感知机
2018/12/17 代码结构更新,详见https://github.com/bBobxx/statistical-learning
前言
最近学习了c++,俗话说‘光说不练假把式’,所以决定用c++将《统计学习方法》里面的经典模型全部实现一下,代码在这里,请大家多多指教。
感知机虽然简单,但是他可以为学习其他模型提供基础,现在先简单回顾一下基础知识。
感知机模型
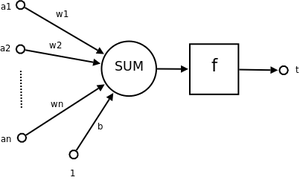
首先,感知机是用来分类的模型,上图就是简单的感知机模型,其中\(f\) 我们一般取符号函数
所以感知机的数学形式就是
其中w和x都是n维的向量。当n为2时,\(sign\)里面的公式有没有特别熟悉?就是直线的公式,n>2就是超平面,用一下课本里面的图就是如下图

这就是分类的根据,必须要注意,感知机只能分离线性可分数据,非线性的不行。
感知机学习策略
提到学习就不得不提到梯度下降算法。感知机的学习策略就是随机梯度下降算法。
具体的在书中讲的很详细,我这里就不赘述了,直接看学习算法吧:
(1) 选取初值w,b。
(2) 选取一组训练数据(x, y)。
(3) 如果\(y(wx+b)\leq0\),则
(4)转至(2)直到没有误分类点。
c++实现感知机
代码结构
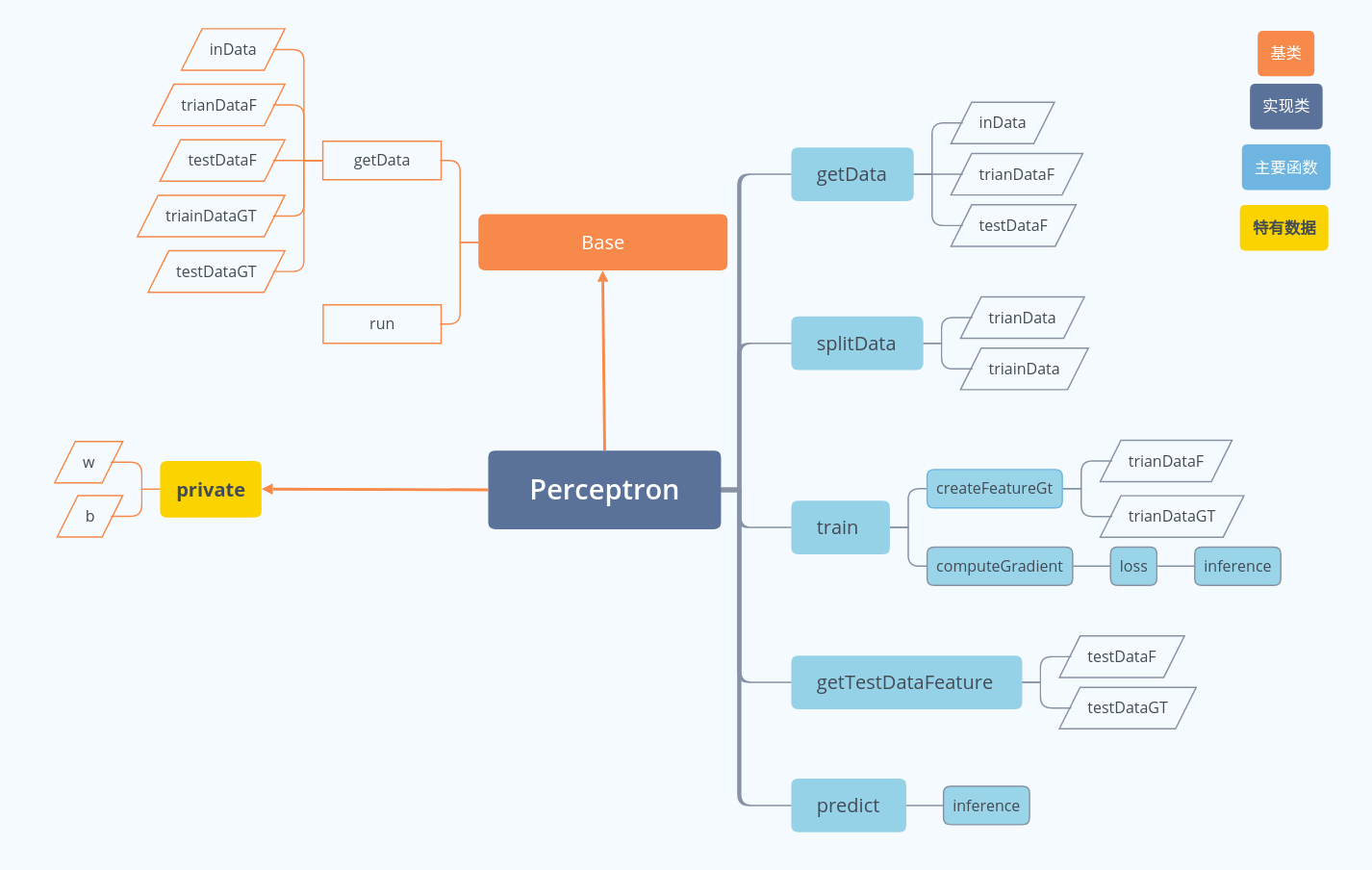
实现
首先我有一个基类Base,为了以后的算法继承用的,它包含一个run()的纯虚函数,这样以后就可以在main里面实现多态。
我的数据都存储在私有成员里:
std::vector<std::vector<double>> inData;//从文件都的数据
std::vector<std::vector<double>> trainData;//分割后的训练数据,里面包含真值
std::vector<std::vector<double>> testData;
unsigned long indim = 0;
std::vector<double> w;
double b;
std::vector<std::vector<double>> trainDataF;//真正的训练数据,特征
std::vector<std::vector<double>> testDataF;
std::vector<double> trainDataGT;//真值
std::vector<double> testDataGT;
在main函数里只需要调用每个模型的run()方法,声明的是基类指针:
int main() {
Base* obj = new Perceptron();
obj->run();
delete obj;
return 0;
}
第一步,读取数据并分割。这里用的vector存储。
getData("../data/perceptrondata.txt");
splitData(0.6);//below is split data , and store it in trainData, testData
第二步初始化
std::vector<double> init = {1.0,1.0,1.0};
initialize(init);
第三步进行训练。
在训练时,函数调用顺序如下:
-
调用computeGradient,进行梯度的计算。对于满足\(y(wx+b)>0\)的数据我们把梯度设为0。
std::pair<std::vector<double>, double> Perceptron::computeGradient(const std::vector<double>& inputData, const double& groundTruth) { double lossVal = loss(inputData, groundTruth); std::vector<double> w; double b; if (lossVal > 0.0) { for(auto indata:inputData) { w.push_back(indata*groundTruth); } b = groundTruth; } else{ for(auto indata:inputData) { w.push_back(0.0); } b = 0.0; } return std::pair<std::vector<double>, double>(w, b);//here, for understandable, we use pair to represent w and b. //you also could return a vector which contains w and b. }在调用computeGradient时又调用了loss,即计算\(-y(wx+b)\),loss里调用了inference,用来计算\(wx+b\),看起来有点多余对吧,inference函数存在的目的是为了后面预测时候用的。
double Perceptron::loss(const std::vector<double>& inputData, const double& groundTruth){ double loss = -1.0 * groundTruth * inference(inputData); std::cout<<"loss is "<< loss <<std::endl; return loss; }
double Perceptron::inference(const std::vector
//just compute wx+b , for compute loss and predict.
if (inputData.size()!=indim){
std::cout<<"input dimension is incorrect. "<<std::endl;
throw inputData.size();
}
double sum_tem = 0.0;
sum_tem = inputData * w;
sum_tem += b;
return sum_tem;
}
- 根据计算的梯度更新w, b
```c++
void Perceptron::train(const int & step, const float & lr) {
int count = 0;
createFeatureGt();
for(int i=0; i<step; ++i){
if (count==trainDataF.size()-1)
count = 0;
count++;
std::vector<double> inputData = trainDataF[count];
double groundTruth = trainDataGT[count];
auto grad = computeGradient(inputData, groundTruth);
auto grad_w = grad.first;
double grad_b = grad.second;
for (int j=0; j<indim;++j){//这里更新参数
w[j] += lr * (grad_w[j]);
}
b += lr * (grad_b);
}
}
- 预测用的数据也是之前就分割好的,注意这里的参数始终存在
std::vector<double> paraData;
进行预测的代码
int Perceptron::predict(const std::vector<double>& inputData, const double& GT) {
double out = inference(inputData);
std::cout<<"The right class is "<<GT<<std::endl;
if(out>=0.0){
std::cout<<"The predict class is 1"<<std::endl;
return 1;
}
else{
std::cout<<"The right class is -1"<<std::endl;
return -1;
}