前言
在hadoop的FsShell命令中,估计很多人比较常用的就是hadoop fs -ls,-lsr,-cat等等这样的与Linux系统中几乎一致的文件系统相关的命令.但是仔细想想,这里还是有一些些的不同的.首先,从规模的本身来看,单机版的文件系统,文件数目少,内容不多,而HDFS则是一个分布式系统,里面能容纳巨大数量的文件目录.因此在这个前提之下,你如果随意执行ls或lsr命令,有的时候会得到恐怖的数据条数的显示记录,有的时候我们不得不通过Ctrl+C的方式中止命令.所以对于未知目录的命令执行,是否可以在ls命令中增加显示限制的参数呢,这样可以控制一下文件记录信息的数量.这就是本文的一个出发点.
Ls命令工作流程
要想添加参数,就要先理解目前Ls命令工作的原理和过程.下面我从源代码的层面进行简单的分析.首先这里有个结构关系:
从左到右依次为孩子到父亲.所以Command类是最基础的类,命令行操作的执行入口就在这里.进入到Command.java方法中,你会看到有下面这个方法:
/**
* Invokes the command handler. The default behavior is to process options,
* expand arguments, and then process each argument.
* <pre>
* run
* |-> {@link #processOptions(LinkedList)}
* -> {@link #processRawArguments(LinkedList)}
* |-> {@link #expandArguments(LinkedList)}
* | -> {@link #expandArgument(String)}*
* -> {@link #processArguments(LinkedList)}
* |-> {@link #processArgument(PathData)}*
* | |-> {@link #processPathArgument(PathData)}
* | -> {@link #processPaths(PathData, PathData...)}
* | -> {@link #processPath(PathData)}*
* -> {@link #processNonexistentPath(PathData)}
* </pre>
* Most commands will chose to implement just
* {@link #processOptions(LinkedList)} and {@link #processPath(PathData)}
*
* @param argv the list of command line arguments
* @return the exit code for the command
* @throws IllegalArgumentException if called with invalid arguments
*/
public int run(String...argv) {
LinkedList<String> args = new LinkedList<String>(Arrays.asList(argv));
try {
if (isDeprecated()) {
displayWarning(
"DEPRECATED: Please use '"+ getReplacementCommand() + "' instead.");
}
processOptions(args);
processRawArguments(args);
} catch (IOException e) {
displayError(e);
}
return (numErrors == 0) ? exitCode : exitCodeForError();
}首先会进行参数的预处理,在这里会把参数中的一些参数给剥离出来,因为这是一个抽象方法,所以最终的实现类在Ls.java中,代码如下:
@Override
protected void processOptions(LinkedList<String> args)
throws IOException {
CommandFormat cf = new CommandFormat(0, Integer.MAX_VALUE, "d", "h", "R");
cf.parse(args);
dirRecurse = !cf.getOpt("d");
setRecursive(cf.getOpt("R") && dirRecurse);
humanReadable = cf.getOpt("h");
if (args.isEmpty()) args.add(Path.CUR_DIR);
} /**
* Allows commands that don't use paths to handle the raw arguments.
* Default behavior is to expand the arguments via
* {@link #expandArguments(LinkedList)} and pass the resulting list to
* {@link #processArguments(LinkedList)}
* @param args the list of argument strings
* @throws IOException
*/
protected void processRawArguments(LinkedList<String> args)
throws IOException {
processArguments(expandArguments(args));
} /**
* Expands a list of arguments into {@link PathData} objects. The default
* behavior is to call {@link #expandArgument(String)} on each element
* which by default globs the argument. The loop catches IOExceptions,
* increments the error count, and displays the exception.
* @param args strings to expand into {@link PathData} objects
* @return list of all {@link PathData} objects the arguments
* @throws IOException if anything goes wrong...
*/
protected LinkedList<PathData> expandArguments(LinkedList<String> args)
throws IOException {
LinkedList<PathData> expandedArgs = new LinkedList<PathData>();
for (String arg : args) {
try {
expandedArgs.addAll(expandArgument(arg));
} catch (IOException e) { // other exceptions are probably nasty
displayError(e);
}
}
return expandedArgs;
} /**
* Expand the given argument into a list of {@link PathData} objects.
* The default behavior is to expand globs. Commands may override to
* perform other expansions on an argument.
* @param arg string pattern to expand
* @return list of {@link PathData} objects
* @throws IOException if anything goes wrong...
*/
protected List<PathData> expandArgument(String arg) throws IOException {
PathData[] items = PathData.expandAsGlob(arg, getConf());
if (items.length == 0) {
// it's a glob that failed to match
throw new PathNotFoundException(arg);
}
return Arrays.asList(items);
}/**
* Processes the command's list of expanded arguments.
* {@link #processArgument(PathData)} will be invoked with each item
* in the list. The loop catches IOExceptions, increments the error
* count, and displays the exception.
* @param args a list of {@link PathData} to process
* @throws IOException if anything goes wrong...
*/
protected void processArguments(LinkedList<PathData> args)
throws IOException {
for (PathData arg : args) {
try {
processArgument(arg);
} catch (IOException e) {
displayError(e);
}
}
} /**
* Processes a {@link PathData} item, calling
* {@link #processPathArgument(PathData)} or
* {@link #processNonexistentPath(PathData)} on each item.
* @param item {@link PathData} item to process
* @throws IOException if anything goes wrong...
*/
protected void processArgument(PathData item) throws IOException {
if (item.exists) {
processPathArgument(item);
} else {
processNonexistentPath(item);
}
} @Override
protected void processPathArgument(PathData item) throws IOException {
// implicitly recurse once for cmdline directories
if (dirRecurse && item.stat.isDirectory()) {
recursePath(item);
} else {
super.processPathArgument(item);
}
} /**
* This is the last chance to modify an argument before going into the
* (possibly) recursive {@link #processPaths(PathData, PathData...)}
* -> {@link #processPath(PathData)} loop. Ex. ls and du use this to
* expand out directories.
* @param item a {@link PathData} representing a path which exists
* @throws IOException if anything goes wrong...
*/
protected void processPathArgument(PathData item) throws IOException {
// null indicates that the call is not via recursion, ie. there is
// no parent directory that was expanded
depth = 0;
processPaths(null, item);
} @Override
protected void processPaths(PathData parent, PathData ... items)
throws IOException {
if (parent != null && !isRecursive() && items.length != 0) {
out.println("Found " + items.length + " items");
}
adjustColumnWidths(items);
super.processPaths(parent, items);
} /**
* Iterates over the given expanded paths and invokes
* {@link #processPath(PathData)} on each element. If "recursive" is true,
* will do a post-visit DFS on directories.
* @param parent if called via a recurse, will be the parent dir, else null
* @param items a list of {@link PathData} objects to process
* @throws IOException if anything goes wrong...
*/
protected void processPaths(PathData parent, PathData ... items)
throws IOException {
// TODO: this really should be iterative
for (PathData item : items) {
try {
processPath(item);
if (recursive && isPathRecursable(item)) {
recursePath(item);
}
postProcessPath(item);
} catch (IOException e) {
displayError(e);
}
}
}@Override
protected void processPath(PathData item) throws IOException {
FileStatus stat = item.stat;
String line = String.format(lineFormat,
(stat.isDirectory() ? "d" : "-"),
stat.getPermission() + (stat.getPermission().getAclBit() ? "+" : " "),
(stat.isFile() ? stat.getReplication() : "-"),
stat.getOwner(),
stat.getGroup(),
formatSize(stat.getLen()),
dateFormat.format(new Date(stat.getModificationTime())),
item
);
out.println(line);
}Ls限制显示参数的添加
现在我来教大家如何新增ls命令参数.首先定义参数说明
public static final String NAME = "ls";
public static final String USAGE = "[-d] [-h] [-R] [-l] [<path> ...]";
public static final String DESCRIPTION =
"List the contents that match the specified file pattern. If " +
"path is not specified, the contents of /user/<currentUser> " +
@@ -53,7 +55,9 @@ public static void registerCommands(CommandFactory factory) {
"-d: Directories are listed as plain files.
" +
"-h: Formats the sizes of files in a human-readable fashion " +
"rather than a number of bytes.
" +=
"-R: Recursively list the contents of directories.
" +
"-l: The limited number of files records's info which would be " +
"displayed, the max value is 1024.
";定义相关变量
protected int maxRepl = 3, maxLen = 10, maxOwner = 0, maxGroup = 0;
protected int limitedDisplayedNum = 1024;
protected int displayedRecordNum = 0;
protected String lineFormat;
protected boolean dirRecurse;
protected boolean limitedDisplay = false;
protected boolean humanReadable = false; @Override
protected void processOptions(LinkedList<String> args)
throws IOException {
CommandFormat cf = new CommandFormat(0, Integer.MAX_VALUE, "d", "h", "R", "l");
cf.parse(args);
dirRecurse = !cf.getOpt("d");
setRecursive(cf.getOpt("R") && dirRecurse);
humanReadable = cf.getOpt("h");
limitedDisplay = cf.getOpt("l");
if (args.isEmpty()) args.add(Path.CUR_DIR);
}protected void processPaths(PathData parent, PathData ... items)
if (parent != null && !isRecursive() && items.length != 0) {
out.println("Found " + items.length " items");
}
PathData[] newItems;
if (limitedDisplay) {
int length = items.length;
if (length > limitedDisplayedNum) {
length = limitedDisplayedNum;
out.println("Found " + items.length + " items"
+ ", more than the limited displayed num " + limitedDisplayedNum);
}
newItems = new PathData[length];
for (int i = 0; i < length; i++) {
newItems[i] = items[i];
}
items = null;
} else {
newItems = items;
}
adjustColumnWidths(newItems);
super.processPaths(parent, newItems);
}逻辑不难. 下面是测试的一个例子,我在测试的jar包中设置了默认限制数目1个,然后用ls命令分别测试带参数与不带参数的情况,测试截图如下:
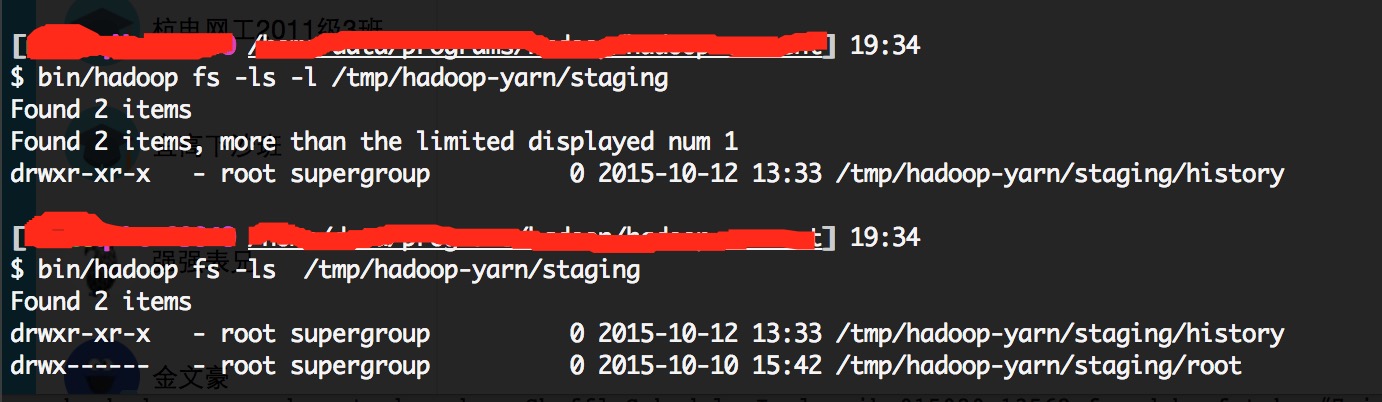
此部分代码已经提交至开源社区,编号HADOOP-12641.链接在文章尾部列出.
相关链接
Issue链接:https://issues.apache.org/jira/browse/HADOOP-12641
github patch链接:https://github.com/linyiqun/open-source-patch/blob/master/hadoop/HADOOP-12641/HADOOP-12641.001.patch