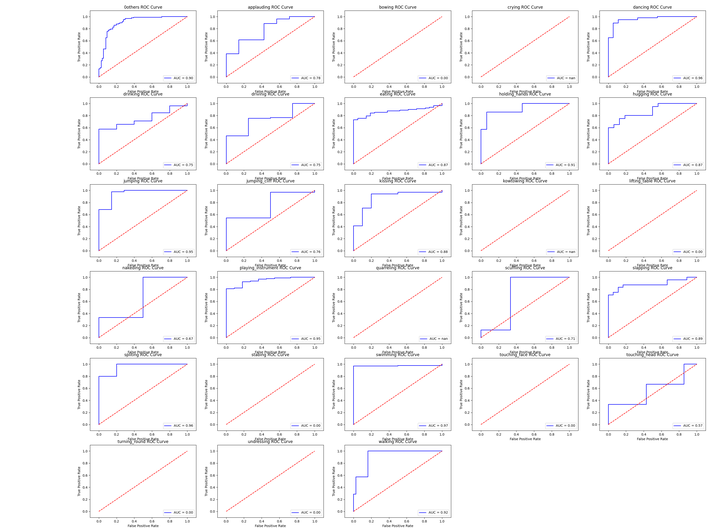
实际使用技巧
对于ROC,一般来说,如果ROC是光滑的,那么基本可以判断没有太大的overfitting(比如图中0.2到0.4可能就有问题,但是样本太少了),这个时候调模型可以只看AUC,面积越大一般认为模型越好。
对于PRC(precision recall
curve)和ROC一样,先看平滑不平滑(蓝线明显好些),再看谁上谁下(同一测试集上),一般来说,上面的比下面的好(绿线比红线好)。当P和R越接近F1就越大,一般连接(0,0)和(1,1)的线和PRC重合的地方的F1是这条线最大的F1(光滑的情况下),此时的F1对于PRC就好象AUC对于ROC一样。一个数字比一条线更方便调模型。
AP
严格的AP就是PR曲线下的面积,mAP就是所有类AP的算术平均。
但是一般都是用逼近的方法去估计这个面积。
sklearn实现:
sklearn.metrics.average_precision_score(y_true, y_score, average=‘macro’, sample_weight=None) 注意:此实现仅限于二进制分类任务或多标签分类任务。 参数: y_true : array, shape = [n_samples] or [n_samples, n_classes] 真实标签:取0和1 y_score : array, shape = [n_samples] or [n_samples, n_classes] 预测标签:[0,1]之间的值。 可以是正类的概率估计、置信值,也可以是决策的非阈值度量(如某些分类器上的“决策函数”返回的) average : string, [None, ‘micro’, ‘macro’ (default), ‘samples’, ‘weighted’] sample_weight : array-like of shape = [n_samples], optional sample weights. #方法封装 def calc_AP_score(class_info, class_name=None, average="macro", verbose=True): res = average_precision_score(class_info['gt_lbl'], class_info['score'], average=average) if verbose: print("%s ap: %.4f" % (class_name, res)) return res
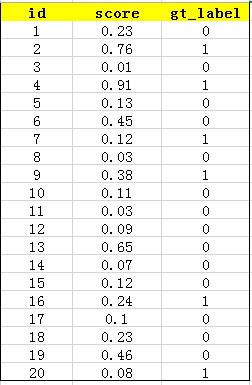
AP计算方法
首先用训练好的模型得到所有测试样本的confidence
score,假设某类共有20个测试样本,每个的id,confidence score和ground truth
label如下:
接着对confidence score排序得到:

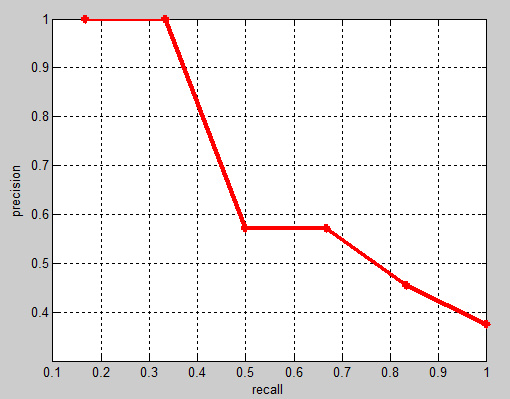
计算出TopN对应Recall和precision。其中,对于某个recall值r,precision值取所有recall
>=r 中的最大值(这样保证了p-r曲线是单调递减的,避免曲线出现摇摆)这种方法叫做all-points-interpolation。这个AP值也就是PR曲线下的面积值。

例如:top5的recall=2/6, precision=2/5=0.4,当recall>=2/6时precision最大为1。
top6的recall=3/6, precision=3/6,在所有recall>=3/6时precision最大为4/7。
此时
AP=1*(1/6) + 1*(1/6)+ (4/7)*(1/6) + (4/7)*(1/6) + (5/11)*(1/6) + (6/16)* (1/6) = 0.6621
相应的Precision-Recall曲线(这条曲线是单调递减的)如下:
mAP
mean Average Precision, 即各类别AP的平均值
用上述方法分别算出各个类的AP,然后取平均,就得到mAP了。mAP的好处是可以防止AP
bias到某一个数量较多的类别上去。
sklearn实现:
#mAP计算封装 def calc_mAP_score(classdict, verbose=True): AP = [] for cls in MY_CLASSES: if cls in classdict: AP.append(calc_AP_score(classdict[cls], cls)) else: print("%s ap: 0" % cls) AP.append(0) mAP_score = np.mean(AP) if verbose: print("mAP:%s" % mAP_score) return mAP_score
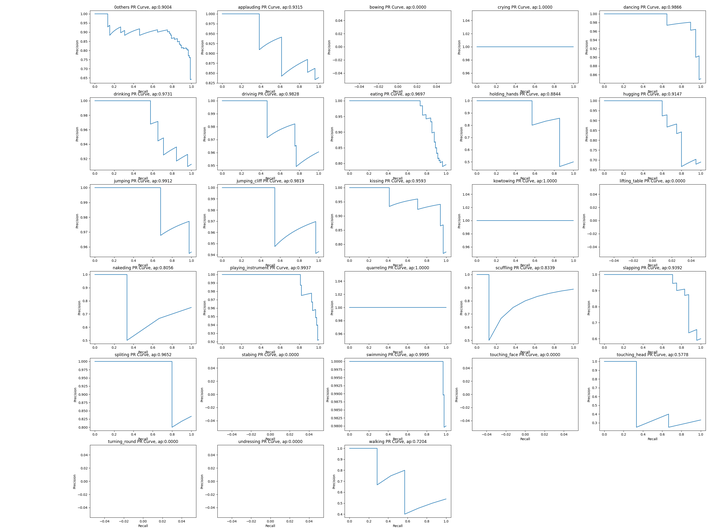
多类别情况下计算展示每个类别的pr图及对应的AP值
def show_mAP_info(classdict, show=True, save=False, figsize=(30, 22), fontsize=12): """ 多类别情况下计算展示每个类别的pr图及对应的AP值 :param classdict: :param show: :param save: :param figsize: :param fontsize: :return: """ def sub_curve(recall, precision, class_name, ap_score, sub_idx): plt.subplot(6, 5, sub_idx) plt.title('%s PR Curve, ap:%.4f' % (class_name, ap_score)) plt.xlabel('Recall') plt.ylabel('Precision') plt.plot(recall, precision) AP = [] if show: plt.figure("Maoyan video class P-R Curve", figsize=figsize) plt.subplots_adjust(bottom=0.02, right=0.98, top=0.98) for idx, cls in enumerate(MY_CLASSES): if cls in classdict: ap_score = calc_AP_score(classdict[cls], cls) precision, recall, thresholds = calc_precision_recall_curve(classdict[cls], class_name=cls, show=False) if show: sub_curve(recall, precision, cls, ap_score, idx + 1) else: ap_score = 0 print("%s ap: 0" % cls) sub_curve([0], [0], cls, ap_score, idx + 1) AP.append(ap_score) if save: plt.savefig("./maoyan_all_ap_curve.png") if show: plt.show() mAP_score = np.mean(AP) print("mAP:%s" % mAP_score) return mAP_score
多类别情况下获取所需标签信息的方法
def get_simple_result(df: DataFrame): y_true = [] y_pred = [] pred_scores = [] for idx, row in df.iterrows(): video_path = row['video_path'] gt_label = video_path.split("/")[-2] y_true.append(gt_label) pred_label = row['cls1'] y_pred.append(pred_label) pred_score = row['score1'] pred_scores.append(pred_score) return y_true, y_pred, pred_scores def get_multiclass_result(df: DataFrame): classdict = {} for idx, row in df.iterrows(): video_path = row['video_path'] gt_label = video_path.split("/")[-2] pred_label = row['cls1'] pred_score = row['score1'] if pred_label in classdict: classdict[pred_label]['score'].append(pred_score) classdict[pred_label]['gt_lbl'].append(1 if gt_label == pred_label else 0) else: classdict[pred_label] = {'score': [pred_score], 'gt_lbl': [1 if gt_label == pred_label else 0]} return classdict
对数损失(log_loss)
from sklearn.metrics import log_loss log_loss(y_true,y_pred)
分类指标的文本报告(classification_report)
classification_report函数用于显示主要分类指标的文本报告。在报告中显示每个类的精确度,召回率,F1值等信息。
sklearn实现:
sklearn.metrics.classification_report(y_true, y_pred, labels=None, target_names=None, sample_weight=None, digits=2) 返回值:一个格式化的字符串,给出了分类评估报告。 参数: y_true:真实的标记集合。 y_pred:预测的标记集合。 labels:一个列表,指定报告中出现哪些类别。 target_names:一个列表,指定报告中类别对应的显示出来的名字。 digits:用于格式化报告中的浮点数,保留几位小数。 sample_weight:样本权重,默认每个样本的权重为 1 分类评估报告的内容如下,其中: precision列:给出了查准率。它依次将类别 0 作为正类,类别 1 作为正类... recall列:给出了查全率。它依次将类别 0 作为正类,类别 1 作为正类... F1列:给出了F1值。 support列:给出了该类有多少个样本。 avg / total行: 对于precision,recall,f1给出了该列数据的算术平均。 对于support列,给出了该列的算术和(其实就等于样本集总样本数量)。
使用总结
- 对于分类模型,AUC、ROC曲线(FPR和TPR的点连成的线)、PR曲线(准确率和召回率的点连成的线)是综合评价模型区分能力和排序能力的指标,而精确率、召回率和F1值是在确定阈值之后计算得到的指标。
- 对于同一模型,PRC和ROC曲线都可以说明一定的问题,而且二者有一定的相关性,如果想评测模型效果,也可以把两条曲线都画出来综合评价。
- 对于有监督的二分类问题,在正负样本都足够的情况下,可以直接用ROC曲线、AUC评价模型效果;而在样本极不均衡的情况下,PR曲线更能反应模型效果。
- 在确定阈值过程中,可以根据Precision、Recall或者F1来评价模型的分类效果。对于多分类问题,可以对每一类分别计算Precision、Recall和F1,综合作为模型评价指标。
回归模型
平均绝对误差(MAE mean absolute error)
sklearn实现:
mean_absolute_error函数用于计算回归预测误差绝对值的均值(mean absolute error:MAE),其原型为: sklearn.metrics.mean_absolute_error(y_true, y_pred, sample_weight=None, multioutput='uniform_average') 返回值:预测误差绝对值的均值。 参数: y_true:真实的标记集合。 y_pred:预测的标记集合。 multioutput:指定对于多输出变量的回归问题的误差类型。可以为: 'raw_values':对每个输出变量,计算其误差 。 'uniform_average':计算其所有输出变量的误差的平均值。 sample_weight:样本权重,默认每个样本的权重为 1。
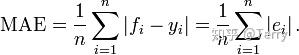
均方误差(MSE mean squared error)
mean_squared_error函数用于计算回归预测误差平方的均值(mean square
error:MSE),其原型为:
sklearn.metrics.mean_squared_error(y_true, y_pred, sample_weight=None, multioutput='uniform_average') 返回值:预测误差的平方的平均值。 参数:参考mean_absolute_error 。
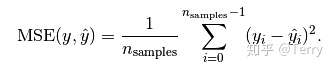
均方根误差(RMSE root mean squared error)
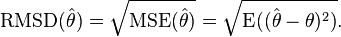
归一化均方根误差(NRMSE normalized root mean squared error)归一化均方根误差
决定系数(R2)
R2是多元回归中的回归平方和占总平方和的比例,它是度量多元回归方程中拟合程度的一个统计量,反映了在因变量y的变差中被估计的回归方程所解释的比例。
R2越接近1,表明回归平方和占总平方和的比例越大,回归线与各观测点越接近,用x的变化来解释y值变差的部分就越多,回归的拟合程度就越好。
from sklearn.metrics import r2_score r2_score(y_true, y_pred, sample_weight=None, multioutput='uniform_average')
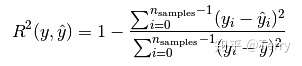
参考以下文章,自己总结的深度学习常用评估指标:
Terry:https://zhuanlan.zhihu.com/p/86120987
cicada:https://zhuanlan.zhihu.com/p/267901426
https://www.pythonf.cn/read/128402
路远: https://www.zhihu.com/question/30643044