浏览器缓存和Service Worker
@billshooting 2018-05-06 字数 6175 Follow me on Github
标签: BOM
1. 传统的HTTP浏览器缓存策略
在一个网页的生命周期中,开发者为了缩短用户打开页面的时间,通常会设置很多缓存。其中包括了:
- 浏览器缓存
- 代理服务器缓存(CDN缓存)
- 服务器缓存
- 数据库缓存
等各种缓存。这些缓存大多数和前端没什么关系,也不由前端开发者控制,其中和前端较为密切的是浏览器缓存,但它本质上也是由服务器控制的。
在Service Worker还未问世之前,浏览器缓存主要是由HTTP缓存策略和浏览器内置的存储功能(cookie,Local Storage,Session Storage等)来提供。其中HTTP缓存由于是钦定的,根正苗红,浏览器支持的也很好,是最常用的浏览器缓存技术。而通过浏览器内置存储功能来实现缓存,相比之下就没那么高端大气上档次了。因为这种方式没个标准范式,虽说可以通过JS进行控制显得比HTTP缓存灵活,但效果嘛就只能依赖程序员的水平了,也没有个统一的轮子能用,所以这种方式也就是小打小闹,不成气候。
下面介绍一下HTTP缓存的一些用法:
- Expires头部
早在HTTP协议被设计的时候,协议的起草者们就想到了缓存的事情,自然也有相应的功能,那就是Expires这个头部。每当浏览器请求时,服务器可以在相应的报文中附加这个Expires,它的典型值看起来是这样的:
Expires: Tue, 01 May 2018 11:37:06 GMT
也就是在该资源在世界协调时2018/05/01 11:37:06才过期,我的请求时间是2018/05/01 07:37:06,所以就是这个资源在4小时之后过期,4小时之内对该资源的请求都直接使用缓存,除非你用Ctrl+F5刷新。但是呢,这种控制明显是不够精细的,这是个HTTP1.0协议中规定的头部。由于我们现在都用HTTP2.0都已经来了,HTTP1.1已经全面普及了,这玩意自然已经用的不多了。
- Cache-Control头部
Expires头部只能控制过期时间,万一请求的资源在过期时间之前就更新了,那就可能会出现显示或者功能问题。为此,HTTP协议再更新到1.1版本的时候,增加了一个新的头部Cache-Control并规定:如果同时存在Cache-Control和Expires则前者有效。它有以下常用的值可选:publicprivatemax-ages-maxageno-cacheno-store等。一个典型的值看起来是以下这样:
Cache-Control: s-maxage=300, public, max-age=60
为了更好的说明各个字段的意义,先说下浏览器请求资源的步骤:
- 判断请求是否命中缓存,如命中则执行步骤2;如没有则执行步骤3;
- 判断缓存是否过期,如没有则直接返回;如过期则执行步骤3,并带上缓存信息;
- 浏览器向服务器请求资源;
- 服务器判断缓存信息,如资源尚未更新,则返回
304,如没有缓存信息或则资源已更新则返回200,并把资源返回。 - 浏览器根据响应头部决定要不要存储缓存(只有
no-store时不存储缓存信息)。
s-maxage表示共享缓存的时间,单位是s,也就是5分钟;
public表示这是个共享缓存,可以被其他session使用;
max-age意义与s-maxage差不多,只是它用于private的情形;
no-cache这种策略下,浏览器会跳过步骤2,并带上缓存信息向服务器发起请求。
no-store这种策略下,浏览器会跳过步骤5,由于没有缓存信息,每次浏览器请求时都不会带上缓存信息,就像第一次请求一样(Ctrl+F5效果)。
- Last-Modified/If-Modified-Since
上面说了,浏览器在有缓存信息的情况下,会带上缓存信息发起请求,那这个信息是怎么来的?又是怎么带在Request的头部当中呢?
原来,服务器在响应请求时,除了返回Cache-Control头部外,还会返回一个Last-Modified头部,用于指定该资源的服务器更新时间。当该资源在浏览器端过期时(由max-age或者no-cache决定),浏览器会带上缓存信息去发起请求,这个信息就由Request中的If-Modified-Since指定,通常也就是上次Response中Last-Modified的值。典型值如下:
//Response:
Last-Modified: Sat, 01 Jan 2000 00:00:00 GMT
//Request:
If-Modified-Since: Sat, 01 Jan 2000 00:00:00 GMT
- Etag/If-None-Match
Last-Modified/If-Modified-Since提供的控制已经比较多了,但有些时候,开发者还是不满意,因为它们只能提供对资源时间的控制,并只有精确到秒级。如果有些资源变化非常快,或者有些资源定时生成,但内容却是一样的,这些情况下Last-Modified/If-Modified-Since就不是很适用。
为此,HTTP1.1规定了Etag/If-None-Match这两个头部,它们的用法和Last-Modified/If-Modified-Since完全相同,一个用于响应,一个用于请求。只不过Etag用的不是时间,而是服务器规定的一个标签(通常是资源内容、大小、时间的hash值)。这样服务器通过这个头部可以更加啊精确地控制资源的缓存策略。
同样的,由于这个头部控制更加精细, 所以它的优先级会高于Last-Modified/If-Modified-Since,就像Cache-Control高于Expires一样。
2. Service Worker的原理
HTTP缓存已经足够强大了,那开发者还有什么不满意呢?后端的开发者自然没什么不满意,前端的开发者就要嘀咕了:“浏览器的事情,为什么要依赖于后端呢?后端就好好提供数据就行了,缓存这种事情我想自己控制”。确实有人这么尝试过,就是之前说的用Local Storage或者Session Storage来存储一些数据,但这种方法缺少很多关键的浏览器基础设施,比如异步存储、静态资源存储、URL匹配、请求拦截等功能。而Service Worker的出现填补了这些基础设施缺少的问题。
需要指出的是,Service Worker并非专门为缓存而设计,它还可以解决Web应用推送、后台长计算等问题。能解决精细化缓存控制,实在是由于它的功能强大,因为它本质上就是一个全新的JavaScript线程,运行在与主Javascript线程不同的上下文。service worker线程被设计成完成异步,一些原本在主线程中的同步API,如XMLHTTPRequest和localStorage是不能在service worker中使用的。
主Javascript线程是负责DOM的线程,而service worker线程被设计成无法访问DOM。这是很自然的,一般从事过客户端开发的开发者都知道,只能有一个UI线程,否则整个UI的控制会出现不可预估的问题。而保证UI顺滑不卡顿的原则就是尽量不在UI线程做大量计算和同步IO处理。
- sw线程能够用来和服务器沟通数据(service worker的上下文内置了fetch和Push API)
- 能够用来进行大量复杂的运算而不影响UI响应。
- 它能拦截所有的请求(通过监听fetch事件,任何对网络资源的请求都会触发该事件),并内置了一个完全异步的存储系统(Caches属性,完全异步并能存储全部种类的网络资源),这是它能精细化控制缓存的关键。
可以看出service worker功能非常强大,特别是拦击所有请求、充当代理服务器这个功能,是强大而危险的。所以为了这个功能不被别有用心的人利用,service worker必须运行在HTTPS的Origin中,同时localhost也被认为是安全的,可以用于调试开发使用。
3. Service Worker的缓存
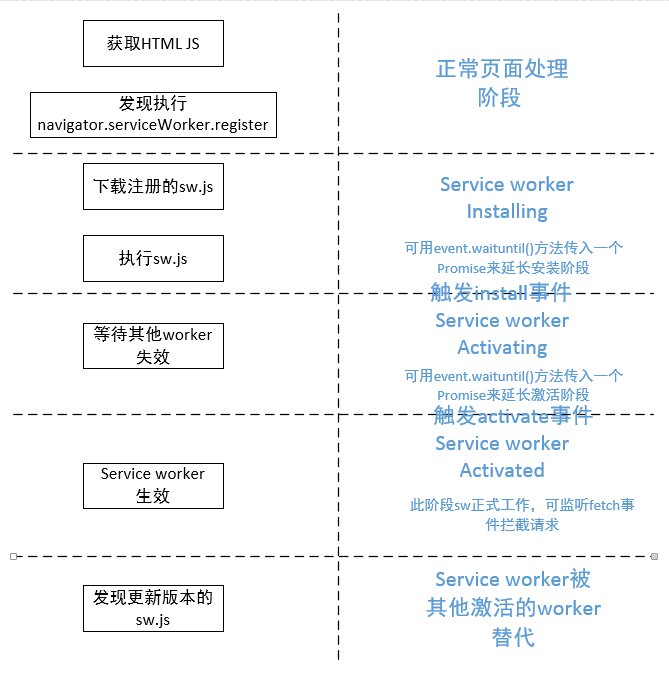
如前所述,service worker如果用于缓存则关键在于监听Fetch事件和管理Cache资源,不过在使用它们之前,得先把service worker激活才行。而service worker的激活则要经过以下步骤:
- 浏览器发现当前页面注册了service worker(通过
navigator.service.Worker.register('/sw.js')); - 浏览器下载
sw.js并执行,完成安装阶段; - service worker等待Origin中其他worker失效,然后完成激活阶段;
- service worker生效,注意它的生效范围不是当前页面,而是整个Origin。但是只有是在
register()成功之后打开的页面才受SW控制。所以执行注册脚本的页面通常需要重载一下,以便让SW获得完全的控制。
下图是整个service worker的生命流程:
下面用一个简单的例子来介绍service worker如何控制缓存,通常它在index.html中被注册:
代码清单:index.html
<!DOCTYPE html>
<html>
<head>
<meta charset="UTF-8">
<link href="style/style-1.css" rel-"stylesheet">
</head>
<body>
<img src="image/image-1.png" />
<script async src="js/script-1.js"></script>
<script>
if ('serivceWorker' in navigator) {
navigator.serviceWorker.register('/sw.js')
.then(reg => console.log('Service worker registered successfully!'))
.catch(err => console.log('Service worker failed to register!'));
}
</script>
</body>
</html>
可以看到这个页面有4个资源style-1.css image-1.png script-1.js以及sw.js。当页面中JS执行到register方法时,浏览器下载sw.js并根据sw.js内容准备安装Service worker。
代码清单: sw.js
let cacheName = 'indexCache';
self.addEventListener('install', event => {
//waitUntil接受一个Promise,直到这个promise被resolve,安装阶段才算结束
event.waitUntil(
caches.open(cacheName)
.then(cache => cacheAll(['/style/style-1.css',
'/image/image-1.png',
'/script/script-1.js',
]))
);
});
//监听activate事件,可以在这个事件里情况上个sw缓存的内容
self.addEventListener('activate', event => ...}
//监听fetch事件,可以拦截所有请求并处理
self.addEventListener('fetch', event => {
event.respondWith(
caches.match(event.request)
.then(res => {
//1. 如果请求的资源已被缓存,则直接返回
if (res) return res;
//2. 没有,则发起请求并缓存结果
let requestClone = event.request.clone();
return fetch(requestClone).then(netRes => {
if(!netRes || netRes.status !== 200) return netRes;
let responseClone = netRes.clone();
caches.open(cacheName).then(cache => cache.put(requestClone, responseClone));
return netRes;
});
})
);
});
可以看到,service worker在安装时就缓存了三个资源文件,如果下次该Origin下有页面对这三个资源发起请求,则会被Fetch事件拦截,然后直接用缓存返回。如果对其他资源发起请求,则会使用网络资源作为响应,并把这些资源再次存储起来。
可以看到仅用几十行代码就完成了一个非常强大的缓存控制功能,你还可以对特定的几个资源做自己的处理,取决你想怎么控制你的资源。目前还有一个问题尚待解决,那就是如果资源更新了,缓存该怎么办?目前有两种方法可以做到:
- 更新
sw.js文件,一旦浏览器发现安装使用的sw.js是不同的(通过计算hash值),浏览器就会重新安装service worker,你可以在安装激活的过程中清空之前的缓存,这样浏览器就会使用服务器上最新的资源。 - 对资源文件进行版本控制,就像我上面的例子一样你可以用
style-2.css来代替style-1.css,这样service worker就会使用新的资源并缓存它。当然版本号不应该这么简单,最好是使用文件的内容+修改时间+大小的hash值来作为版本号。
以上两种方法都是可靠的,第一种方法的可靠性由浏览器保证,第二种方法则是已经久经考验,目前大多数网站的静态资源更新策略都是用的类似于第二种方法的版本控制。这两种方法通常会混在一起使用,因为你在调整资源的版本号的时候,必须要更新sw.js中资源列表,导致sw.js文件本身就修改。
还有个问题需要注意,那就是sw.js本身也会被HTTP缓存策略缓存。通过对sw.js文件名进行版本控制,可以避免因为service worker安装文件被缓存而导致资源更新不及时的问题。
4. Service Worker的缓存延伸应用
前面说过,service worker的出现并不是单纯的为解决精细化控制浏览器缓存问题的。它能充当代理服务器这一能力(通过拦截所有请求实现),能够实现HTTP缓存无法实现的功能:离线应用。因为在HTTP缓存策略下,如果一个资源过了服务器规定的到期时间,则必须要发起请求,一旦网络连接有问题,整个网站就会出现功能问题。而在service worker控制下的缓存,能够在代码中发现网络连接问题并直接返回缓存的资源。这种方式返回的响应对于浏览器来说是透明的,它会认为该响应就是服务器发送回来的资源。
借助于上述能力以及service worker带来的推送能力,基于Web的应用已经能够媲美原生应用了。谷歌将这种Web应用称为PWA(Progressive Web Application)。
随着Web应用的功能越来越强大,安卓和IOS上套壳应用越来越多,最近微软也宣布win 10 上UWP应用可以采用PWA模式开发。至此跨平台应用开发的主流技术变得越来越清晰起来,业界在经历了Java-SWT,QT,Xamarin的尝试之后,HTML+CSS+Javascript这套始于浏览器的技术,已经成为跨平台应用开发的主流技术。