1. 安装 Hadoop 和 Spark
进入 Linux 系统,参照本教程官网“实验指南”栏目的“Hadoop 的安装和使用”,完成 Hadoop 伪分布式模式的安装。完成 Hadoop 的安装以后,再安装Spark(Local 模式)。
2. HDFS 常用操作
使用 hadoop 用户名登录进入 Linux 系统,启动 Hadoop,参照相关 Hadoop 书籍或网络资料,或者也可以参考本教程官网的“实验指南”栏目的“HDFS 操作常用 Shell 命令”,
使用Hadoop 提供的 Shell 命令完成如下操作:
(1) 启动Hadoop,在HDFS 中创建用户目录“/user/hadoop”;
hadoop fs -mkdir /user/hadoop
(2) 在 Linux 系统的本地文件系统的“/home/hadoop”目录下新建一个文本文件 test.txt,并在该文件中随便输入一些内容,然后上传到 HDFS 的“/user/hadoop”目录下;
hdfs dfs -put /home/hadoop/test.txt /usr/hadoop
(3) 把 HDFS 中“/user/hadoop”目录下的 test.txt 文件,下载到 Linux 系统的本地文件系统中的“/home/hadoop/下载”目录下;
hdfs dfs -get /user/hadoop/test.txt /home/hadoop
(4) 将HDFS 中“/user/hadoop”目录下的test.txt文件的内容输出到终端中进行显示;
hdfs dfs -cat /user/hadoop/test.txt
(5) 在 HDFS 中的“/user/hadoop” 目录下, 创建子目录 input ,把 HDFS 中 “/user/hadoop”目录下的 test.txt 文件,复制到“/user/hadoop/input”目录下;
hadoop fs -mkdir /user/hadoop/input
hdfs dfs -cp /user/hadoop/test.txt /user/hadoop/input
(6) 删除HDFS 中“/user/hadoop”目录下的test.txt文件,删除HDFS 中“/user/hadoop”目录下的 input 子目录及其子目录下的所有内容。
hdfs dfs -rm /user/hadoop/test.txt
hdfs dfs -rm -r /user/hadoop/input
3. Spark 读取文件系统的数据
(1) 在 spark-shell 中读取Linux 系统本地文件“/home/hadoop/test.txt”,然后统计出文件的行数;
bin/spark-shell val textFile = sc.textFile("file:///home/hadoop/test1.txt") textFile.count()

(2) 在 spark-shell 中读取HDFS 系统文件“/user/hadoop/test.txt”(如果该文件不存在,请先创建),然后,统计出文件的行数;
val textFile = sc.textFile("hdfs://node01:8020/user/hadoop/test.txt")
textFile.count()

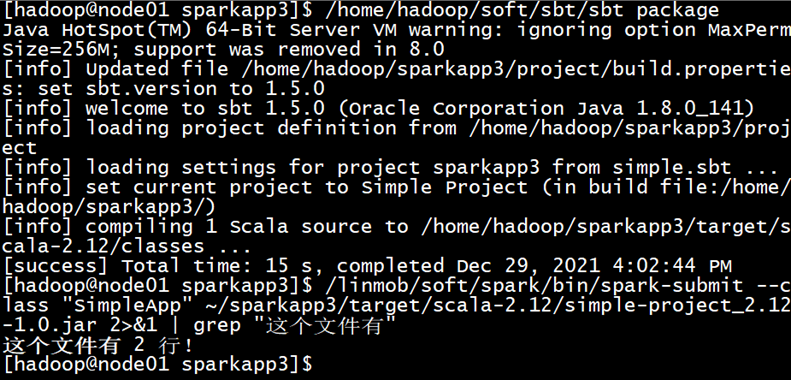
(3) 编写独立应用程序,读取 HDFS 系统文件“/user/hadoop/test.txt”(如果该文件不存在,请先创建),然后,统计出文件的行数;通过 sbt 工具将整个应用程序编译打包成 JAR 包,并将生成的JAR 包通过 spark-submit 提交到 Spark 中运行命令。
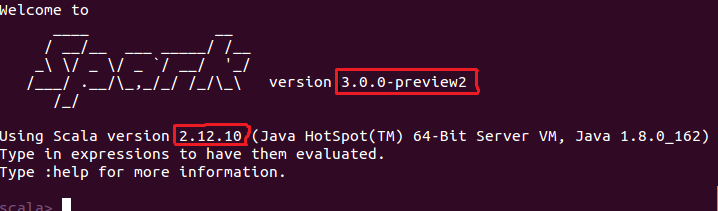
cd ~ # 进入用户主文件夹 mkdir ./sparkapp3 # 创建应用程序根目录 mkdir -p ./sparkapp3/src/main/scala # 创建所需的文件夹结构 vim ./sparkapp3/src/main/scala/SimpleApp.scala ---------------------------------------------------------- /* SimpleApp.scala */ import org.apache.spark.SparkContext import org.apache.spark.SparkContext._ import org.apache.spark.SparkConf object SimpleApp { def main(args: Array[String]) { val logFile = "hdfs://localhost:9000/home/hadoop/test.csv" val conf = new SparkConf().setAppName("Simple Application") val sc = new SparkContext(conf) val logData = sc.textFile(logFile, 2) val num = logData.count() println("这个文件有 %d 行!".format(num)) } } ---------------------------------------------------------- vim ./sparkapp3/simple.sbt ---------------------------------------------------------- name := "Simple Project" version := "1.0" scalaVersion := "2.12.10" libraryDependencies += "org.apache.spark" %% "spark-core" % "3.0.0-preview2" ----------------------------------------------------------
注意:文件 simple.sbt 需要指明 Spark 和 Scala 的版本,如下图所示:
cd ~/sparkapp3 /usr/local/sbt/sbt package #这里是需要安装一个sbt,教程在下一篇linux安装sbt - 我试试这个昵称好使不 - 博客园 (cnblogs.com)
/usr/local/spark/bin/spark-submit --class "SimpleApp" ~/sparkapp3/target/scala-2.12/simple-project_2.12-1.0.jar 2>&1 | grep "这个文件有"