DBLP是计算机领域内对研究的成果以作者为核心的一个计算机类英文文献的集成数据库系统。按年代列出了作者的科研成果。包括国际期刊和会议等公开发表的论文。和一般流行的情况不同,DBLP并没有使用数据库而是使用XML储存元数据。
采用将xml文件转化为weka可以识别的CSV文件的形式进行处理。
在关系挖掘中我们组选用了Apriori算法。Apriori算法是一种挖掘关联规则的频繁项集算法,其核心思想是通过候选集生成和情节的向下封闭检测两个阶段来挖掘频繁项集。该算法已经被广泛的应用到商业、网络安全等各个领域。也可采用FP-Growth算法,可能效果会更好,此处暂不涉及。
步骤一:数据预处理
DBLP的xml文件现在已经有1.2G之大。经过测试只有用VI和写字板才可以打开(电脑6G内存为例)。根本不能照常规方式处理,csv和arff格式都是weka支持的格式,但是经实验发现weka处理csv的速度好像更快,具体不知道什么原因,所以采用转化成csv的形式。
自己编写Parser,用于读取dblp.xml信息。由于我们只关注作者的协作关系信息,所以xml数据做以下处理:
1:文章名字不予考虑
2:只有单个作者的条目直接删除
3:作者发表文章篇数在80篇以下的删除
可以自己考虑,但为了挖掘出强支持支持度和置信度的数据,取80。删除时需要建立一个map映射统计作者数目,增加处理速度。
此步骤实际和apriori算法的第一步类似。每一篇文章只提取前8个作者,处理后得到大约20多万条数据。
4:每本书至多保留8个作者
5:由于weka中将" ' "等符号认为是特殊符号,所以在作者名字中遇到此类名字,将特殊符号删除,并不会造成大的影响。
保存为data80.csv,该程序处理了全部的370多万条数据,从中截取了有价值的部分信息交由weka进行进一步的分析处理。


package preprocess; public class Author_num { private String name; private int count; Author_num() { } Author_num(String aname,int acount) { name = aname; count = acount; } public void setname(String aname) { name = aname; } public void setcount(int acount) { count = acount; } public void addcount() { count++; } String getname() { return name; } int getcount() { return count; } }
package preprocess; import com.csvreader.CsvWriter; import java.util.List; import java.io.BufferedReader; import java.io.File; import java.io.FileReader; import java.nio.charset.Charset; import java.util.ArrayList; import java.util.*; import static java.lang.Math.*; public class Readxml{ private int Maxattribute = 8; //考虑的最大作者数 private int Maxnum = 100000000; //读取文件长度,xml行 private int booknum = 0; //记录当前已读的书本数目 private Map<String,Integer> map=new HashMap<String,Integer>(); //记录作者出现的次数 public void run() { System.out.println("reading..."); String line = ""; String Temp = ""; File filer = new File("D:\dblp.xml"); //CsvWriter wr =new CsvWriter("D:\writetestall90.csv",',',Charset.forName("SJIS")); int numofauthor=0;//管理作者数量 int thisnum=0; //记录实际作者数量 try { BufferedReader br = new BufferedReader(new FileReader(filer)); String[] contents = new String [Maxattribute]; //生成map映射记录所有作者和作者出版的书本数目 while(((line = br.readLine()) != null)) { if( (line.length()>8) && line.substring(0,8).equals("<author>")) { Temp = line.substring(8, (line.length()-9)); //清理数据中 出现的'和" while(Temp.indexOf("'") >= 0) { Temp = Temp.substring(0,Temp.indexOf("'"))+Temp.substring(Temp.indexOf("'")+1); } while(Temp.indexOf(""")>=0) { Temp = Temp.substring(0,Temp.indexOf("""))+Temp.substring(Temp.indexOf(""")+1); } if(map.get(Temp)==null) { map.put(Temp, 1); } else { map.put(Temp,map.get(Temp)+1); } } else if((line.length()>7) && line.substring(0, 7).equals("<title>")) { booknum++; System.out.println("已读书本数"+booknum); } } Set<String> keys = map.keySet(); Iterator<String> it = keys.iterator(); int count = 0; while(it.hasNext()) { String key = it.next(); if(map.get(key)>80) { System.out.println(key + "-->" + map.get(key)); count++; } } System.out.println("shuliang:"+count); br.close(); /* BufferedReader br1 = new BufferedReader(new FileReader(filer)); for(int i = 1;i<=Maxattribute;i++) { contents[i-1] = "author"+i; } wr.writeRecord(contents); while(((line = br1.readLine()) != null)&&(Maxnum-->0)) { if( (line.length()>8) && line.substring(0,8).equals("<author>")) { //每本书只考虑至多8个作者 if(numofauthor<Maxattribute) { Temp = line.substring(8, (line.length()-9)); while(Temp.indexOf("'") >= 0) { Temp = Temp.substring(0,Temp.indexOf("'"))+Temp.substring(Temp.indexOf("'")+1); } while(Temp.indexOf(""")>=0) { Temp = Temp.substring(0,Temp.indexOf("""))+Temp.substring(Temp.indexOf(""")+1); } //值保留出现次数大于80的作者 if(map.get(Temp)>80) { contents[numofauthor++]="'"+Temp+"'"; } } } else if((line.length()>7) && line.substring(0, 7).equals("<title>")) { thisnum = numofauthor; while(numofauthor<Maxattribute) { contents[numofauthor++]="?"; } Temp = line.substring(7, (line.length()-8)); //删除只有一个作者的书本记录 if(thisnum>1) { wr.writeRecord(contents); } numofauthor = 0; thisnum = 0; } } */ System.out.println("parseover!"); //br1.close(); //wr.close(); } catch(Exception e) { e.printStackTrace(); } } }
步骤二:使用weka中Apriori算法挖掘关联规则
1.最小支持度下界为0.00005(约100),conf为0.9 。
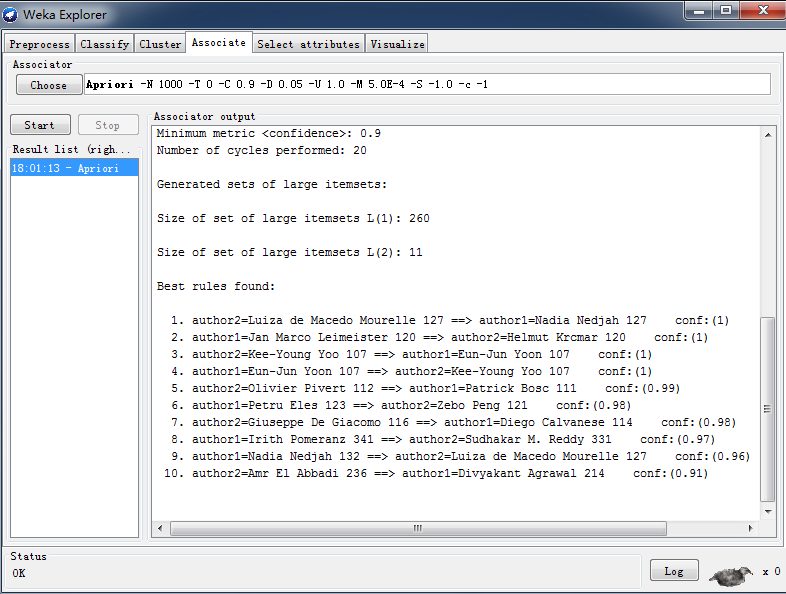
由上图可得出结论:214082篇文章中挖掘出10条规则,这些作者有着深层次的合作。
2:最小支持度为0.000025(约50),conf为0.8。

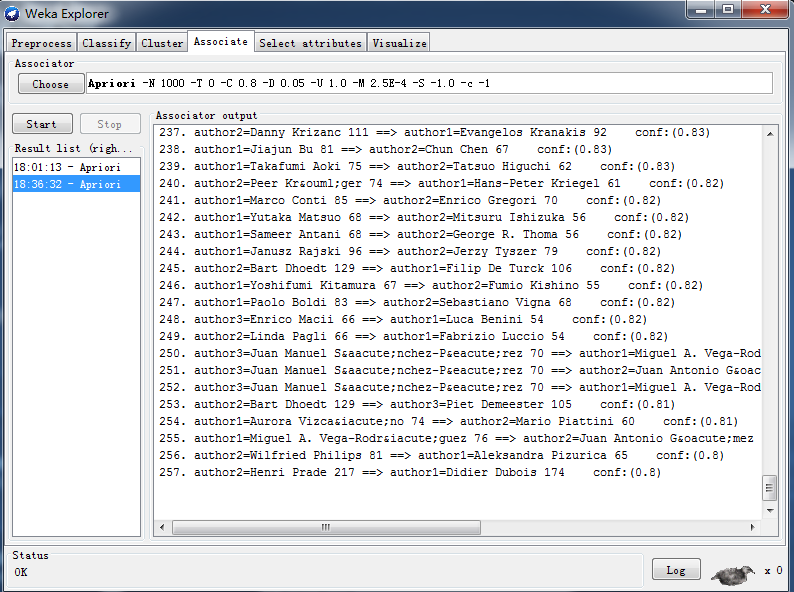
由上图可知,在降低最小置信度,并减小conf值时,增加了得到的规则。(10条增加到257条。)