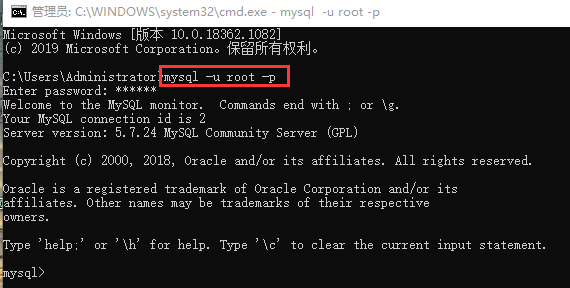
一、连接数据库
第一步肯定是连接数据库,与用Navicat操作数据库类似,连接数据库需要四个参数
- host(-h):默认是本机IP
- port(-P):默认端口号3306
- user(-u)
- password(-p)
语句:mysql -h (IP) -P (端口) -u root -p
注:①先不用输入密码,输入上条语句之后后续会让输密码
②由于是操作的本机数据库,IP和端口是默认的,可以不输入,可以省略写成mysql -u root -p,如果要操作的是其他的数据库,就需要输入对应的IP和端口
二、管理数据库
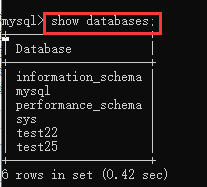
1、展示数据库:show databases;
2、新建数据库:create database 数据库名 default charset utf8mb4;
和Navicat创建数据库一个思想,主要从两个方面考虑,一个是数据库名,一个是字符集
3、修改数据库:alter database 数据库名 default charset utf8mb4;
和Navicat修改数据库一样,不能修改数据库名,只能对数据库的字符集进行修改,
4、删除数据库:drop database 数据库名;
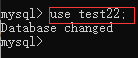
5、选择数据库:use 数据库名;
6、退出当前数据库:quit;
三、管理表
1、展示表:show tables;

2、新建表
create table table_name( id integer primary key, username varchar(20) not null, birthday date );
3、删除表:drop table 表名;
4、修改表
修改字段名:
alter table + 表名 + change + 列名 + 新列名 + 列类型+[约束];
修改字段属性:
alter table + 表名 + modify + 列名 + [列类型 +约束];
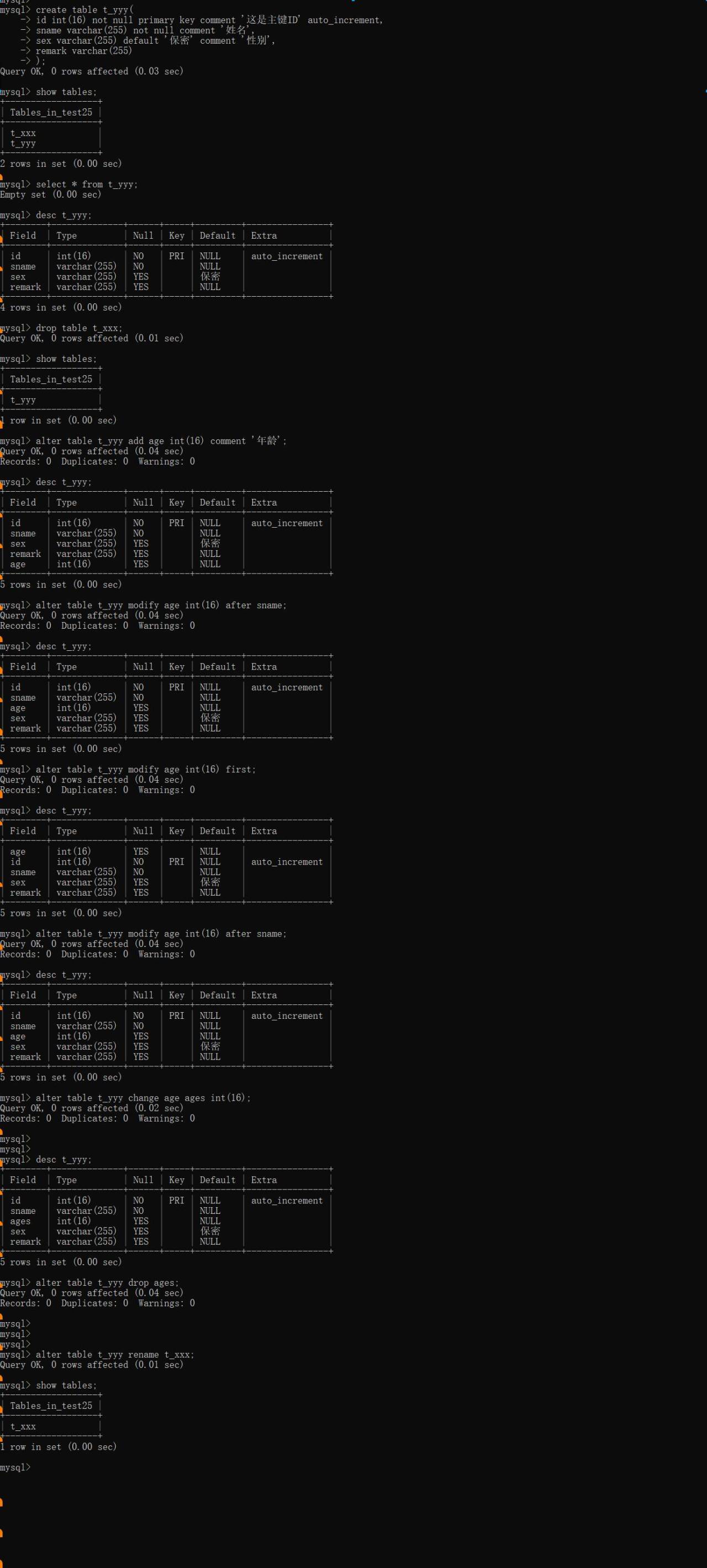
5、查看表结构:desc 表名;
四、数据操作
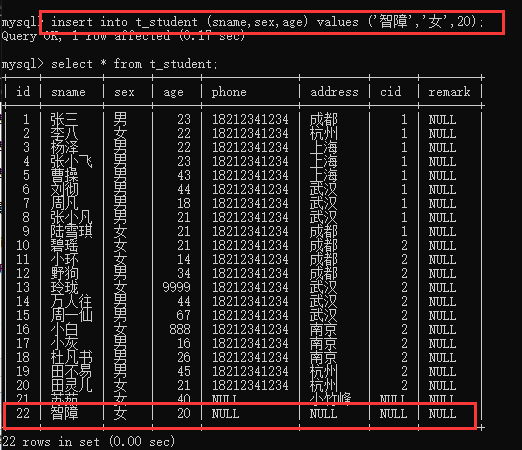
1、增:insert into 表名(字段名1,字段名2)values(值1,值2);
注:并不是所有字段都必须加进去,但是必填字段必须写
2、删:delete from 表名 where 条件;
3、改:update 表名 set 字段1=新值1,字段2=新值2 where 条件;

4、查
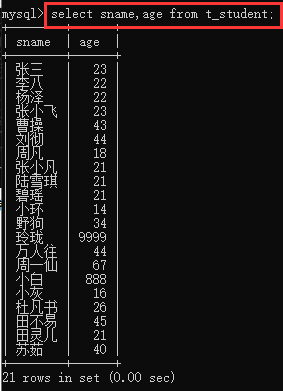
①一览表:select * from 表名;

②显示部分字段:select 字段1,字段2 from 表名;
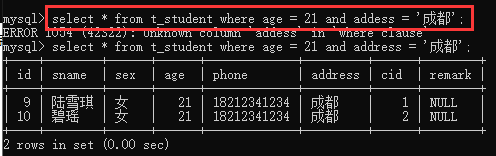
③根据限制条件查询所有:select * from 表名 where 字段1=值1 and 字段2=值2;(注意:涉及到字符串都必须要加引号,不区分单双引号)
④排序:(order by):select * from 表名 order by 字段名;
desc:降序排列
asc:升序排列,默认状态是升序的,默认状态时可以不写asc
注:如果SQL语句中有查询语句,order by 直接写在查询语句的后边,而且不能加and,(and是查询语句里边的嘛!)


⑤限制查询的条件:limit
注:计算机是从0开始数数
limit 3其实就是limit0,3:表示从第零条数据开始查询,一共显示3条数据,显示数据1-3
limit3,5:就表示从第3条数据开始查询,总共查询5条数据,显示数据4-8
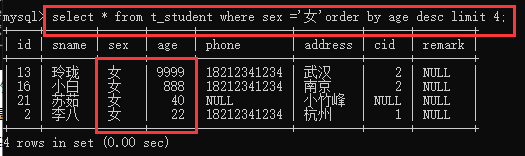
例:查询学生表中性别为女,年龄最大的前4位
例:查询学生表中年龄大于20且地区不是成都的学生,找出年龄最大的前三位
select * from t_student where age>20 and address !='成都'order by age desc limit 3;
也可以这样写: select * from t_student where age>20 and address not in ('成都') order by age desc limit 3;
⑥多表联查:
多表联查分为内连接和外连接(外连接又分为左外连接和右外连接),查询语法是相同的,不同的是取值
- 内连接:join/inner join on:内连接取两个表的交集部分
- 外连接
左外连接(左连接):left join on:左连接取左边表的并集部分
右外连接(右连接):right join on:右连接取右表的并集部分
查询所有:select * from 表1 join 表2 on 表1.字段1=表2.字段2;
查询选定字段及其值(表名.字段名): select 表1.字段a,表1.字段b,表2.字段c from 表1 join 表2 on 表1.字段1=表2.字段2;
注:表1.字段1=表2.字段2为表关系,可支持多张表联合查询
SQL语句后边还可以接上where条件以及排序等
由于现在是多张表了,表示字段名时就需要在前面添加表名了,表示方法:表名.字段名
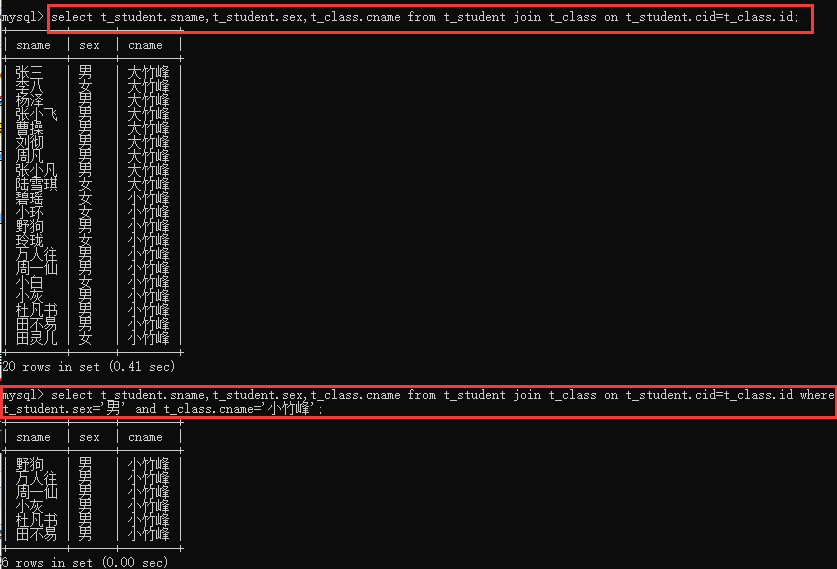
例:三张表进行查询:直接在后边加 join on

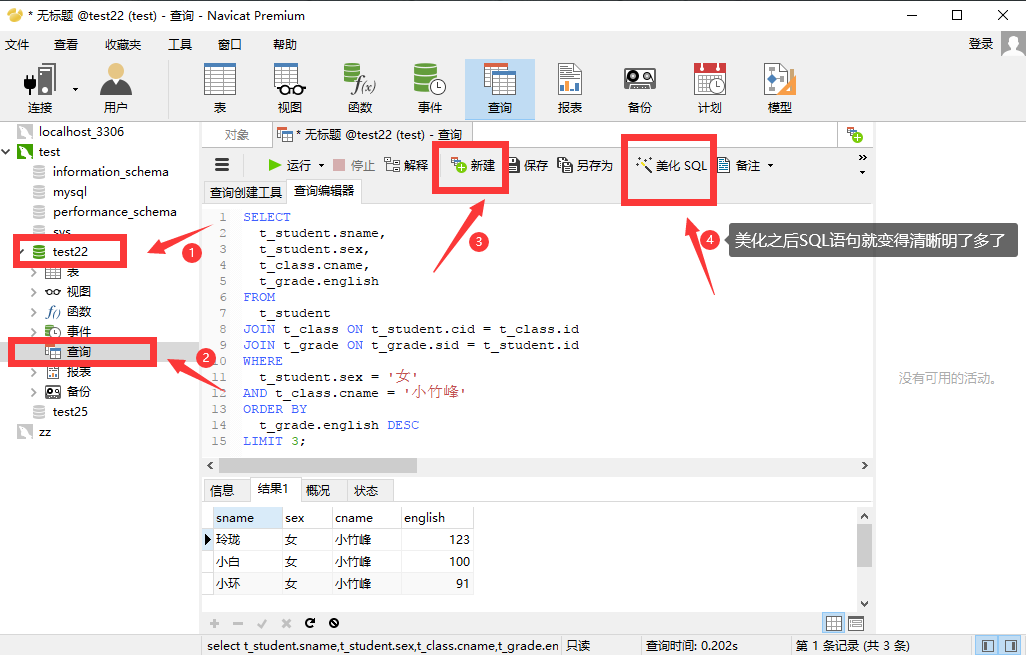
利用Navicat可以更加简明的看出SQL语句结构:
五、逻辑判断
1、=
2、!=
3、>=
4、<=
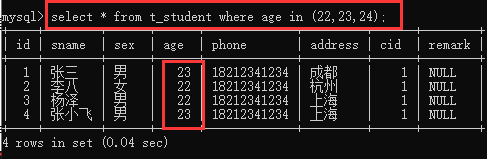
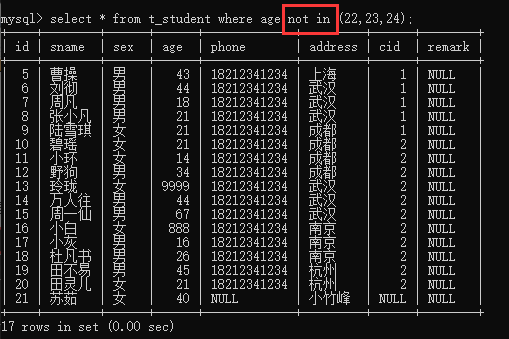
5、in:在…里面,需要写一个括号,括号里写值,有括号里的值就查询出来,没有的就算了,可取反
6、like:用于字符串的模糊查询
例如:以张开头:'张%'
以凡结尾:'%凡'
带小的都查出:'%小%'
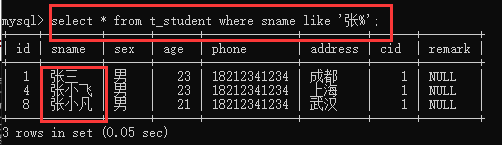

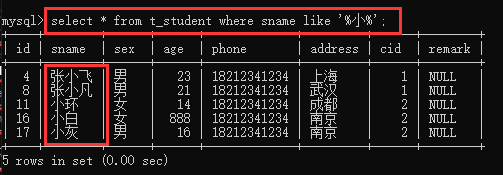
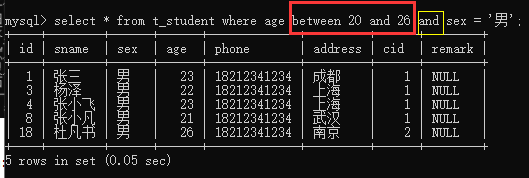
7、between:在两者之间,只能用来判断数字,数字才有区间的说法,而且between自带一个and,可取反

8、is:只能用于判断是否为空,可取反。(为空=null,注意和空字符串区别,他俩是不一样的)


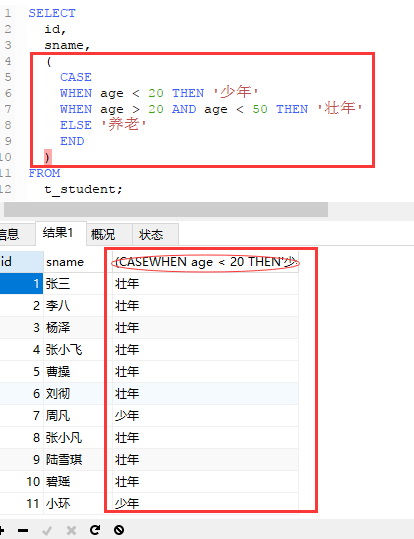
六、逻辑语句:case...when...then...end
case和end分别是语句的开始和语句的结束,when:当xx,then:那么xx。
case...when...then...end主要有两种用法,第一种简单的使用,如下例子,还有一种是带搜索功能的,同时可以实现分组的功能。
例:
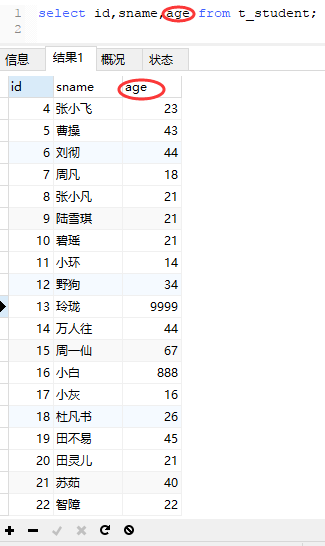
如果要想实现不直接显示数据,显示不同数据范围对应的不同内容的话,就可以用case...when...then...end结构,注意这个结构中没有任何一处地方有标点符号
七、SQL语句的分类
主要分为DDL、DQL、DML、DCL
①DDL:影响表的结构的语句,如create、drop、alter等语句
②DQL:查询相关的语句,如select、from、where等语句
③DML:操作表数据的语句:如insert、delete、update等语句
④DCL:开启数据库一些功能的语句,如权限、事务等语句
事务:在每次数据操作前,开启事务(begin),再对数据进行操作,最后检查操作的结果,有问题回滚(rollback),没问题确认(commit)
事务的出现都是成对出现的,即begin-rollback或者begin-commit
例如:现在t_class里边有两条数据

我要增加一条数据,在数据操作前,开启了事务


现在数据已经是显示三条了,但是第三条数据有误,此时可以事务回滚,返回到事务刚开启的样子

八、数据库的优化
当数据库中的数据达到了一定的量级,就需要对数据库进行优化了,这个过程通常是公司的架构师在做。
优化手段(层层递进):①添加索引 ②分表 ③分库 ④增加服务器的配置 ⑤分布式(放到不同的服务器中)
the end:在终端操作数据库时,带字符串的必须加引号,不区分单双引号
语句必须以英文分号结尾
所有的标点符号都是英文的
顺序:排序(order by)在查询(where条件)语句后边
分组要和聚合函数配合使用,但是聚合函数可以单独使用
脑图: