http://bilibili.com/video/BV1kE4119726?p=8


注解:
- python适合做深度学习。
- scipy是主要做数值分析(计算)的库
- scikitlearn是做机器学习的库
一个分类问题:
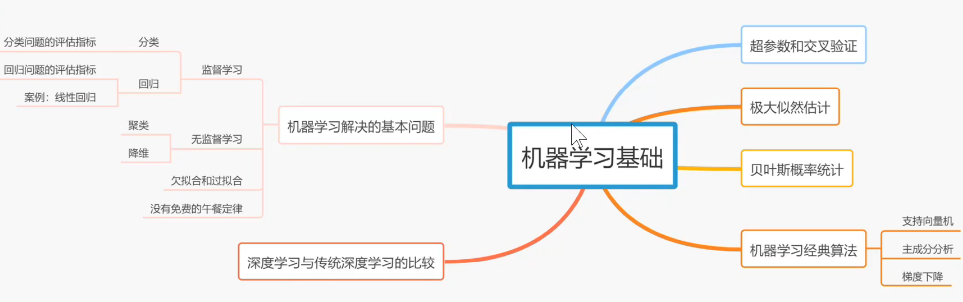
二分类和多分类问题的分类结果评估指标、回归模型(针对的是连续变量)的评估指标:
对线性模型的理解:
一维空间:线性模型是一个点
二维空间:线性模型是一条直线
三维空间:线性模型是一个平面

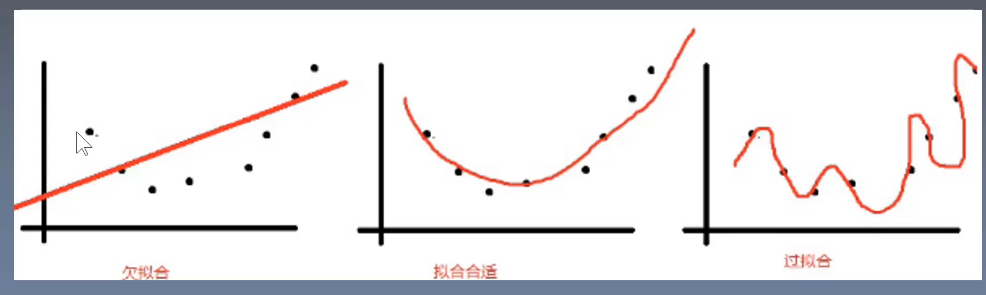
如果要求模型强行通过每一个待拟合的点,那只会过拟合,泛化能力会很差。
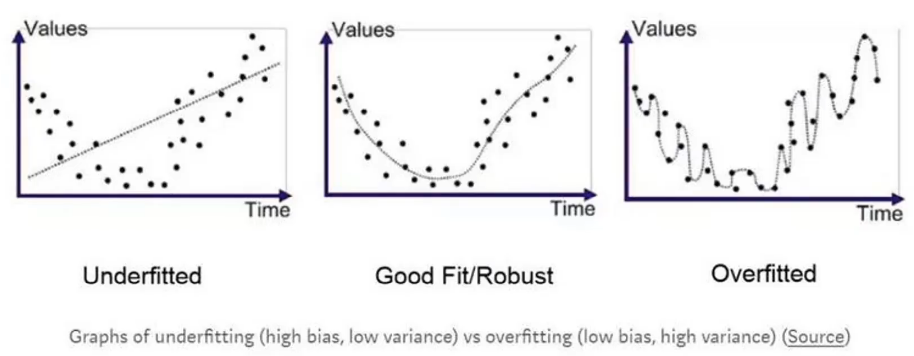
在深度学习中,欠拟合的情况是很少的,更多的是过拟合。
为了防止过拟合,需要采取一系列的正则化措施,比如对权重进行惩罚。
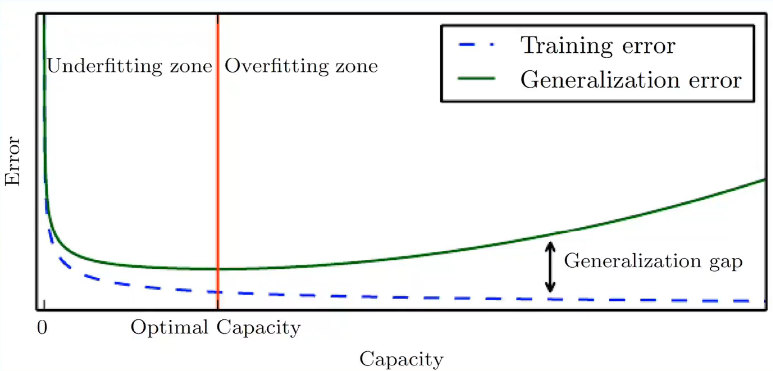
在深度神经网络训练的过程中,训练误差会越来越小,测试误差会越来越大,(这是一个偏差和方差的矛盾,见下图)所以要找到一个合适的时间点的参数,这个操作叫做"早停","early stopping"
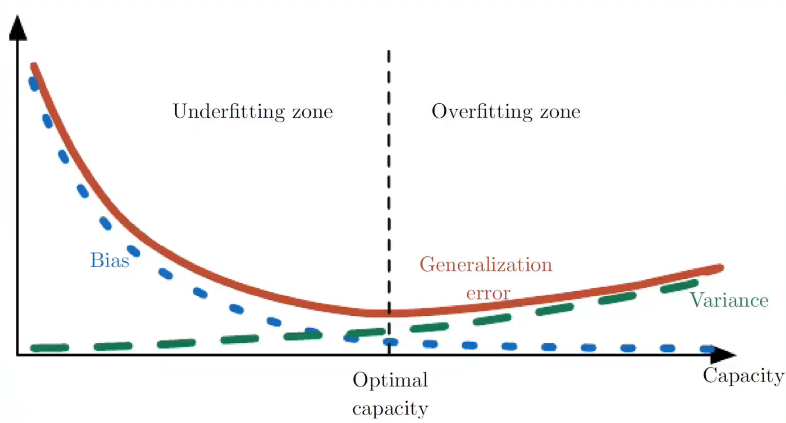
bias:偏差, 偏差大,表示欠拟合
variance:方差 方差大,表示过拟合
Optimal capacity,我们认识是泛化误差最小的时间点



机器学习中的极大似然估计:让所有的样本都被预测正确这个事件的概率最大化。每个事件发生的概率都是(0 ,1),很多个事件的连成积肯定是一个很小的数,所以取对象,让连乘变成连加求和,这样好操作一些。函数单调性不变。我们一般希望最小化一个东西,不喜欢最大化一个东西,所以,加个负号,就变成了最小化一个函数了。

K-Means算法对随机初始化的分类点的位置比较敏感,如果选择随机初始化的位置不是太好,可能会陷入局部最优。
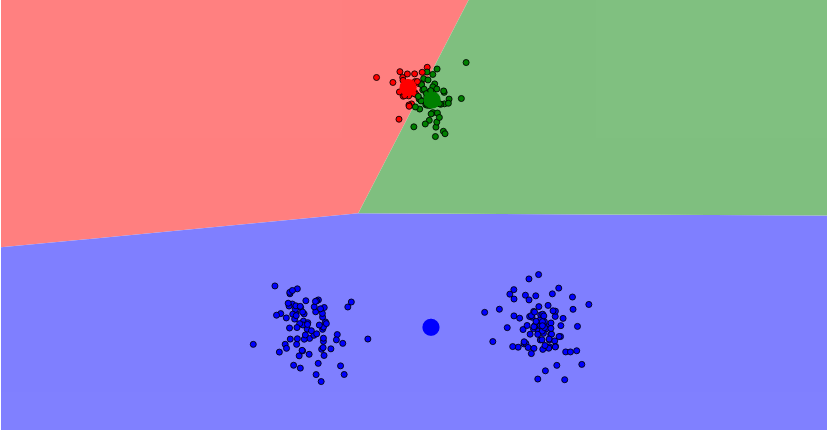
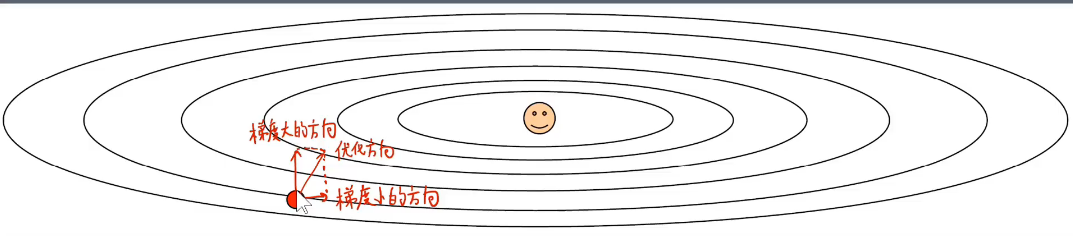
机器学习优化的过程也是一个梯度下降的过程,就是找到损失函数最小化的位置时候的参数权重。


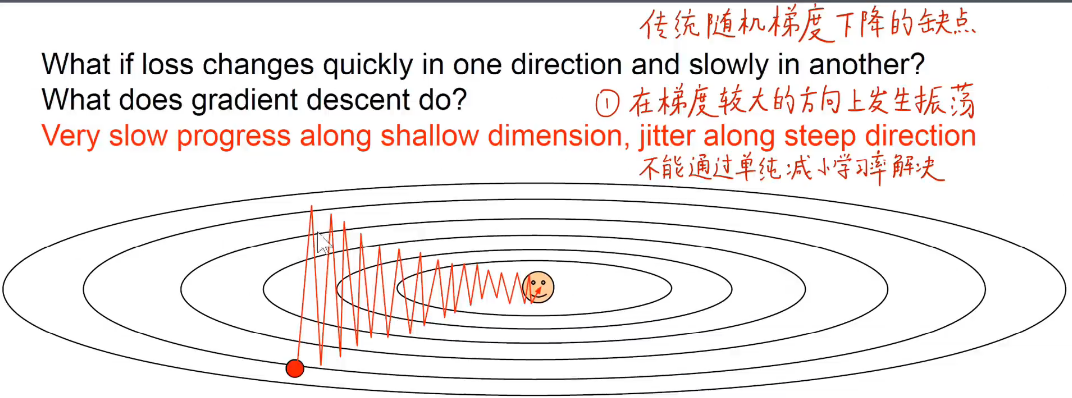


均方误差:
均(M)------分母是m个样本
方(S)------误差的平方
误差(E)-----预测值减去真实值

线性回归模型----优化斜率和截距,使得模型值-样本值的均方误差最小。
主成分分析本质上是求得协方差矩阵的特征值和特征向量,把高维的数据通过线性降维的方法映射到低维,找到两个最大的主成分方向来进行映射。
对于深度学习而言,维度是比较复杂的,优化的过程中存在局部最优值和鞍点,被优化函数是非凸的。