模块
为什么要有模块
内置的函数是程序运行的第一时间就加载到内存
各个内置模块提供的方法都有用,但并不是时刻都可以用上
因此按照这些所有的方法涉及的方面进行分类
相同的功能就放在一个模块(就是一个py文件)里
就可以把我文件存储到硬盘
这样当我们不导入这个模块时,这个模块中的内容就不会出现在内存里
自定义模块
把不同的功能分到不同的模块 例如选课功能的主文件 :负责用户交互 登录 选择操作
好处是可以避免代码文件过大,使代码更清晰
模块的语法
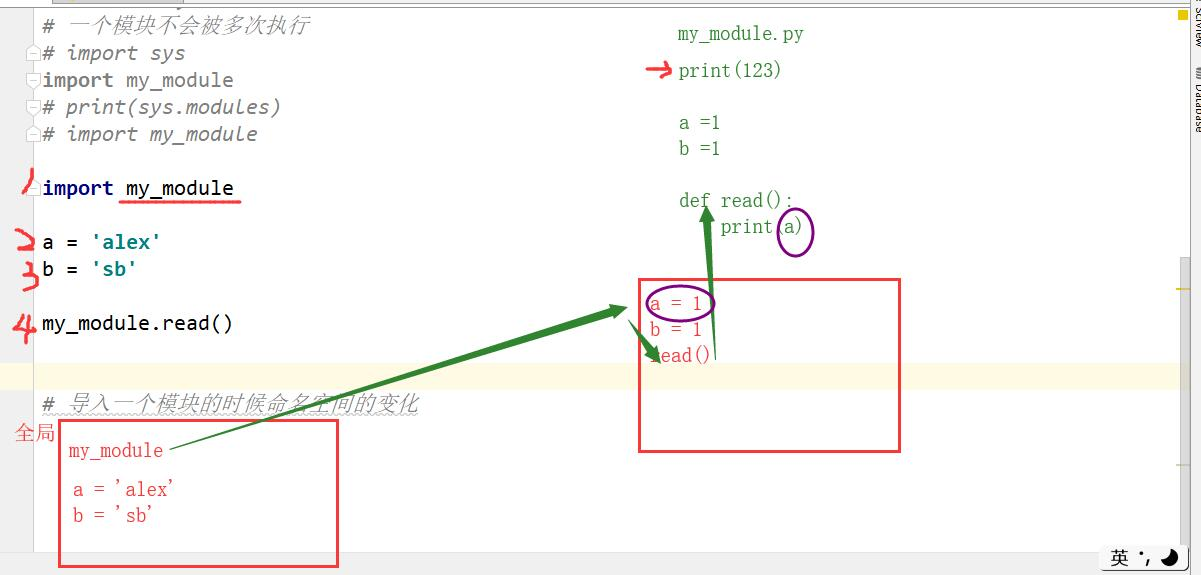
导入一个模块相当于什么
相当于执行了这个被导入的文件
一个模块可不可以多次导入
可以多次导入,不会报错但只会执行第一次导入的模块的内容
导入一个模块时内存空间的变化
1.创建了一个属于这个模块的命名空间
2.创建一个变量,指向这个命名空间
3.执行这个文件
import可以一行导入多个模块,但由于PEP88规范,不推荐使用,推荐逐行导入
as语法
import time as t:
t.time()
原来的形式为 import time as time as方式相当于把time重命名为t ,原来的time名字就失效了
重命名方法,一般用来做兼容
mode = 'pickle' if mode == 'pickle': import pickle as mode else: import json as mode def dump(): mode.dump(obj,f) def load(): mode.load(f)
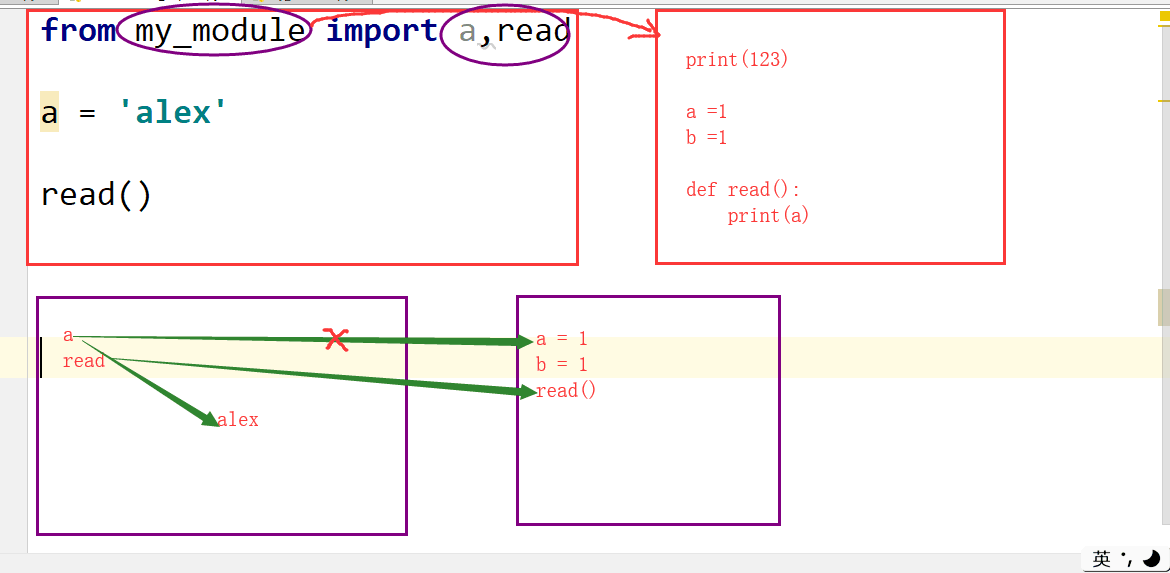
模块的from import
from my_module import a,read a = 'alex' read()
所有的导入
不管是import 还是from import
都是执行完整的那个被导入的文件
并且所有的文件的导入 都不会破坏模块中本身的命名空间
如果是import 模块名
那么是模块名 指向 整个文件的命名空间
如果是from 模块名 import 变量名
那么 是在本文件中创建了同名的变量名 指向模块中的变量值
可以导入多个变量,还可以重命名
from my_module import a as aa,b as bb,read as r
不要在文件里起的名字和导入的名字一样
from my_module import *
*表示导入所有
导入的模块中有 __all__['字符串数据类型变量名']
表示约束* 只能导入列表中含有的变量名
但__all__只能约束* 没有* all的约束就没用了
模块的搜索路径
以后创建的py文件名都要遵循变量命名规范
如果模块的py文件所在文件夹和当前文件夹不同
就要导入此模块
import sys print(sys.path) 所有模块的路径 sys.path.append(r'D:PyCharmProjects20day26demo') 要导入模块所在的文件夹 print(sys.path) 查看是否导入成功 import module1 导入模块
模块能不能被循环导入
在b文件中import a
在a文件中import b
在a文件中输出内容的顺序
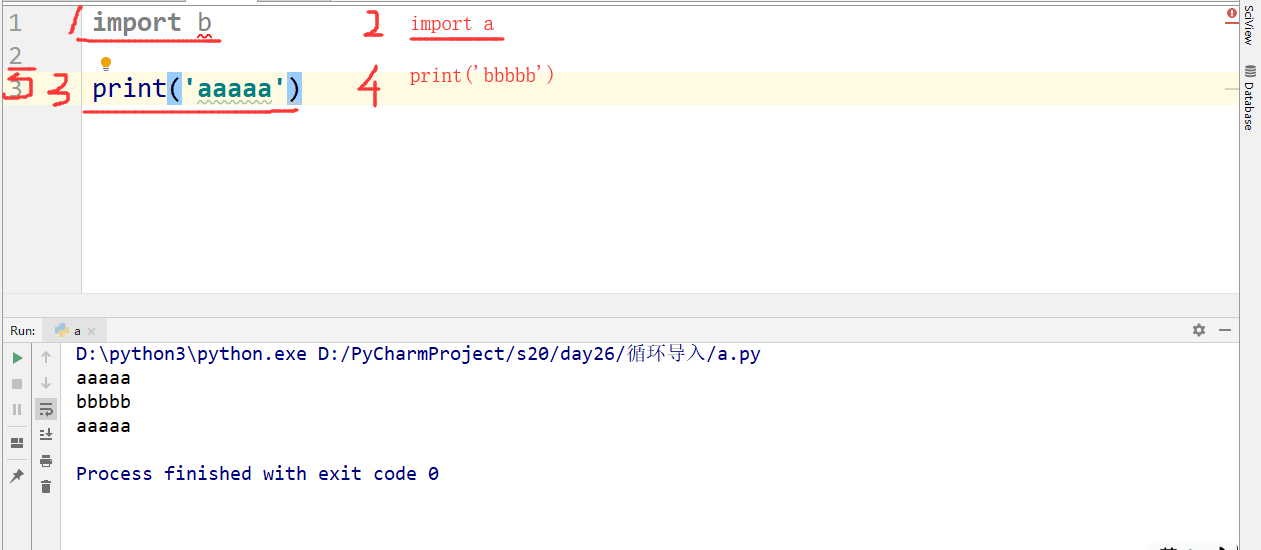
两个文件都增加变量的情况下,在a文件中打印b中的变量会报错

模块一旦被导入,再修改这个模块对应的文件是不会生效的
包
什么是包
模块是一个py文件,包就是包含一堆py文件的文件夹 (python2.7中要求所有的包都有一个__init__文件)
内置的也有模块和包之分
import 包
相当于执行了这个包中的init文件 像类的实例化
import导入
import 包.模块 as f:
f.模块方法()
根据包的导入要精准到模块名,不能精准到具体的函数名或者变量
然后使用 包.模块 或者重命名的方式
来使用这个模块中的所有名字
from import导入
from 包.包 import 模块
模块.方法()
或者
from 包.包.模块 import 方法名
方法名()
这种导入方式 import后面是至少精确到模块的
import后面不能有 .
from后面可以有 . 但 . 的左边永远是包名