摘要:HDFS是MapReduce服务中的基础文件系统,全称为Hadoop的分布式文件系统(Hadoop Distributed File System),可支持实现大规模数据可靠的分布式读写。
本文分享自华为云社区《【云小课】EI第21课 MRS基础入门之HDFS组件介绍》,原文作者:Hi,EI 。

HDFS针对的使用场景是数据读写具有“一次写,多次读”的特征,而数据“写”操作是顺序写,也就是在文件创建时的写入或者在现有文件之后的添加操作。HDFS保证一个文件在一个时刻只被一个调用者执行写操作,而可以被多个调用者执行读操作。
HDFS结构
HDFS是一个Master/Slave的架构,主要包含主、备NameNode和多个DataNode角色。在Master上运行NameNode,而在每一个Slave上运行DataNode,ZKFC需要和NameNode一起运行。
NameNode和DataNode之间的通信都是建立在TCP/IP的基础之上的。NameNode、DataNode、ZKFC和JournalNode能部署在运行Linux的服务器上。
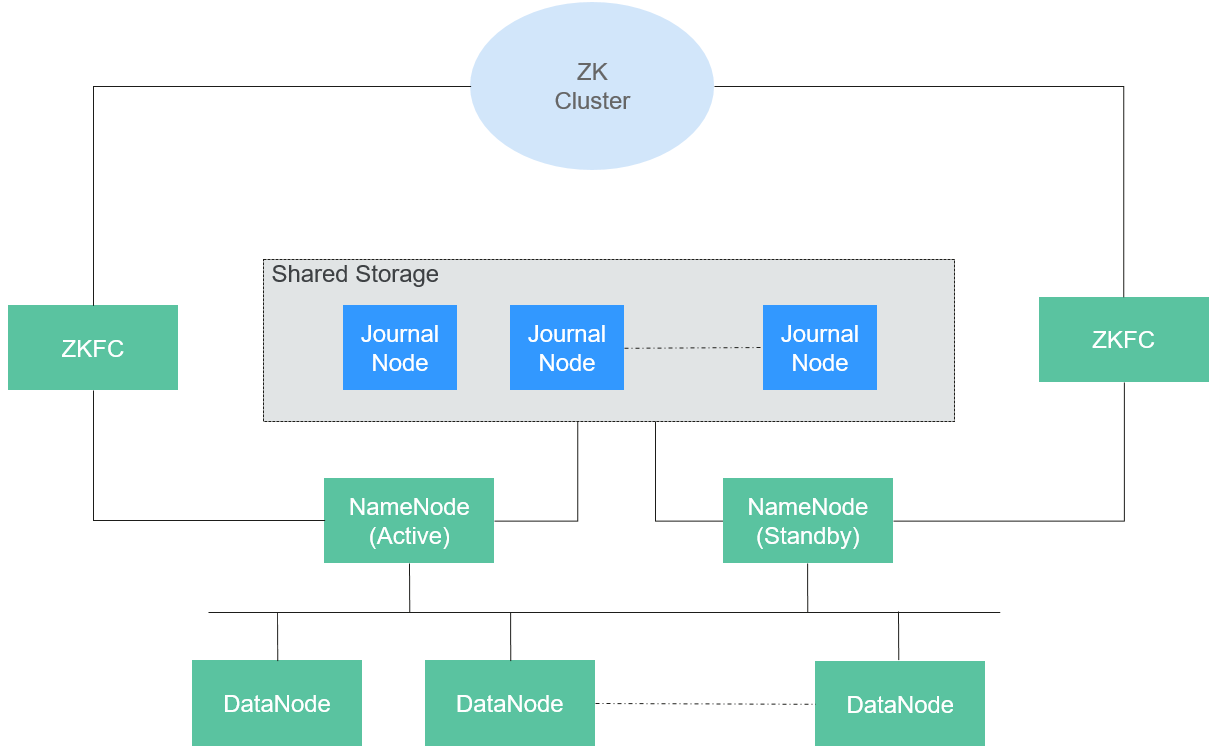
图1-1中各模块的功能说明如表1-1所示。

HA即为High Availability,用于解决NameNode单点故障问题,该特性通过主备的方式为主NameNode提供一个备用者,一旦主NameNode出现故障,可以迅速切换至备NameNode,从而不间断对外提供服务。
在一个典型HDFS HA场景中,通常由两个NameNode组成,一个处于Active状态,另一个处于Standby状态。
为了能实现Active和Standby两个NameNode的元数据信息同步,需提供一个共享存储系统。本版本提供基于QJM(Quorum Journal Manager)的HA解决方案,如图1-2所示。主备NameNode之间通过一组JournalNode同步元数据信息。
通常配置奇数个(2N+1个)JournalNode,且最少要运行3个JournalNode。这样,一条元数据更新消息只要有N+1个JournalNode写入成功就认为数据写入成功,此时最多容忍N个JournalNode写入失败。比如,3个JournalNode时,最多允许1个JournalNode写入失败,5个JournalNode时,最多允许2个JournalNode写入失败。
由于JournalNode是一个轻量级的守护进程,可以与Hadoop其它服务共用机器。建议将JournalNode部署在控制节点上,以避免数据节点在进行大数据量传输时引起JournalNode写入失败。

HDFS原理
MRS使用HDFS的副本机制来保证数据的可靠性,HDFS中每保存一个文件则自动生成1个备份文件,即共2个副本。HDFS副本数可通过“dfs.replication”参数查询。
- 当MRS集群中Core节点规格选择为非本地盘(hdd)时,若集群中只有一个Core节点,则HDFS默认副本数为1。若集群中Core节点数大于等于2,则HDFS默认副本数为2。
- 当MRS集群中Core节点规格选择为本地盘(hdd)时,若集群中只有一个Core节点,则HDFS默认副本数为1。若集群中有两个Core节点,则HDFS默认副本数为2。若集群中Core节点数大于等于3,则HDFS默认副本数为3。
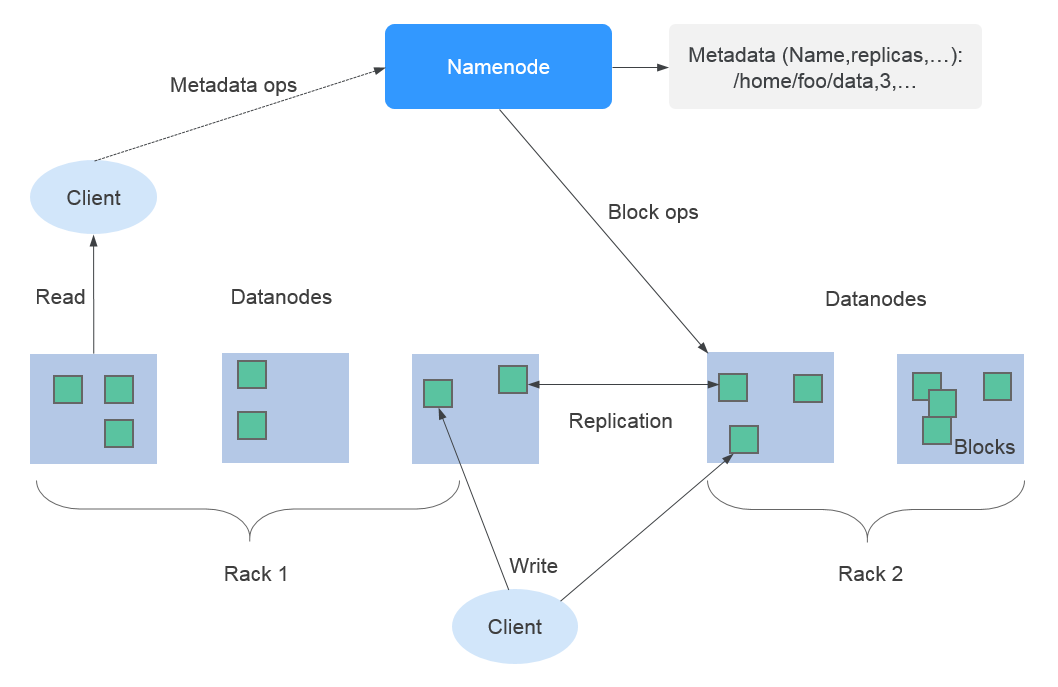
MRS服务的HDFS组件支持以下部分特性:
- HDFS组件支持纠删码,使得数据冗余减少到50%,且可靠性更高,并引入条带化的块存储结构,最大化的利用现有集群单节点多磁盘的能力,使得数据写入性能在引入编码过程后,仍和原来多副本冗余的性能接近。
- 支持HDFS组件上节点均衡调度和单节点内的磁盘均衡调度,有助于扩容节点或扩容磁盘后的HDFS存储性能提升。
更多关于Hadoop的架构和详细原理介绍,
请参见:http://hadoop.apache.org/。
HDFS文件基础操作
在MRS集群中,您可以通过管理控制台、客户端命令以及API接口等多种方式进行HDFS文件的操作。
MRS集群的创建您
可参考创建集群。
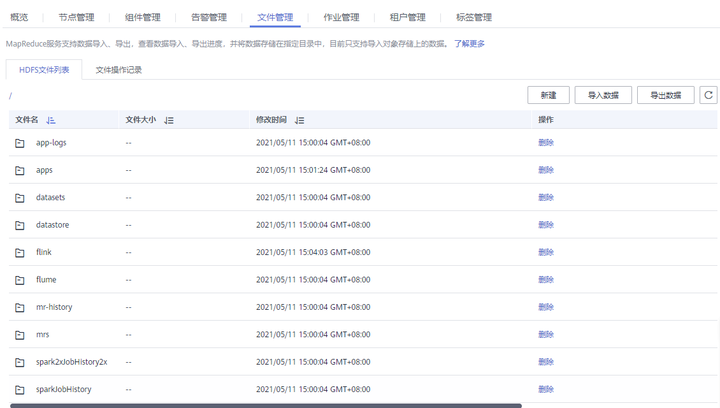
1、通过MRS管理控制台查看HDFS文件信息
在MRS管理控制台,点击集群名称进入到MRS集群详情页面,单击“文件管理”。
在文件管理页面,即可查看HDFS文件列表,并可以执行文件删除、文件夹增删以及与OBS服务数据的导入导入。
2、通过集群客户端查看HDFS文件信息
a. 登录MRS集群的FusionInsight Manager页面(如果没有弹性IP,需提前购买弹性IP),新建一个用户hdfstest,绑定用户组supergroup,绑定角色System_administrator(集群未开启Kerberos认证可跳过)。
b. 下载并安装集群全量客户端,例如客户端安装目录为“/opt/client”,可参考安装客户端。
c. 为客户端节点绑定一个弹性IP,然后使用root用户登录主Master节点,并进入客户端所在目录并认证用户。
cd /opt/client
source bigdata_env
kinit hbasetest(集群未开启Kerberos认证可跳过)
d. 使用hdfs命令进行HDFS文件相关操作。
例如:
- 创建文件夹:
hdfs dfs -mkdir /tmp/testdir
- 查看文件夹:
hdfs dfs -ls /tmp
Found 11 items drwx------ - hdfs hadoop 0 2021-05-20 11:20 /tmp/.testHDFS drwxrwxrwx - mapred hadoop 0 2021-05-10 10:33 /tmp/hadoop-yarn drwxrwxrwx - hive hadoop 0 2021-05-10 10:43 /tmp/hive drwxrwx--- - hive hive 0 2021-05-18 16:21 /tmp/hive-scratch drwxrwxrwt - yarn hadoop 0 2021-05-17 11:30 /tmp/logs drwx------ - hive hadoop 0 2021-05-20 11:20 /tmp/monitor drwxrwxrwx - spark2x hadoop 0 2021-05-10 10:45 /tmp/spark2x drwxrwxrwx - spark2x hadoop 0 2021-05-10 10:44 /tmp/sparkhive-scratch drwxr-xr-x - hetuserver hadoop 0 2021-05-17 11:32 /tmp/state-store-launcher drwxr-xr-x - hdfstest hadoop 0 2021-05-20 11:20 /tmp/testdir drwxrwxrwx - hive hadoop 0 2021-05-10 10:43 /tmp/tmp-hive-insert-flag
- 上传本地文件至HDFS:
hdfs dfs -put /tmp/test.txt /tmp/testdir (/tmp/test.txt提前准备)
执行hdfs dfs -ls /tmp/testdir命令检查文件是否存在。
Found 1 items -rw-r--r-- 3 hdfstest hadoop 49 2021-05-20 11:21 /tmp/testdir/test.txt
- 下载HDFS文件到本地:
hdfs dfs -get /tmp/testdir/test.txt /opt
3、通过API接口访问HDFS文件
HDFS支持使用Java语言进行程序开发,使用API接口访问HDFS文件系统,从而实现大数据业务应用。
具体的API接口内容请参考HDFS Java API。
关于HDFS应用开发及相关样例代码介绍,请参考《HDFS开发指南》。
更多华为云MapReduce(MRS)服务功能介绍及详情,请戳这里了解。