在url跳转页面的时候,参数值中的#不见了,一直没有处理,今天有空看了一下,后来发现后台的过滤器之类的都没有处理,就比较奇怪了,原来是特殊字符的问题。
一:Url中的特殊字符
1.说明
这里还是需要做到一个眼熟的,遇到的时候可以快速定位到。
具体现象就是 用URL传参数的时候,用&符号连接,如果某一个参数中含"#$ ^ & * + ="这些符号的时候,在另一个页面getParameter就会取不到传过来的参数。
2.特殊字符

3.特殊字符的含义
空格换成加号(+)
正斜杠(/)分隔目录和子目录
问号(?)分隔URL和查询
百分号(%)制定特殊字符
#号指定书签
&号分隔参数
4.为啥要编码
通常如果一样东西需要编码,说明这样东西并不适合传输。原因多种多样,如Size过大,包含隐私数据,对于Url来说,之所以要进行编码,是因为Url中有些字符会引起歧义。
例如Url参数字符串中使用key=value键值对这样的形式来传参,键值对之间以&符号分隔,如/s?q=abc& ie=utf-8。如果你的value字符串中包含了=或者&,那么势必会造成接收Url的服务器解析错误,因此必须将引起歧义的&和= 符号进行转义,也就是对其进行编码。
又如,Url的编码格式采用的是ASCII码,而不是Unicode,这也就是说你不能在Url中包含任何非ASCII字符,例如中文。否则如果客户端浏览器和服务端浏览器支持的字符集不同的情况下,中文可能会造成问题。
Url编码的原则就是使用安全的字符(没有特殊用途或者特殊意义的可打印字符)去表示那些不安全的字符。
5.Url可以使用的字符
RFC3986文档规定,Url中只允许包含英文字母(a-zA-Z)、数字(0-9)、- _ . ~ 4个特殊字符以及所有保留字符。
6.保留字符
![]()
7.不安全字符
还有一些字符,当他们直接放在Url中的时候,可能会引起解析程序的歧义。这些字符被视为不安全字符,原因有很多。

二:JS处理
1.escape,encodeURI和encodeURIComponent的区别
Javascript中提供了3对函数用来对Url编码以得到合法的Url,它们分别是escape / unescape,encodeURI / decodeURI和encodeURIComponent / decodeURIComponent。由于解码和编码的过程是可逆的,因此这里只解释编码的过程。
这三个编码的函数——escape,encodeURI,encodeURIComponent——都是用于将不安全不合法的Url字符转换为合法的Url字符表示,它们有以下几个不同点。
2.其安全字符
就是不会编码的字符

3.对Unicode的编码不同
这三个函数对于ASCII字符的编码方式相同,均是使用百分号+两位十六进制字符来表示。
但是对于Unicode字符,escape的编码方式是%uxxxx,其中的xxxx是用来表示unicode字符的4位十六进制字符。这种方式已经被W3C废弃了。但是在ECMA-262标准中仍然保留着escape的这种编码语法。
encodeURI和encodeURIComponent则使用UTF-8对非ASCII字符进行编码,然后再进行百分号编码。这是RFC推荐的。因此建议尽可能的使用这两个函数替代escape进行编码。
4.小实验
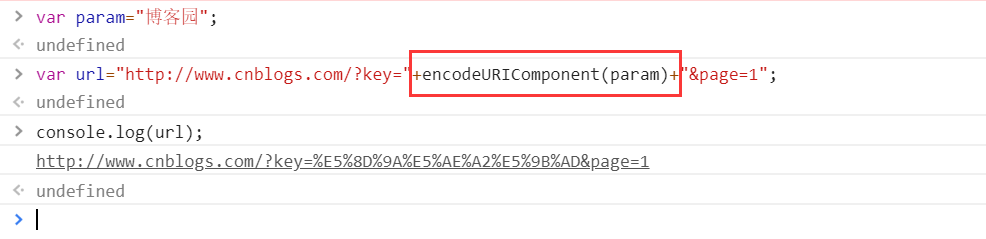
三:总结
今天遇到的问题,查了一下,还是更适合使用encodeURIComponent()
当决定使用哪个函数的时候,还需要查一下其安全字符。