Linux: 安装
--yum -y install mariadb mariadb-server
OR
--yum -y install mysql mysql-server
启动
--service mysqld start 开启
--chkconfig mysqld on 设置开机自动启动
--systemctl start mariadb
--systemctl enable mariadb
查看
--ps aux | grep mysqld 查看进程
--netstat -an | grep 3306 查看端口
设置密码
--mysqladmin -uroot password 'xxxxx' 设置初始密码,初始密码为空因此-p选项没用
--mysqladmin -uroot -pxxxx password 'xxxxxxxxxx' 修改root用户密码
登录
-- mysql #本地登录,默认用户root,空密码,用户为root@127.0.0.1
-- mysql -uroot -p1234 #本地登录,指定用户名和密码,用户为root@127.0.0.1
-- mysql -uroot -p1234 -h 192.168.31.95 #远程登录,用户为root@192.168.31.95
数据库由字段和记录组成
SQL语句是结构化语句
规范:
1、不区分大小写,命令建议大写
2、以分号作为结束符号
3、注释-- 多行注释/* */
数据库的操作
SHOW DATABASES; --显示已有的数据库

CREATE DATABASE 数据库名称(小写) CHARACTER SET utf8; --创建数据库,指定数据库字符集


DROP DATABASE databasename; --删除数据库
ALTER DATABASE databasename CHARACTER SET xxx; --修改数据库的字符集

SHOW CREATE DATABASE databasename; --查看创建的数据库信息

DROP DATABASE databasename; --删除某一个数据库
USE databasename; --使用某一个数据库,切换到数据库目录下

创建表
数据表的操作
CREATE TABLE table_name(
字段名 字段数据类型[约束],
字段名 字段数据类型[约束],
字段名 字段数据类型[约束],
字段名 字段数据类型[约束],
)
主键:非空且唯一
/* 约束:
primary key (非空且唯一) :能够唯一区分出当前记录的字段称为主键!
主键特点:非空且唯一
注意:
1、每张表只能有一个主键
2、每一张表不一定只有一个非空且唯一的字段
3、如果表中只有一个非空且唯一字段,那它就是主键
如果表中不只有一个非空且唯一字段,那第一个非空切唯一的字段就是主键
unique 唯一
not null 非空
auto_increment :用于主键字段,主键字段必须是数字类型,自增 */

查看表信息
DESC table_name; --查看表结构

SHOW CREATE table_name; --查看创建表信息

SHOW TABLES; --查看数据库中的表

SHOW COLUMNS FROM table_name; --查看表列结构

修改表结构
单次单项操作
ALTER TABLE table_name ADD [column] 列名 类型 [约束条件] [FIRST | AFTER] 字段名; --向表中添加列
单次多项操作
ALTER TABLE table_name ADD [column] 列名 类型 [约束条件] [FIRST | AFTER] 字段名,
ADD [column] 列名 类型 [约束条件] [FIRST | AFTER] 字段名,
ADD [column] 列名 类型 [约束条件] [FIRST | AFTER] 字段名,
ADD [column] 列名 类型 [约束条件] [FIRST | AFTER] 字段名;

ALTER TABLE table_name MODIFY 列名 类型 [约束条件] [FIRST | AFTER] 字段名; --改变列的数据类型

ALTER TABLE table_name DROP [column] 列名; --删除某列

ALTER TABLE table_name CHANGE 列名 新列名 类型 [约束] [FIRST | AFTER] 字段名; --改变某列的名称

RENAME TABLE 表名 to 新表名; --修改表名称

ALTER TABLE table_name CHARACTER SET xxx; --修改表字符集
DROP TABLE table_name; --删除表
增加表记录
插入一条记录
INSERT [INTO] table_name (field1,filed2,......) VALUES (value1,value2,.......);
插入多条记录
INSERT [INTO] table_name (field1,field2,......) VALUES (value1,value2,......),
(value1,value2,......),
(value1,value2,......),
........;

修改表记录
UPDATE table_name SET field1=value1,field2=value2,...... [where]


删除表记录
DELETE FROM table_name [WHERE];
如果不跟WHERE,DELETE语句会删除整张表中的数据,只能删除表内容而不能删除表
TRUNCATE TABLE table_name 也可以删除表中的所有数据,首先摧毁表再创建新表,此种方式不能恢复



查询表记录
SELECT [DISTINCT] * | field1,field2,...... FROM table_name [WHERE 条件] [GROUP BY field HAVING 条件] [ORDER BY field] [LIMIT 条数]; --查询显示表中信息
SELECT * FROM table_name; --查询显示表中所有信息
SELECT field1 [AS] 别名,field2 [AS] 别名...... FROM table_name;

使用WHERE子句进行过滤查询
WHERE子句中可以使用:
比较运算符:
> < >= <= != <>
between ... and ... 之间
in (80,90,100) 80 90 100
like "a%" 表示任意多个字符,alpha , abc都可以
如果是"a_"表示一个字符,只有ab , ac符合
逻辑运算符:
多个条件可以使用逻辑运算符 and or not

ORDER BY 排序
SELECT * | field1,field2,... FROM table_name ORDER BY field [ASC | DESC];
-- ASC 升序, DESC降序,其中ASC为默认值,ORDER BY 子句应位于SELECT语句的结尾

GROUP BY 分组查询

GROUP BY 子句其后可以接多个列名,也可以跟having子句,对GROUP BY 的结果进行筛选

HAVING和WHERE两者都可以对查询结果进行进一步的过滤,差别有:
1、WHERE语句只能用在分组之前的筛选,HAVING可以用在分组之后的筛选
2、使用WHERE的语句的地方可以用HAVING进行替换
3、HAVING中可以使用聚合函数,WHERE中不能
聚合函数
COUNT(列名):统计行的个数

SUM(列名):统计满足条件的行的内容和
SELECT SUM(字段) AS 别名, --多条SUM查询
SUM(字段) AS 别名,
...... FROM table_name;

AVG(列名):求平均值
MAX,MIN : 求最大值,最小值
SELECT MAX((ifnull(字段1,0)+ifnull(字段2,0)+......) FROM table_name; --null和所有的数计算都是null,所以需要用ifnull将null转换为0
查询平均成绩大于85的学生姓名和平均成绩 SELECT sname,AVG(num) FROM student INNER JOIN score ON student.sid=score.student_id GROUP BY student_id HAVING AVG(num)>85
使用正则表达式查询
SELECT * FROM employee WHERE emp_name REGEXP '^yu';
创建外键
CREATE TABLE ClassCharger( id TINYINT PRIMARY KEY auto_increment, name VARCHAR (20), age INT , is_marriged boolean -- show create table ClassCharger: tinyint(1) );
CREATE TABLE Student(
id INT PRIMARY KEY auto_increment,
name VARCHAR (20),
charger_id TINYINT, --切记:作为外键一定要和关联主键的数据类型保持一致
-- [ADD CONSTRAINT charger_fk_stu]FOREIGN KEY (charger_id) REFERENCES ClassCharger(id);
)
DELETE FROM ClassCharger WHERE name="冰冰";
INSERT student (name,charger_id) VALUES ("yuan",1);
-- 删除居然成功,可是 alvin3显示还是有班主任id=1的冰冰的;
-----------增加外键和删除外键---------
ALTER TABLE student ADD CONSTRAINT abc
FOREIGN KEY(charger_id)
REFERENCES classcharger(id);
ALTER TABLE student DROP FOREIGN KEY abc;
内链接
查询生物成绩不及格的学生姓名和对应生物分数 SELECT sname,num FROM student INNER JOIN (SELECT * FROM score WHERE course_id=1) a ON student.sid=a.student_id WHERE num<60
select * from employee,department where employee.dept_id = department.dept_id; --select * from employee inner join department on employee.dept_id = department.dept_id;
外链接
--(1)左外连接:在内连接的基础上增加左边有右边没有的结果 select * from employee left join department on employee.dept_id = department.dept_id; +--------+----------+------+---------+---------+-----------+ | emp_id | emp_name | age | dept_id | dept_id | dept_name | +--------+----------+------+---------+---------+-----------+ | 1 | A | 19 | 200 | 200 | 人事部 | | 5 | E | 20 | 200 | 200 | 人事部 | | 2 | B | 26 | 201 | 201 | 技术部 | | 3 | C | 30 | 201 | 201 | 技术部 | | 4 | D | 24 | 202 | 202 | 销售部 | | 6 | F | 38 | 204 | NULL | NULL | +--------+----------+------+---------+---------+-----------+ --(2)右外连接:在内连接的基础上增加右边有左边没有的结果 select * from employee RIGHT JOIN department on employee.dept_id = department.dept_id; +--------+----------+------+---------+---------+-----------+ | emp_id | emp_name | age | dept_id | dept_id | dept_name | +--------+----------+------+---------+---------+-----------+ | 1 | A | 19 | 200 | 200 | 人事部 | | 2 | B | 26 | 201 | 201 | 技术部 | | 3 | C | 30 | 201 | 201 | 技术部 | | 4 | D | 24 | 202 | 202 | 销售部 | | 5 | E | 20 | 200 | 200 | 人事部 | | NULL | NULL | NULL | NULL | 203 | 财政部 | +--------+----------+------+---------+---------+-----------+ --(3)全外连接:在内连接的基础上增加左边有右边没有的和右边有左边没有的结果 -- mysql不支持全外连接 full JOIN -- mysql可以使用此种方式间接实现全外连接 select * from employee RIGHT JOIN department on employee.dept_id = department.dept_id UNION select * from employee LEFT JOIN department on employee.dept_id = department.dept_id; +--------+----------+------+---------+---------+-----------+ | emp_id | emp_name | age | dept_id | dept_id | dept_name | +--------+----------+------+---------+---------+-----------+ | 1 | A | 19 | 200 | 200 | 人事部 | | 2 | B | 26 | 201 | 201 | 技术部 | | 3 | C | 30 | 201 | 201 | 技术部 | | 4 | D | 24 | 202 | 202 | 销售部 | | 5 | E | 20 | 200 | 200 | 人事部 | | NULL | NULL | NULL | NULL | 203 | 财政部 | | 6 | F | 38 | 204 | NULL | NULL | +--------+----------+------+---------+---------+-----------+ -- 注意 union与union all的区别:union会去掉相同的纪录
联合主键
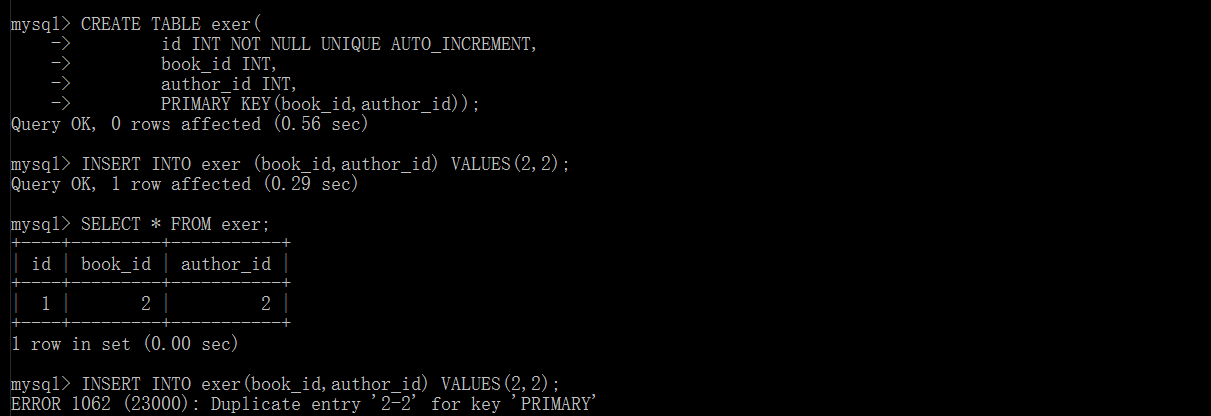
Pymysql:

import pymysql conn=pymysql.connect(host='127.0.0.1',port=3306,user='root',passwd='lyp6187028',db='employee') #创建连接 cursor=conn.cursor() #创建游标 command=cursor.execute("update emp set dept_id=199 where dept_name='HR'") #执行命令并返回受影响行数 print(command) #1 conn.commit() cursor.close() #关闭游标 conn.close() #关闭连接
import pymysql conn=pymysql.connect(host='127.0.0.1',port=3306,user='root',passwd='lyp6187028',db='employee') cursor=conn.cursor() command=cursor.executemany("INSERT INTO emp (dept_id,dept_name) VALUES(%s,%s)",[(204,"Product"),(205,"Admin")]) print(command) #2 conn.commit() cursor.close() conn.close()

获取查询语句
import pymysql conn=pymysql.connect(host='127.0.0.1',port=3306,user='root',passwd='lyp6187028',db='employee') cursor=conn.cursor() command=cursor.execute("SELECT * FROM emp") row=cursor.fetchone() #或许查询第一行
#row=cursor.fetchmany(3) #((199, 'HR'), (201, 'TECH'), (202, 'SALE')) 获取查询结果指定数目
#row=cursor.fetchall() #((199, 'HR'), (201, 'TECH'), (202, 'SALE'), (203, 'FINANCE'), (204, 'Product'), (205, 'Admin')) 获取全部的查询结果
print(row) # (199, 'HR') conn.commit() cursor.close() conn.close()
获取数据的默认类型为元组类型,可以将其设置为字典类型
import pymysql conn=pymysql.connect(host='127.0.0.1',port=3306,user='root',passwd='lyp6187028',db='employee') cursor=conn.cursor(cursor=pymysql.cursors.DictCursor) command=cursor.execute("SELECT * FROM emp") row=cursor.fetchall() print(row) conn.commit() cursor.close() conn.close() 执行结果 [{'dept_id': 199, 'dept_name': 'HR'}, {'dept_id': 201, 'dept_name': 'TECH'}, {'dept_id': 202, 'dept_name': 'SALE'},
{'dept_id': 203, 'dept_name': 'FINANCE'}, {'dept_id': 204, 'dept_name': 'Product'}, {'dept_id': 205, 'dept_name': 'Admin'}]
创建索引
--创建表时 --语法: CREATE TABLE 表名 ( 字段名1 数据类型 [完整性约束条件…], 字段名2 数据类型 [完整性约束条件…], [UNIQUE] INDEX | KEY [索引名] (字段名[(长度)] [ASC |DESC]) ); -------------------------------- --创建普通索引示例: CREATE TABLE emp1 ( id INT, name VARCHAR(30) , resume VARCHAR(50), INDEX index_emp_name (name) --KEY index_dept_name (dept_name) ); --创建唯一索引示例: CREATE TABLE emp2 ( id INT, name VARCHAR(30) , bank_num CHAR(18) UNIQUE , resume VARCHAR(50), UNIQUE INDEX index_emp_name (name) ); --创建全文索引示例: CREATE TABLE emp3 ( id INT, name VARCHAR(30) , resume VARCHAR(50), FULLTEXT INDEX index_resume (resume) ); --创建多列索引示例: CREATE TABLE emp4 ( id INT, name VARCHAR(30) , resume VARCHAR(50), INDEX index_name_resume (name,resume) ); ---------------------------------
添加和删除索引
---添加索引 ---CREATE在已存在的表上创建索引 CREATE [UNIQUE] INDEX 索引名 ON 表名 (字段名[(长度)] [ASC |DESC]) ; ---ALTER TABLE在已存在的表上创建索引 ALTER TABLE 表名 ADD [UNIQUE] INDEX 索引名 (字段名[(长度)] [ASC |DESC]) ; CREATE INDEX index_emp_name on emp1(name); ALTER TABLE emp2 ADD UNIQUE INDEX index_bank_num(band_num); -- 删除索引 语法:DROP INDEX 索引名 on 表名 DROP INDEX index_emp_name on emp1; DROP INDEX bank_num on emp2;