看了好几本大冰的书,感觉对自己的思维有不少的影响。想看看其他读者的评论。便想从当当下手抓取他们评论做个词云。
想着网页版说不定有麻烦的反爬,干脆从手机客户端下手好了。
果其不然,找到一个书评的api。发送请求就有详情的json返回,简直不要太方便...
要是对手机客户端做信息爬取,建议安装一个手机模拟器。
思路:
在安装好的手机模拟器设置好用来抓包的代理,我用的charles。记得安装证书,不然抓不了https的数据包。
然后安装当当客户端,打开进到书评页面。
KZRBSKE.png)
然后成功在charles找到了这个接口。发送get请求就会返回书评...

然后这个接口只有page参数需要注意下,代表请求的第几页。然后其他参数我照抄过来了。
当当边好像没有对这些参数做检验,用很久之前抓的的链接的参数还是能请求到数据...
之后就是请求链接在脚本里解析返回的json就好了,我只需要评论,十几行代码就行。
如果要抓其他书的书评应该修改参数product_id就好。
爬虫代码:
import requests import json import random import time url='http://api.dangdang.com/community/mobile/get_product_comment_list?access-token=&product_id=25288851&time_code=ae4074539cd0bf4ad526785a9439d756&tc=0cdfe66abc1ef55674c1ca8f815414b0&client_version=8.10.0&source_page=&action=get_product_comment_list&ct=android&union_id=537-100893×tamp=1540121525&permanent_id=20181021192526739954846678302543739&custSize=b&global_province_id=111&cv=8.10.0&sort_type=1&product_medium=0&page_size=15&filter_type=1&udid=c3b0e748134cbd9612e3e8b6a7e52952&main_product_id=&user_client=android&label_id=&page=' headers={ 'User-Agent':'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36' } def getComments(url, page): url = url+str(page) #url拼接,为了获取指定页的评论 html = requests.get(url=url,headers=headers) res = json.loads(html.text) result = res.get('review_list') #从字典中获取key为review_list的值,这与当当返回的数据结构有关 comments = [] for comment in result: comments.append(comment['content']) #评论正文 try: with open('comments.txt','a',encoding='utf-8') as f: f.write(comment['content']+' ') #写入文本中,免不了编码错误,加个try算了 except: print('第'+str(page)+'页出错') continue for i in range(1,100): #爬100页的评论 time.sleep(random.choice([1,2,3])) #每次循环强制停1~3秒,控制下频率... getComments(url,i)
词云生成,先使用jieba分词对爬到的评论进行分词。
记得分词后要用停用词表将一些没有什么意义的字符删去,比如标点符号,各种人称代词等等...
最后用pyecharts生成词云。
词云生成代码:
import jieba from pyecharts import options as opts from pyecharts.charts import Page, WordCloud from pyecharts.globals import SymbolType #添加自定义的分词 jieba.add_word('你坏') jieba.add_word('大冰') jieba.add_word('江湖') #文本的名称 text_path='comments.txt' #一些词要去除,停用词表 stopwords_path='stopwords.txt' #读取要分析的文本 words_file = open(text_path,'r',encoding='utf-8') text = words_file.read() def jiebaClearText(text): #分词,返回迭代器 seg_iter = jieba.cut(text,cut_all=False) listStr = list(seg_iter) res = {} #这个循环用来记录词频 for i in listStr: if i in res: res[i] += 1 else: res[i.strip()] = 1 try: #读取停用表 f_stop = open(stopwords_path,encoding='utf-8') f_stop_text = f_stop.read() finally: f_stop.close() #以换行符分开文本,因为每个停用词占一行。返回停用词列表 f_stop_seg_list = f_stop_text.split(' ') #这个循环用来删除评论出现在停用词表的词 for i in f_stop_seg_list: if i in res: del res[i] words = [] for k,v in res.items(): words.append((k,v)) #words的元素是(词,词出现的次数) #下面是以出现的次数将words排序 words.sort(key=lambda x:x[1],reverse=True) return words words = jiebaClearText(text) words_file.close() # 关闭一开始打开的文件 print(words) #词云生成,用到pyecharts,各参数的含义请到官方文档查看... worldcloud=( WordCloud().add("", words[:60], word_size_range=[10, 100],rotate_step=0, shape='triangle' ).set_global_opts(title_opts=opts.TitleOpts(title="《你坏》")) ) worldcloud.render('result.html') #保存成html文件
结果:
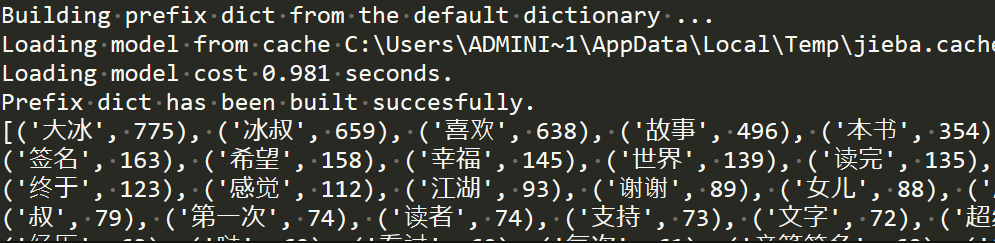
词云:
1V%7DC[JKFBM6.png)
最后,可以看到,其实书评里有很多带正向感情色彩的评论。
内容还是很正能量的哈哈,每天看一遍,赶走抑郁~
所以,容我也向您安利一下大冰的书哈哈。
The End~