数据表和视图
一、创建数据表:
1. 最简单的数据表:
sqlite> CREATE TABLE testtable (first_col integer);
这里需要说明的是,对于自定义数据表表名,如testtable,不能以sqlite_开头,因为以该前缀 定义的表名都用于sqlite内部。
2. 创建带有缺省值的数据表:
sqlite> CREATE TABLE testtable (first_col integer DEFAULT 0, second_col varchar DEFAULT 'hello');
3. 在指定数据库创建表:
sqlite> ATTACH DATABASE 'd:/mydb.db' AS mydb;
sqlite> CREATE TABLE mydb.testtable (first_col integer);
--创建两个表,一个临时表和普通表。
sqlite> CREATE TEMP TABLE temptable(first_col integer);
sqlite> CREATE TABLE testtable (first_col integer);
--将当前连接中的缓存数据导出到本地文件,同时退出当前连接。
sqlite> .output ./test.sql
sqlite> .dump
sqlite> .output stdout
备份数据库
.output [filename] 导出到文件中,如果该文件不存在,则自动创建
.dump 导出数据命令
.output stdout 返回输出到屏幕(进行其他操作)
sqlite> .exit
--重新建立sqlite的连接,并将刚刚导出的数据库作为主库重新导入。
--查看该数据库中的表信息,通过结果可以看出临时表并没有被持久化到数据库文件中。
sqlite> .tables
testtable
4. "IF NOT EXISTS"从句:
如果当前创建的数据表名已经存在,即与已经存在的表名、视图名和索引名冲突,那么本次创 建操作将失败并报错。
然而如果在创建表时加上"IF NOT EXISTS"从句,那么本次创建操作将 不会有任何影响,
即不会有错误抛出,除非当前的表名和某一索引名冲突。
sqlite> CREATE TABLE testtable (first_col integer);
Error: table testtable already exists
sqlite> CREATE TABLE IF NOT EXISTS testtable (first_col integer);
5. CREATE TABLE ... AS SELECT:
通过该方式创建的数据表将与SELECT查询返回的结果集具有相同的Schema信息,但是不包 含缺省值和主键等约束信息。然而新创建的表将会包含结果集返回的所有数据。
sqlite> CREATE TABLE testtable2 AS SELECT * FROM testtable;
sqlite> .schema testtable2
CREATE TABLE testtable2(first_col INT);
6. 主键约束: --直接在字段的定义上指定主键。
sqlite> CREATE TABLE testtable (first_col integer PRIMARY KEY ASC);
--在所有字段已经定义完毕后,再定义表的数约束,这里定义的是基于first_col和 second_col的联合主键。
sqlite> CREATE TABLE testtable2 (
...> first_col integer,
...> second_col integer,
...> PRIMARY KEY (first_col,second_col) ...> );
和其他关系型数据库一样,主键必须是唯一的。
7. 唯一性约束: --直接在字段的定义上指定唯一性约束。
sqlite> CREATE TABLE testtable (first_col integer UNIQUE);
--在所有字段已经定义完毕后,在定义表的唯一性约束,这里定义的是基于两个列的唯一性约 束。
sqlite> CREATE TABLE testtable2 (
...> first_col integer,
...> second_col integer,
...> UNIQUE (first_col,second_col)
...> );
8. 为空(NOT NULL)约束:
sqlite> CREATE TABLE testtable(first_col integer NOT NULL);
sqlite> INSERT INTO testtable VALUES(NULL);
Error: testtable.first_col may not be NULL
从输出结果可以看出,first_col已经被定义了非空约束,因此不能在插入NULL值了。
9. 检查性约束: sqlite> CREATE TABLE testtable (first_col integer CHECK (first_col < 5));
sqlite> INSERT INTO testtable VALUES(4);
sqlite> INSERT INTO testtable VALUES(20);
-- 20违反了字段first_col的检查性约束(first_col < 5)
Error: constraint failed --和之前的其它约束一样,检查性约束也是可以基于表中的多个列来定义的。
sqlite> CREATE TABLE testtable2 ( .
..> first_col integer,
...> second_col integer,
...> CHECK (first_col > 0 AND second_col < 0) ...> );
二、表的修改:
1. 修改表名:
sqlite> CREATE TABLE testtable (first_col integer);
sqlite> ALTER TABLE testtable RENAME TO testtable2;
sqlite> .tables
testtable2
通过.tables命令的输出可以看出,表testtable已经被修改为testtable2。
2. 新增字段: sqlite> CREATE TABLE testtable (first_col integer);
sqlite> ALTER TABLE testtable ADD COLUMN second_col integer;
sqlite> .schema testtable
CREATE TABLE "testtable" (first_col integer, second_col integer);
通过.schema命令的输出可以看出,表testtable的定义中已经包含了新增字段。 关于ALTER TABLE最后需要说明的是,在SQLite中该命令的执行时间是不会受到当前表行数 的影响,也就是说,修改有一千万行数据的表和修改只有一条数据的表所需的时间几乎是相等 的。
三、表的删除: 在SQLite中如果某个表被删除了,那么与之相关的索引和触发器也会被随之删除。
sqlite> CREATE TABLE testtable (first_col integer);
sqlite> DROP TABLE testtable;
sqlite> DROP TABLE testtable;
Error: no such table: testtable
sqlite> DROP TABLE IF EXISTS testtable;
从上面的示例中可以看出,如果删除的表不存在,SQLite将会报错并输出错误信息。如果希 望在执行时不抛出异常,我们可以添加IF EXISTS从句,该从句的语义和CREATE TABLE中 的完全相同。
四、创建视图:
1. 最简单的视图:
sqlite> CREATE VIEW testview AS SELECT * FROM testtable WHERE first_col > 100;
2. 创建临时视图:
sqlite> CREATE TEMP VIEW tempview AS SELECT * FROM testtable WHERE first_col > 100;
3. "IF NOT EXISTS"从句:
sqlite> CREATE VIEW testview AS SELECT * FROM testtable WHERE first_col > 100;
Error: table testview already exists
sqlite> CREATE VIEW IF NOT EXISTS testview AS SELECT * FROM testtable WHERE first_col > 100;
五、删除视图: 该操作的语法和删除表基本相同,因此这里只是给出示例:
sqlite> DROP VIEW testview;
sqlite> DROP VIEW testview;
Error: no such view: testview
sqlite> DROP VIEW IF EXISTS testview;
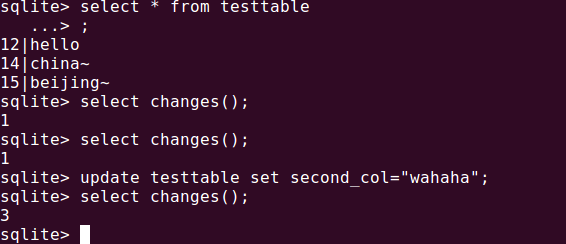
聚合函数:
ltrim(X[,Y])/rtrim(X[,Y])




--返回当前日期。
sqlite> SELECT date('now');
2012-01-15 --返回当前月的最后一天。
sqlite> SELECT date('now','start of month','1 month','-1 day');
2012-01-31 --返回从1970-01-01 00:00:00到当前时间所流经的秒数。
sqlite> SELECT strftime('%s','now');
1326641166
--返回当前年中10月份的第一个星期二是日期。
sqlite> SELECT date('now','start of year','+9 months','weekday 2');
2012-10-02
索引和数据分析/清理
一、创建索引:
sqlite> CREATE TABLE testtable (first_col integer,second_col integer);
--创建最简单的索引,该索引基于某个表的一个字段。
sqlite> CREATE INDEX testtable_idx ON testtable(first_col);
--创建联合索引,该索引基于某个表的多个字段,同时可以指定每个字段的排序规则(升序/降 序)。
sqlite> CREATE INDEX testtable_idx2 ON testtable(first_col ASC,second_col DESC);
--创建唯一性索引,该索引规则和数据表的唯一性约束的规则相同,即NULL和任何值都不 同,包括NULL本身。
sqlite> CREATE UNIQUE INDEX testtable_idx3 ON testtable(second_col DESC);
sqlite> .indices testtable
testtable_idx
testtable_idx2
testtable_idx3
从.indices命令的输出可以看出,三个索引均已成功创建。
二、删除索引: 索引的删除和视图的删除非常相似,含义也是如此,因此这里也只是给出示例:
sqlite> DROP INDEX testtable_idx;
--如果删除不存在的索引将会导致操作失败,如果在不确定的情况下又不希望错误被抛出,可 以使用"IF EXISTS"从句。
sqlite> DROP INDEX testtable_idx;
Error: no such index: testtable_idx
sqlite> DROP INDEX IF EXISTS testtable_idx;
三、重建索引: 重建索引用于删除已经存在的索引,同时基于其原有的规则重建该索引。这里需要说明的是, 如果在REINDEX语句后面没有给出数据库名,那么当前连接下所有Attached数据库中所有索 引都会被重建。如果指定了数据库名和表名,那么该表中的所有索引都会被重建,如果只是指 定索引名,那么当前数据库的指定索引被重建
。 --当前连接attached所有数据库中的索引都被重建。
sqlite> REINDEX;
--重建当前主数据库中testtable表的所有索引。
sqlite> REINDEX testtable;
--重建当前主数据库中名称为testtable_idx2的索引。
sqlite> REINDEX testtable_idx2;
一、Attach数据库: ATTACH DATABASE语句添加另外一个数据库文件到当前的连接中,如果文件名为 ":memory:",我们可以将其视为内存数据库,内存数据库无法持久化到磁盘文件上。如果操作 Attached数据库中的表,则需要在表名前加数据库名,如dbname.table_name。最后需要说 明的是,如果一个事务包含多个Attached数据库操作,那么该事务仍然是原子的。
见如下示例:
sqlite> CREATE TABLE testtable (first_col integer);
sqlite> INSERT INTO testtable VALUES(1);
sqlite> .backup 'D:/mydb.db'
--将当前连接中的主数据库备份到指定文件。
sqlite> .exit
--重新登录sqlite命令行工具:
sqlite> CREATE TABLE testtable (first_col integer);
sqlite> INSERT INTO testtable VALUES(2);
sqlite> INSERT INTO testtable VALUES(1);
sqlite> ATTACH DATABASE 'D:/mydb.db' AS mydb;
sqlite> .header on --查询结果将字段名作为标题输出。
sqlite> SELECT t1.first_col FROM testtable t1, mydb.testtable t2 WHERE t.first_col = t2.first_col;
first_col
----------
1




二、Detach数据库: 卸载将当前连接中的指定数据库,注意main和temp数据库无法被卸载。见如下示例:
--该示例承载上面示例的结果,即mydb数据库已经被Attach到当前的连接中。
sqlite> DETACH DATABASE mydb;
sqlite> SELECT t1.first_col FROM testtable t1, mydb.testtable t2 WHERE t.first_col = t2.first_col;
Error: no such table: mydb.testtable
三、事务: 在SQLite中,如果没有为当前的SQL命令(SELECT除外)显示的指定事务,那么SQLite会自动 为该操作添加一个隐式的事务,以保证该操作的原子性和一致性。当然,SQLite也支持显示 的事务,其语法与大多数关系型数据库相比基本相同。
见如下示例:
sqlite> BEGIN TRANSACTION;
sqlite> INSERT INTO testtable VALUES(1);
sqlite> INSERT INTO testtable VALUES(2);
sqlite> COMMIT TRANSACTION;
--显示事务被提交,数据表中的数据也发生了变化。
sqlite> SELECT COUNT(*) FROM testtable;
COUNT(*)
----------
2
sqlite> BEGIN TRANSACTION;
sqlite> INSERT INTO testtable VALUES(1);
sqlite> ROLLBACK TRANSACTION; --显示事务被回滚,数据表中的数据没有发生变化。
sqlite> SELECT COUNT(*) FROM testtable;
COUNT(*)
----------
2
1). 备份和还原数据库。 --在当前连接的main数据库中创建一个数据表,之后再通过.backup命令将main数据库备份到 ~/mydb.db文件中。
sqlite> CREATE TABLE mytable (first_col integer);
sqlite> .backup '~/mydb.db'
sqlite> .exit
--重新建立和SQLite的连接。
--从备份文件~/mydb.db中恢复数据到当前连接的main数据库中,再通过.tables命令可以看到 mytable表。
sqlite> .restore '~/mydb.db'
sqlite> .tables
mytable
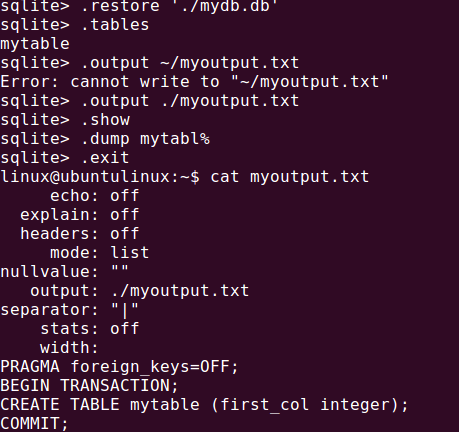
2). DUMP数据表的创建语句到指定文件。 --先将命令行当前的输出重定向到~/myoutput.txt,之后在将之前创建的mytable表的声明语句 输出到该文件。
sqlite> .output ~/myoutput.txt
sqlite> .dump mytabl%
sqlite> .exit
--在linux下打开目标文件。
>cat myoutput.txt
3). 显示当前连接的所有Attached数据库和main数据库。
sqlite> ATTACH DATABASE '~/mydb.db' AS mydb; sqlite> .databases seq name file --- --------------- ------------------------ 0 main 2 mydb D:mydb.db
显示匹配表名mytabl%的数据表的所有索引。
sqlite> CREATE INDEX myindex on mytable(first_col); sqlite> .indices mytabl% myindex
格式化显示SELECT的输出信息。
--插入测试数据 sqlite> INSERT INTO mytable VALUES(1); sqlite> INSERT INTO mytable VALUES(2); sqlite> INSERT INTO mytable VALUES(3); --请注意没有任何设置时SELECT结果集的输出格式。 sqlite> SELECT * FROM mytable; 1 2 3
--显示SELECT结果集的列名。 --以列的形式显示各个字段。 --将其后输出的第一列显示宽度设置为10. sqlite> .header on sqlite> .mode column sqlite> .width 10 sqlite> SELECT * FROM mytable; first_col ---------- 1 2 3