参考:https://blog.csdn.net/qq_32719287/article/details/79513164
1、sql 语句中count()有条件的时候为什么要加上or null。
如count(province = '浙江' or NULL) 这部分,为什么要加上or NULL,直接count(province='浙江')有什么问题吗?不就是要找province = '浙江'的数据吗,为什么要计算NULL的数据。
答案:
因为当 province不是浙江时 province='浙江' 结果false。不是 NULL,
count在值是NULL是不统计数, (count('任意内容')都会统计出所有记录数,因为count只有在遇见null时不计数,即count(null)==0,因此前者单引号内不管输入什么值都会统计出所有记录数),至于加上or NULL , 很像其他编程里的or运算符,第一个表达式是true就是不执行or后面的表达式,第一个表达式是false 执行or后面的表达式 。当province不为浙江时province = '浙江' or NULL 的结果是NULL,Count才不会统计上这条记录数
2、以上参考链接,换汤不换药。分析如下所示。为啥用到上面的这个知识点了呢,因为要做多个数据表、的各个省份、数据量统计。因为每天都要统计。需要统计增量和全量数据量,一开始是使用SQL统计的,发现每天重复一些没有用的工作,甚是无聊,后来我创建了视图,并把这块工作交给了同事,同时想了一下午,有没有更加方便快捷的sql,经过一下午的思考和尝试,感觉没有更加好的解决方法,who知道,后来来了一个同事,专一做etl的,他写了一个大SQL,解决了这个问题,一个sql就统计出多个数据表、的各个省份、数据量统计。再次验证,头发短,见识少,轻易说不行,哎,知识学无止境。
分析如下所示:
先说业务场景,再说具体原因。
3、业务场景。
模拟的SQL如下所示,主要事项同库、多个数据表、每个省份的全量的数据量。
1 SELECT 'db_province_1' as tableName,count(province='浙江省' or null) as 浙江省,count(province='北京省' or null) as 北京省,count(province='河南省' or null) as 河南省,count(province='江苏省' or null) as 江苏省,count(province='辽宁省' or null) as 辽宁省,count(province='吉林省' or null) as 吉林省,count(province='河北省' or null) as 河北省,count(province='天津省' or null) as 天津省,count(province='深圳省' or null) as 深圳省,count(province='西藏省' or null) as 西藏省,count(province='四川省' or null) as 四川省 from tb_province 2 union all 3 SELECT 'db_province_2' as tableName,count(province='浙江省' or null) as 浙江省,count(province='北京省' or null) as 北京省,count(province='河南省' or null) as 河南省,count(province='江苏省' or null) as 江苏省,count(province='辽宁省' or null) as 辽宁省,count(province='吉林省' or null) as 吉林省,count(province='河北省' or null) as 河北省,count(province='天津省' or null) as 天津省,count(province='深圳省' or null) as 深圳省,count(province='西藏省' or null) as 西藏省,count(province='四川省' or null) as 四川省 from tb_province_2 4 union all 5 SELECT 'db_province_3' as tableName,count(province='浙江省' or null) as 浙江省,count(province='北京省' or null) as 北京省,count(province='河南省' or null) as 河南省,count(province='江苏省' or null) as 江苏省,count(province='辽宁省' or null) as 辽宁省,count(province='吉林省' or null) as 吉林省,count(province='河北省' or null) as 河北省,count(province='天津省' or null) as 天津省,count(province='深圳省' or null) as 深圳省,count(province='西藏省' or null) as 西藏省,count(province='四川省' or null) as 四川省 from tb_province_3
效果如下所示:
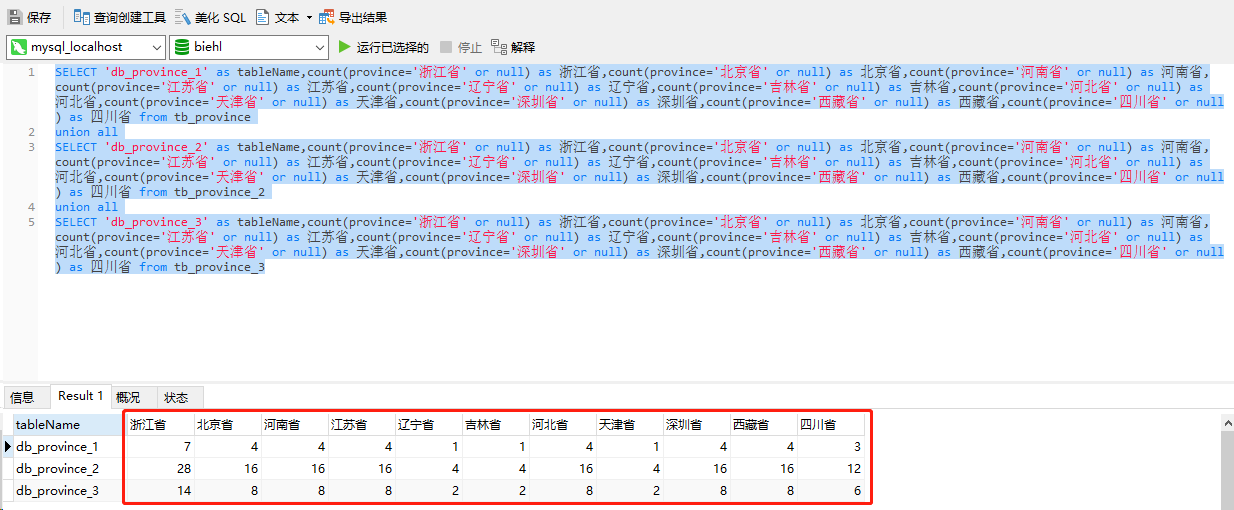
这样的话,我每天一个sql就解决了我的需求,第一版是执行几十个sql,第二版执行几十个视图。第一版和第二版都让人痛不欲生的。第三版,即介绍这版大大减轻了工作量哦。
分析如下所示:

具体执行sql如下所示:
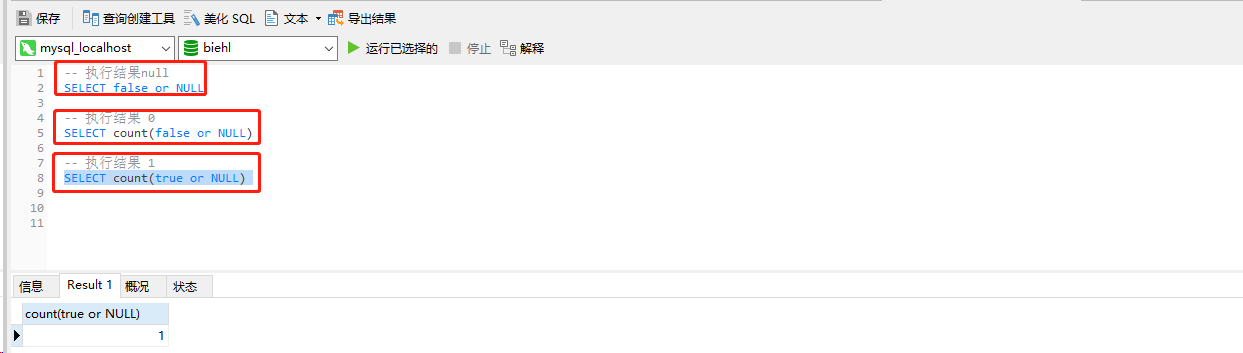
可以看到如果将true或者false替换为province='浙江省'的话,执行结果就是统计出每张表各个省份的数据表数据量。

最后两个sql对比就可以看到,执行结果的效果。自己可以动手试试哦。
待续......