一、基本信息
标题:基于Spark的高考推荐系统设计与实现
时间:2017
来源:山东师范大学
关键词:大数据; 推荐系统; 高考志愿; Spark 计算框架;
二、研究内容
1.论文主要内容
(1)结合高考的实际场景,对高考志愿推荐系统进行多方位的需求分析以及详细设计,确保考生用户的良好访问体验。
(2)设计专门的日志收集模块收集高考领域的相关数据集,存储到 HDFS 中,利用Spark 计算框架的相关技术对其进行清洗、处理后,提供给推荐引擎计算使用。
(3)充分研究了不同类型推荐算法的优点、缺点和适用场景,结合高考志愿填报具体场景与实际问题确定本系统开发的推荐算法。
(4)分析设计本系统的开发环境,确定 Spark 作为系统推荐模块的开发框架,完成相关平台环境的搭建调试,具体实现在 Spark 平台上的高考志愿推荐系统。
2.论文结构
第一章:首先,概述了本文的研究背景和意义,其次,对相关技术和系统的发展状况做深入的研究,最后,确定以基于 Spark 的推荐系统的形式开发本文的高考志愿系统。
第二章:分析研究了系统实现的关键技术,包括推荐系统与 Spark 计算框架的概念及组成。其中重点分析了推荐系统中最具代表性的几种推荐算法,以及 Spark 计算框架的并行化运算方式和相关组件。
第三章:结合高考考生以及志愿选择的各方面因素,对本文系统做多方位的需求分析,并最终确定了系统的主要功能模块,以及各功能模块所需完成的主要功能。
第四章:根据系统的需求分析内容,具体设计系统各模块的实现方式。重点设计推荐功能模块在 Spark 计算框架上的并行化实现方式以及结合 Spark 计算框架的日志信息收集方式,为下一章节的具体实现做铺垫。
第五章:完成开发前的 Spark 平台环境搭建,给出各模块的具体实现方式以及关键代码,并对系统做整体的性能、用户满意度和推荐准确度测试,保证其正确运行的同时给用户良好的使用体验。
3.系统需求分析
论文志愿推荐系统主要是针对考生志愿填报环节开发,随着考生或家长重视教育的意识不断提高,该系统推荐结果需保持高准确度,因此推荐算法的选择与实现至关重要。 同时为了提高系统的实用性,系统还应包含高校名称和录取批次等信息供考生参考。在系统正式应用后,用户量可能会不断的增长,相应而产生的用户行为日志也会不断增加,在全国的志愿填报时间段内该系统的访问量可能会大幅度增加,针对以上实际可能会发生的情况,在系统的正式开发前,首先要对系统做详细的分析来确定系统开发所要考虑的各个实现细节和目标,系统需求分析主要从需求分析的四个维度(用户需求分析、功能需求分析、业务需求分析和非功能性需求分析)来对系统整体开发做详细的分析。
4.用例图
(1)登录注册功能用例图
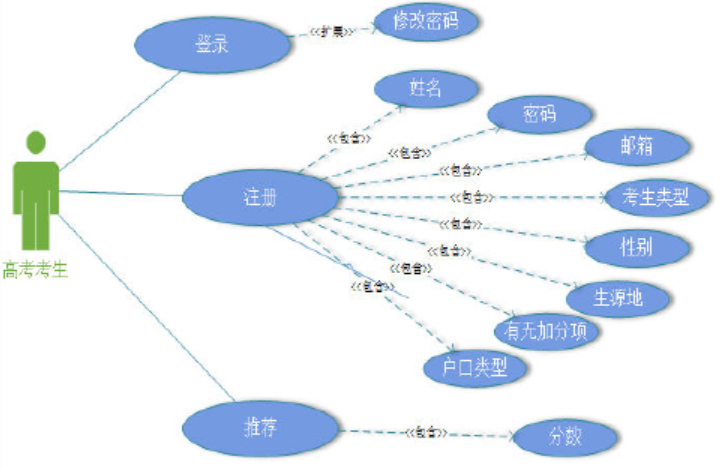
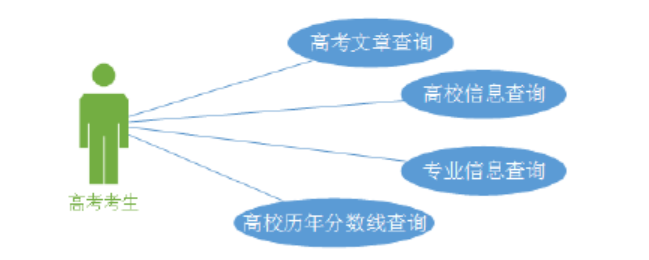
(2)高考信息浏览功能用例图
5.系统总体设计
系统分为三个模块:Web 前端界面、推荐引擎模块与日志信息收集模块,首先用户通过访问 Web 前端界面产生相应的日志信息,日志信息收集模块收集用户行为数据,并将其中一部分数据固定到 HDFS 文件系统中,另一部分实时信息提供给构建于 Spark 计算框架上的推荐系统进行实时计算,对于其他的离线数据集则通过Spark 组件 Spark SQL 直接读取到 HDFS 文件系统中进行推荐系统的离线计算,最终推荐引擎通过计算分析将志愿推荐列表返还给 Web 前端界面供用户查看。 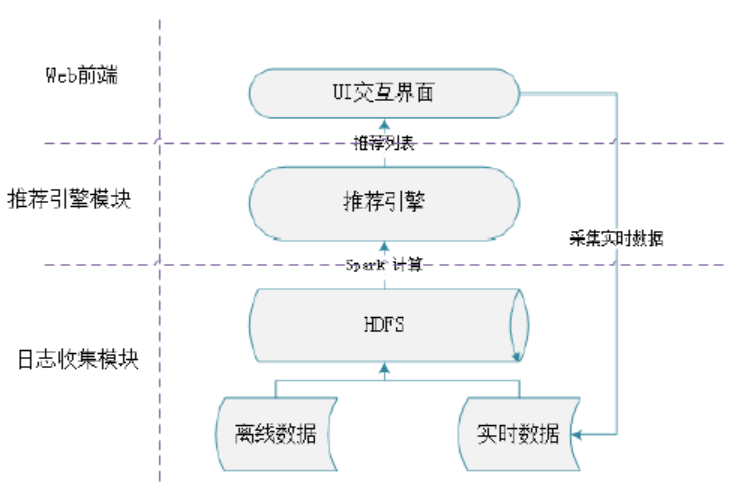
三、结论
因为本篇论文是基于Spark的高考推荐系统和设计与实现,通过阅读对于Spark计算框架有了初步的了解。Spark 开创了基于内存的计算方式,并将 Spark Core、Streaming、SQL、Machine Learning、Graph Processing 等模型统一到一个平台下,以统一的 API 公开,创新性地提出了基于 RDD的一体化解决方案。
四、参考文献
[1]孟真.基于Spark的高考推荐系统设计与实现[D].山东师范大学,2017.