从UDP数据报长度说起
UDP属于网络模型中的传输层。下面我们由下至上一步一步来看:
理论上,IP协议允许的最大IP数据包(packet)为2^16=65535(IP包总长为16位):

但是!以太网(Ethernet)数据帧的长度必须在46-1500字节之间,这是由以太网的物理特性决定的。这个1500字节被称为链路层的MTU(最大传输单元)。但这并不是指链路层的长度被限制在1500字节,其实这个MTU指的是链路层的数据区,而不包括链路层的首部和尾部的18个字节。所以,1500字节就是网络层IP数据报的长度限制。
因为IP数据报的首部为20字节,所以IP数据报的数据区长度最大为1480字节。而这个1480字节就是用来放TCP传来的TCP报文段或UDP传来的UDP数据报的。
又因为UDP数据报的首部8字节,所以UDP数据报的数据区最大长度为1472字节。1472字节就是一个UDP数据报可以使用的字节数。
那么问题来了,应用层传输的数据,超过1472字节怎么办?
这也就是说IP数据报大于1500字节,大于MTU。这个时候发送方IP层就需要分片(fragmentation)——把数据报分成若干片,使每一片都小于MTU。而接收方IP层则需要进行数据报的重组。这样就实现了分片和重组过程对运输层(TCP/UDP)是透明的——TCP/UDP协议无需关注数据是否过长。
尽管IP分片过程看起来透明的,但对于TCP协议来说,但有一个缺陷:即使只丢失一片数据也要重新传整个数据报。why?因为IP层本身没有超时重传机制——由更高层(TCP)来负责超时和重传。当来自TCP报文段的某一片丢失后,TCP在超时后会重发整个TCP报文段,该报文段对应于一份IP数据报(而不是一个分片),没有办法只重传数据报中的一个数据分片。
而UDP——协议本身不管理数据的可靠性,也没有重传机制。由于UDP的特性,当某一片数据传送中丢失时。接收方将无法重组报文,故而导致整个UDP报文的丢弃。因此,在局域网环境下,一般建议将UDP数据包控制在1472byte以下为宜。进行Internet编程时则不同——因为Internet上的路由器可能会将MTU设为不同的值。如果我们假定MTU为1500来发送数据的,而途经的某个网络的MTU值小于1500字节,那么系统将会使用一系列的机制来调整MTU值,使数据报能够顺利到达目的地,这样就会做许多不必要的操作。鉴于Internet上的标准MTU值为576字节,建议在进行Internet的UDP编程时,将UDP的数据长度控件在576-8-20=548字节以内。
MSS(Maxitum Segment Size)
事实上,采用TCP协议进行数据传输是不会造成IP分片的,因为一旦TCP数据过大,超过了MSS,传输层就会对TCP包进行分段。由于MSS一般小于MTU,IP层对于TCP的分段数据就不用再分片了。
为了达到最佳的传输效能,TCP协议在建立连接的时候通常要协商双方的MSS值,这个值TCP协议在实现的时候往往用MTU值代替(需要减去IP数据包包头的大小20Bytes和TCP数据段的包头20Bytes)所以往往MSS为1460。通讯双方会根据双方提供的MSS值得最小值确定为这次连接的最大MSS值。
那么如何分段呢?其实TCP无所谓分段,因为每个TCP数据报在组成前其大小就已经被MSS限制了,所以TCP数据报的长度是不可能大于MSS的。
总结:报文在长度较大时会发生分段 or 分片。分段发生在传输层的TCP协议,分片发生在网络层的IP协议。
关于内核缓冲区
SOCK_DGRAM 类型的 socket 特点:
- 只有一个接收缓冲区,而不存在发送缓冲区。数据的发送是直接进行的,而不管对端是否能够正常接收,也不管对端接收缓冲区是否充满。
- 由于UDP是没有流量控制的,发送端可以很容易地就淹没接收者(更慢),导致接收方的UDP丢弃数据报。
- 另外需要注意的是,UDP的报文并不保证顺序,所以接收缓冲区里的报文需要手动排序(如有必要);
- 好消息是,UDP并不需要手动拆包——面向数据报的报文,并不会在缓冲区中自动合并。
对于TCP socket 而言:
- 内核中都有一个发送缓冲区和一个接收缓冲区——TCP的全双工工作模式以及TCP的滑动窗口就是依赖这两个独立的buufer以及buffer的填充状态。
- 对端发送过来数据,内核会存入接收缓冲区。缓冲区数据会一直保留直到应用层 read() 取走数据,在此过程中,TCP/IP协议栈继续执行,不断的将新的报文数据填充到接收缓冲区后面,直到填满为止。
- 接下来发生的动作是:通知对端TCP协议中的窗口关闭。这个便是滑动窗口的实现,用以保证TCP套接口接收缓冲区不会溢出,从而保证了TCP是可靠传输。因为对方不允许发出超过所通告窗口大小的数据。 这就是TCP的流量控制,如果对方无视窗口大小而发出了超过窗口大小的数据,则接收方TCP将丢弃它。
关于TCP的设计策略和问题
为何TCP采用字节流协议
其实,这种不同是由TCP和UDP的特性决定的。TCP是面向连接的,也就是说,在连接持续的过程中,socket中收到的数据都是由同一台主机发出的(劫持什么的不考虑),因此,只要保证数据是有序的到达就行了,至于每次读取多少数据自己看着办。 (问:那为啥不直接由协议指定封包,把这个事儿办了呢?)
而UDP是无连接的协议,也就是说,只要知道接收端的IP和端口,且网络是可达的,任何主机都可以向接收端发送数据。这时候,如果一次能读取超过一个报文的数据,则会乱套。比如,主机A向发送了报文P1,主机B发送了报文P2,如果能够读取超过一个报文的数据,那么就会将P1和P2的数据合并在了一起,这样的数据是没有意义的。
粘包,封包与拆包
由于TCP报文是面向流的,没有任何的边界记录,故而在 read() 时,将根据参数(buffer_length)一并读取所有报文,必须通过手动解包;
"粘包"可发生在发送端也可发生在接收端:
- 由Nagle算法造成的发送端的粘包:Nagle算法是一种改善网络传输效率的算法。简单的说,,当我们提交一段数据给TCP发送时,TCP并不立刻发送此段数据,而是等待一小段时间,看看在等待期间是否还有要发送的数据,若有则会一次把这两段数据发送出去。
- 接收端接收不及时造成的接收端粘包:TCP会把接收到的数据存在自己的缓冲区中,然后通知应用层取数据。当应用层由于某些原因不能及时的把TCP的数据取出来,就会造成TCP缓冲区中存放了多段数据。
封包就是给一段数据加上包头,这样一来数据包就分为包头和包体两部分内容了(过滤非法包时封包会加入"包尾"内容)。包头其实上是个大小固定的结构体,其中有个结构体成员变量表示包体的长度,这是个很重要的变量。其他的结构体成员可根据需要自己定义。根据包头长度固定以及包头中含有包体长度的变量就能正确的拆分出一个完整的数据包。
关于TCP的流量控制和阻塞控制
由于接收方缓存的限制,发送窗口不能大于接收方接收窗口。在报文段首部有一个字段就叫做窗口(rwnd),这便是用于告诉对方自己的接收窗口,可见窗口的大小是可以变化的。
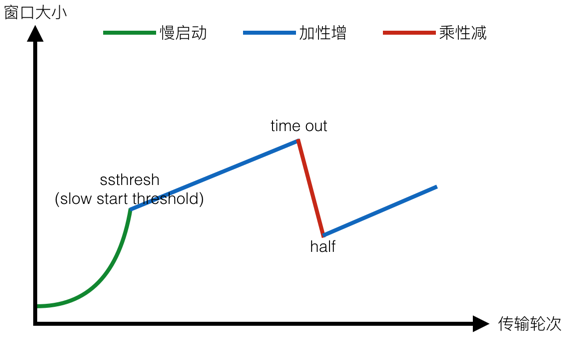
总结起来如上图,TCP的流量和阻塞控制采用“慢启动”、“加性增”、“乘性减”的策略。
- 慢启动:初始的窗口值很小,但是按指数规律渐渐增长,直到达到慢开始门限(ssthresh)。
- 加性增:窗口值达到慢开始门限后,每发送一个报文段,窗口值增加一个单位量。
- 乘性减:无论什么阶段,只要出现超时,则把窗口值减小一半。
思考
- 为什么TCP包不自动实现封包呢?或者说,软件世界里,例如 C++ 默认将流作为了字符串的外在表现形式,这似乎是存在着某种优势的考虑。然而Python等语言又将字符串通过封装长度属性,指定了字符串长度(包括ZMQ中对字符串的处理,也是通过指定长度的方式作为标准处理)。那后者的考虑因素又是什么?
- “字节流” 与 “数据报” 传输效率的比较?