使用Tensorflow和VGG16预训模型进行预测
fast.ai的入门教程中使用了kaggle: dogs vs cats作为例子来让大家入门Computer Vision。不过并未应用到最近很火的Tensorflow。Keras虽然可以调用Tensorflow作为backend,不过既然可以少走一层直接走Tensorflow,那秉着学习的想法,就直接用Tensorflow来一下把。
听说工程上普遍的做法并不是从头开始训练模型,而是直接用已经训练完的模型稍加改动(这个过程叫finetune)来达到目的。那么这里就需要用Tensorflow还原出VGG16的模型。这里借鉴了frossard的python代码和他转化的权重。架构具体如下:(cs231n有更详细的介绍)
INPUT: [224x224x3] memory: 224*224*3=150K weights: 0
CONV3-64: [224x224x64] memory: 224*224*64=3.2M weights: (3*3*3)*64 = 1,728
CONV3-64: [224x224x64] memory: 224*224*64=3.2M weights: (3*3*64)*64 = 36,864
POOL2: [112x112x64] memory: 112*112*64=800K weights: 0
CONV3-128: [112x112x128] memory: 112*112*128=1.6M weights: (3*3*64)*128 = 73,728
CONV3-128: [112x112x128] memory: 112*112*128=1.6M weights: (3*3*128)*128 = 147,456
POOL2: [56x56x128] memory: 56*56*128=400K weights: 0
CONV3-256: [56x56x256] memory: 56*56*256=800K weights: (3*3*128)*256 = 294,912
CONV3-256: [56x56x256] memory: 56*56*256=800K weights: (3*3*256)*256 = 589,824
CONV3-256: [56x56x256] memory: 56*56*256=800K weights: (3*3*256)*256 = 589,824
POOL2: [28x28x256] memory: 28*28*256=200K weights: 0
CONV3-512: [28x28x512] memory: 28*28*512=400K weights: (3*3*256)*512 = 1,179,648
CONV3-512: [28x28x512] memory: 28*28*512=400K weights: (3*3*512)*512 = 2,359,296
CONV3-512: [28x28x512] memory: 28*28*512=400K weights: (3*3*512)*512 = 2,359,296
POOL2: [14x14x512] memory: 14*14*512=100K weights: 0
CONV3-512: [14x14x512] memory: 14*14*512=100K weights: (3*3*512)*512 = 2,359,296
CONV3-512: [14x14x512] memory: 14*14*512=100K weights: (3*3*512)*512 = 2,359,296
CONV3-512: [14x14x512] memory: 14*14*512=100K weights: (3*3*512)*512 = 2,359,296
POOL2: [7x7x512] memory: 7*7*512=25K weights: 0
FC: [1x1x4096] memory: 4096 weights: 7*7*512*4096 = 102,760,448
FC: [1x1x4096] memory: 4096 weights: 4096*4096 = 16,777,216
FC: [1x1x1000] memory: 1000 weights: 4096*1000 = 4,096,000
具体实现移步VGG16。这里要注意的一点就是最后的输出是不需要经过Relu的。
预测猫和狗不能照搬这个架构,因为VGG16是用来预测ImageNet上1000个不同种类的。用来预测猫和狗两种类别,需要在这个架构的基础上再加一层FC把1000转化成2个。(也可以把最后一层替换掉,直接输出成2个)。我还在VGG16之后多加了一层BN,原来VGG16的时候并不存在BN。我也并没有在每个CONV后面加,因为不想算...
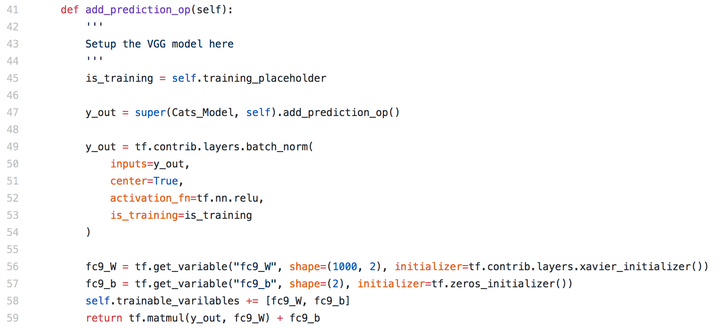
FC的输出在训练的时候使用Cross Entropy损失函数,预测的时候使用Softmax。这样就可以识别出给定图片是猫还是狗了。具体代码移步cats_model.py
我们来看一下效果如何。完整的:Jupyter Notebook
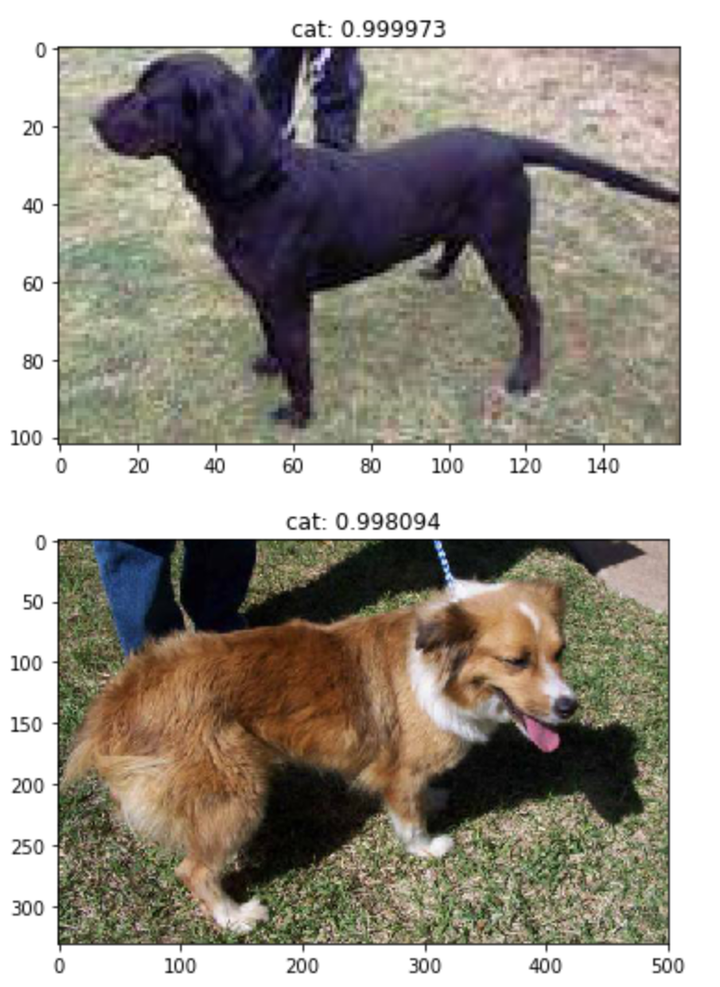
未经过Finetune直接运行VGG16改模型(加上了最后一层FC)的结果(预测非常不准,因为最后一层的权重都是随机的)。这么做的目的是看一下模型是否能运行,顺便看看能蒙对几个。
经过一次迭代,准确率就达到95%了(重复过几次,这次并不是最高的)。
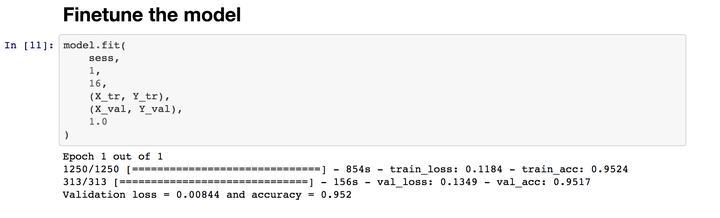
再看一下同样的图片预测结果,似乎准确了很多。

Final Thoughts
图像识别非常有趣,是一个非常有挑战的领域。