前言
在hadoop集群中,一个datanode执行启动操作后,会在namenode中进行节点的注册,然后namenode会与这个新注册的datanode通过心跳的形式,进行信息的传输,一方面datanode将会汇报自身的block块的情况,另一方面然后namenode接受到这些块后,进行一段分析,然后返回datanode相应的反馈命令.同时这个操作也用来判断,节点是否已经是dead状态了.但是这个过程只是宏观层面的一个过程描述,了解这点背景知识其实远远不够,一旦HDFS中出现了block块异常的情况,比如突然在某个时间点underReplicated blocks突然变多了,或者说pengdingDeleted blocks变多了,这个时候该怎么办,你需要了解这些块是如何被添加到这些操作对应的block列表里的,只有了解了hdfs中这些细节的处理,你才能够有根据的发现原因.本篇博文给大家分享的是namenode对与datanode上报块的处理过程,里面的很多东西还是非常有必要留意的.
ProcessReport的block块处理5大分支
在前言中提到,dn的block块上报是在心跳的过程中进行的,同样在上一篇我的文章中Hadoop中止下线操作后大量剩余复制块的解决方案也略微提过,在下面这段代码中执行的:
/**
* Main loop for each BP thread. Run until shutdown,
* forever calling remote NameNode functions.
*/
private void offerService() throws Exception {
...
//
// Now loop for a long time....
//
while (shouldRun()) {
try {
...
List<DatanodeCommand> cmds = blockReport();
processCommand(cmds == null ? null : cmds.toArray(new DatanodeCommand[cmds.size()]));
...private Collection<Block> processReport(
final DatanodeStorageInfo storageInfo,
final BlockListAsLongs report) throws IOException {
// Normal case:
// Modify the (block-->datanode) map, according to the difference
// between the old and new block report.
//
...
}private Collection<Block> processReport(
final DatanodeStorageInfo storageInfo,
final BlockListAsLongs report) throws IOException {
// Normal case:
// Modify the (block-->datanode) map, according to the difference
// between the old and new block report.
//
// 新添加的块
Collection<BlockInfoContiguous> toAdd = new LinkedList<BlockInfoContiguous>();
// 待移除的块
Collection<Block> toRemove = new TreeSet<Block>();
// 无效的块
Collection<Block> toInvalidate = new LinkedList<Block>();
// 损坏的块
Collection<BlockToMarkCorrupt> toCorrupt = new LinkedList<BlockToMarkCorrupt>();
// 正在复制中的块
Collection<StatefulBlockInfo> toUC = new LinkedList<StatefulBlockInfo>();
...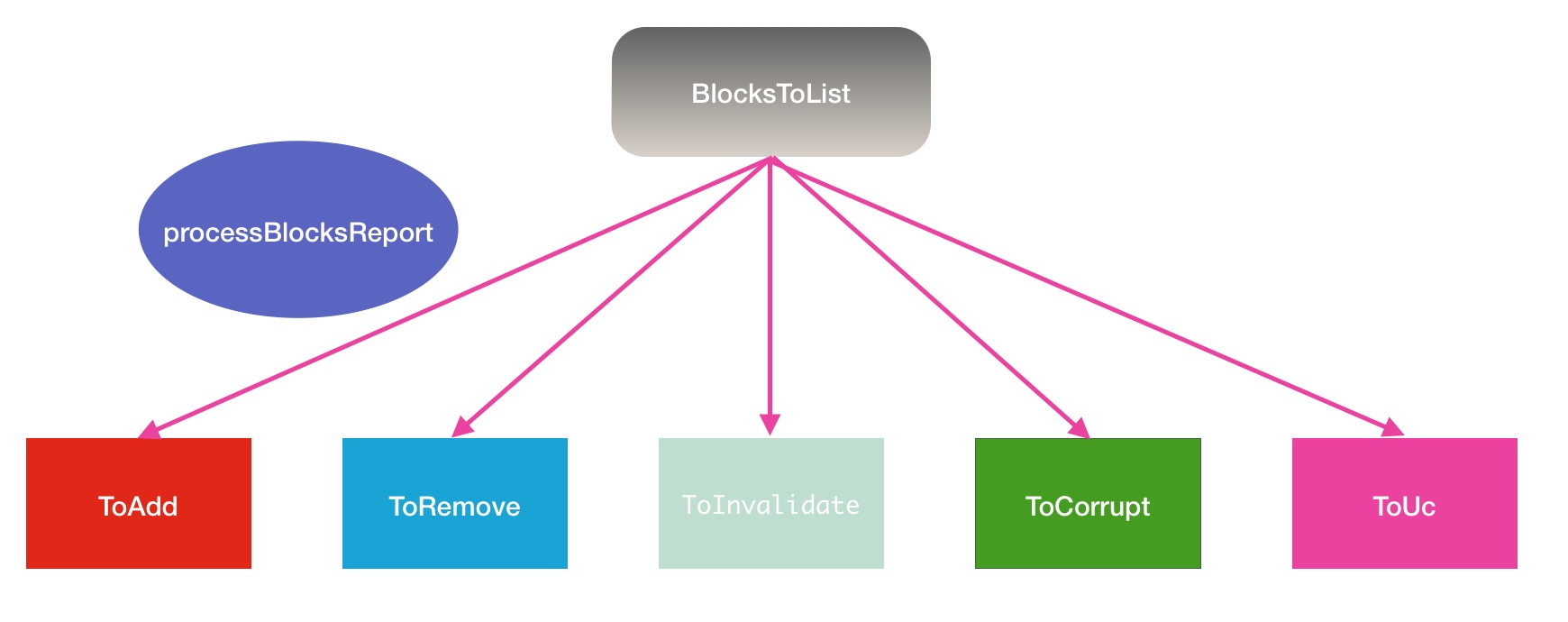
ToAdd: 新添加的块
新添加的块,指的是那些新的replicated的block块,而replicated的block块的特征是他的ReplicateState的状态是FINALIZED的.这些块是那些在过去的心跳时间间隔内,完成block块的写操作,并执行完finalized确认动作的block块.但是这里会有一个问题,datanode在上报replicatedBlock块的时候,是不区分新老block的,只要是存在于节点上并且完成的块,都上报.所以这部分的比较就自然的被移到了namenode这边处理,而比较的方法就是通过新旧的report报告.我们需要进入processReport接下来的内部处理逻辑中:
private Collection<Block> processReport(
final DatanodeStorageInfo storageInfo,
final BlockListAsLongs report) throws IOException {
// Normal case:
// Modify the (block-->datanode) map, according to the difference
// between the old and new block report.
//
Collection<BlockInfoContiguous> toAdd = new LinkedList<BlockInfoContiguous>();
Collection<Block> toRemove = new TreeSet<Block>();
Collection<Block> toInvalidate = new LinkedList<Block>();
Collection<BlockToMarkCorrupt> toCorrupt = new LinkedList<BlockToMarkCorrupt>();
Collection<StatefulBlockInfo> toUC = new LinkedList<StatefulBlockInfo>();
reportDiff(storageInfo, report,
toAdd, toRemove, toInvalidate, toCorrupt, toUC);
... private void reportDiff(DatanodeStorageInfo storageInfo,
BlockListAsLongs newReport,
Collection<BlockInfoContiguous> toAdd, // add to DatanodeDescriptor
Collection<Block> toRemove, // remove from DatanodeDescriptor
Collection<Block> toInvalidate, // should be removed from DN
Collection<BlockToMarkCorrupt> toCorrupt, // add to corrupt replicas list
Collection<StatefulBlockInfo> toUC) { // add to under-construction list
...
// scan the report and process newly reported blocks
for (BlockReportReplica iblk : newReport) {
ReplicaState iState = iblk.getState();
BlockInfoContiguous storedBlock = processReportedBlock(storageInfo,
iblk, iState, toAdd, toInvalidate, toCorrupt, toUC);
// move block to the head of the list
if (storedBlock != null &&
(curIndex = storedBlock.findStorageInfo(storageInfo)) >= 0) {
headIndex = storageInfo.moveBlockToHead(storedBlock, curIndex, headIndex);
}
}
...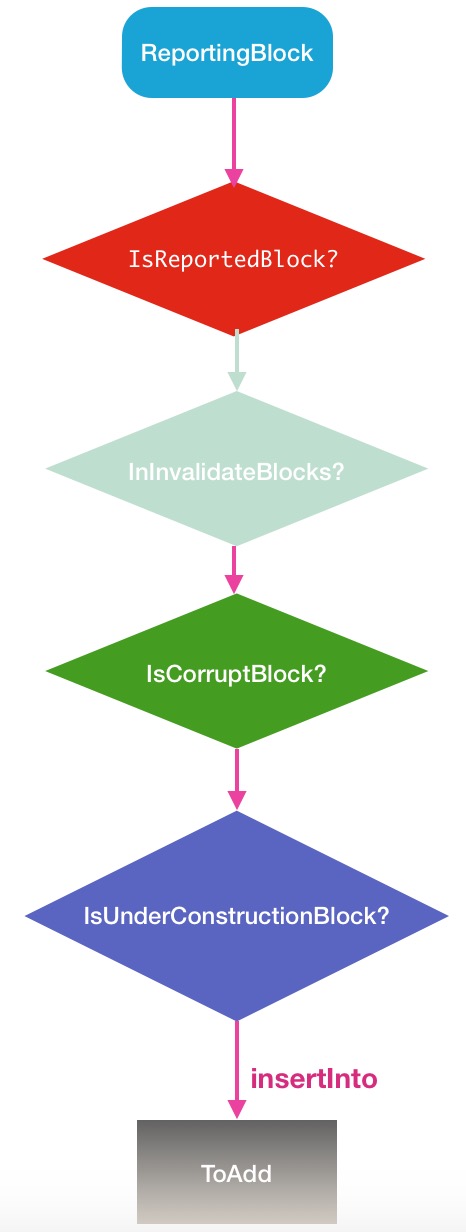
最后会到达添加toAdd块的逻辑,如果在上述图中的某个判断框中满足条件了,将会提前return,使之无法成为新的block块.绝大多数块会在第一个分支中被处理并进行return操作.
if (shouldPostponeBlocksFromFuture &&
namesystem.isGenStampInFuture(block)) {
queueReportedBlock(storageInfo, block, reportedState,
QUEUE_REASON_FUTURE_GENSTAMP);
return null;
}private Collection<Block> processReport(
final DatanodeStorageInfo storageInfo,
final BlockListAsLongs report) throws IOException {
// Normal case:
// Modify the (block-->datanode) map, according to the difference
// between the old and new block report.
//
Collection<BlockInfoContiguous> toAdd = new LinkedList<BlockInfoContiguous>();
Collection<Block> toRemove = new TreeSet<Block>();
Collection<Block> toInvalidate = new LinkedList<Block>();
Collection<BlockToMarkCorrupt> toCorrupt = new LinkedList<BlockToMarkCorrupt>();
Collection<StatefulBlockInfo> toUC = new LinkedList<StatefulBlockInfo>();
reportDiff(storageInfo, report,
toAdd, toRemove, toInvalidate, toCorrupt, toUC);
...
for (BlockInfoContiguous b : toAdd) {
addStoredBlock(b, storageInfo, null, numBlocksLogged < maxNumBlocksToLog);
numBlocksLogged++;
}
...
}/**
* Modify (block-->datanode) map. Remove block from set of
* needed replications if this takes care of the problem.
* @return the block that is stored in blockMap.
*/
private Block addStoredBlock(final BlockInfoContiguous block,
DatanodeStorageInfo storageInfo,
DatanodeDescriptor delNodeHint,
boolean logEveryBlock)
throws IOException {
...
// handle underReplication/overReplication
short fileReplication = bc.getBlockReplication();
if (!isNeededReplication(storedBlock, fileReplication, numCurrentReplica)) {
neededReplications.remove(storedBlock, numCurrentReplica,
num.decommissionedReplicas(), fileReplication);
}
...toAdd方面的block块添加的逻辑就是上述所描述的,中间略过了一些操作细节,感兴趣的同学可自行阅读源码进行学习.
ToRemove: 待移除的块
在日常生活中,我们可能会觉得,移除的意思差不多就是删除的意思,但是在processReport的块处理方法中,二者并不等同,在移除和删除操作中之间还隔了1步操作.在namenode这边判断1个块是否是待移除的块的标准是他有没有在这一轮被上报上来,如果没有表明datanode已经把这个块删了.方法中的定义是这样的:
// collect blocks that have not been reported
// all of them are next to the delimiter// place a delimiter in the list which separates blocks
// that have been reported from those that have not而整个汇报上来的块和未汇上来的块的处理逻辑用下面一幅图形象的展现:
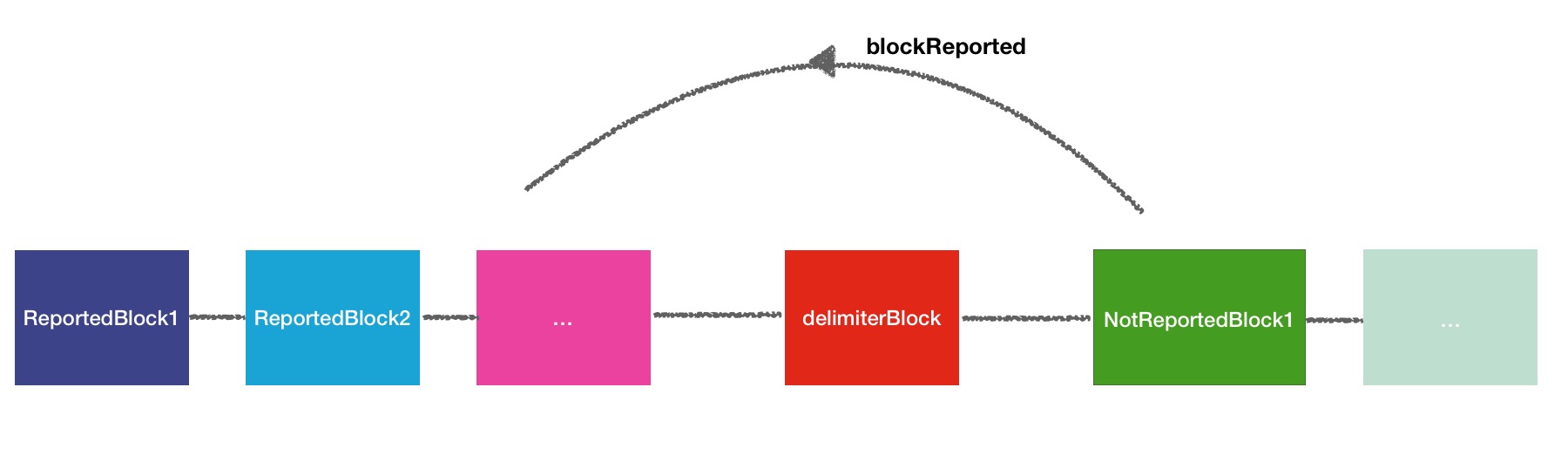
几句话简单概况一下这个过程:
1.首先会将分隔符block块插入到链表头部,这样所有的块默认是未汇报过的.
2.其次遍历block块,将汇报过的块移到链表头部,间隔地从分隔符的右侧挪到了左侧.
3.于是最后本轮没有汇报上来的块就全都在分隔符块的右侧了,应该说是next to delimeter.
代码如下,大家进行对照着看:
// place a delimiter in the list which separates blocks
// that have been reported from those that have not
BlockInfoContiguous delimiter = new BlockInfoContiguous(new Block(), (short) 1);
AddBlockResult result = storageInfo.addBlock(delimiter);
...
// scan the report and process newly reported blocks
for (BlockReportReplica iblk : newReport) {
...
// move block to the head of the list
if (storedBlock != null &&
(curIndex = storedBlock.findStorageInfo(storageInfo)) >= 0) {
headIndex = storageInfo.moveBlockToHead(storedBlock, curIndex, headIndex);
}
}
// collect blocks that have not been reported
// all of them are next to the delimiter
Iterator<BlockInfoContiguous> it =
storageInfo.new BlockIterator(delimiter.getNext(0));
while(it.hasNext())
toRemove.add(it.next());
storageInfo.removeBlock(delimiter);for (Block b : toRemove) {
removeStoredBlock(b, node);
}/**
* Modify (block-->datanode) map. Possibly generate replication tasks, if the
* removed block is still valid.
*/
public void removeStoredBlock(Block block, DatanodeDescriptor node) {
blockLog.debug("BLOCK* removeStoredBlock: {} from {}", block, node);
...
if (!blocksMap.removeNode(block, node)) {
blockLog.debug("BLOCK* removeStoredBlock: {} has already been" +
" removed from node {}", block, node);
return;
}
...ToInvalidate: 无效的块
在HDFS中,我觉得无效的块在某种程度上来说是更接近于待删除的块的意思.在processReportedBlock的方法中,toInvalidate无效块最根本的来源是源自blocksMap中不存在的块.
// find block by blockId
BlockInfoContiguous storedBlock = blocksMap.getStoredBlock(block);
if(storedBlock == null) {
// If blocksMap does not contain reported block id,
// the replica should be removed from the data-node.
toInvalidate.add(new Block(block));
return null;
}1.第一种,就是刚刚toRemove中块信息,使得blocksMap移除了对应的块信息.
2.第二种,新汇报上来的块信息,datanode自身有这些块信息,而namenode自身的blocksMap中没有,也会被认为是无效块.
第一种场景好理解,原本就是准备删除的块,就应该移到无效块中.但是这里要特别注意第二种场景,这个场景我们经历过一次,这个场景挺奇怪的,什么情况下datanode有block信息,而namenode又没有呢,答案是namenode用比较早些时间的fsimage做启动操作.因为时间早,fsimage当然不会有后面的元数据信息.所以这个时候如果启动了datanode,简直就是灾难.你会看到大量的块被移到toInvalidate.那我们什么时候会无意间用了早期fsimage启动namenode呢,比如下面这个条件:
1.namenode是ha模式的.
2.某台namenode1进程1个月前挂了,此时另外1台namenode2切换到了active状态继续提供服务,但是集群维护者并不知道.
3.1个月后namenode2需要更改配置或别的原因需要重启集群,因为集群维护者并不知道另外1个namenode1已经挂了1个多月了,意外的先启动了namenode1,而namenode1的fsimage已经落后一个多月了.
4.此时再次重启所有的datanode,就会发生上述的场景.
所以这里给集群的运维人员一个建议,对于关键进程需要进行报警监控,其次每次启动集群时要特别留意一下是否出现异常现象,如大量的无效块,大量的删除操作等.在任何情况下,数据的安全性永远是最重要的.下面是简化的流程图场景展示:

切回到刚刚的话题,加入到toInvalidate块后,toInvalidate中的块会被加入到invalidateBlocks中:
for (Block b : toInvalidate) {
addToInvalidates(b, node);
}/**
* Adds block to list of blocks which will be invalidated on specified
* datanode and log the operation
*/
void addToInvalidates(final Block block, final DatanodeInfo datanode) {
if (!namesystem.isPopulatingReplQueues()) {
return;
}
invalidateBlocks.add(block, datanode, true);
}之后就会触发到删除操作了.这部分的操作将会在ReplicationMonitor监控线程中被调用:
/**
* Periodically calls computeReplicationWork().
*/
private class ReplicationMonitor implements Runnable {
@Override
public void run() {
while (namesystem.isRunning()) {
try {
// Process replication work only when active NN is out of safe mode.
if (namesystem.isPopulatingReplQueues()) {
computeDatanodeWork();
processPendingReplications();
rescanPostponedMisreplicatedBlocks();
}
Thread.sleep(replicationRecheckInterval);
.../**
* Compute block replication and block invalidation work that can be scheduled
* on data-nodes. The datanode will be informed of this work at the next
* heartbeat.
*
* @return number of blocks scheduled for replication or removal.
*/
int computeDatanodeWork() {int blockCnt = 0;
for (DatanodeInfo dnInfo : nodes) {
int blocks = invalidateWorkForOneNode(dnInfo);
if (blocks > 0) {
blockCnt += blocks;
if (--nodesToProcess == 0) {
break;
}
}
}在namenode页面中的pendingDeletionBlock计数其实就是invalidateBlocks的大小
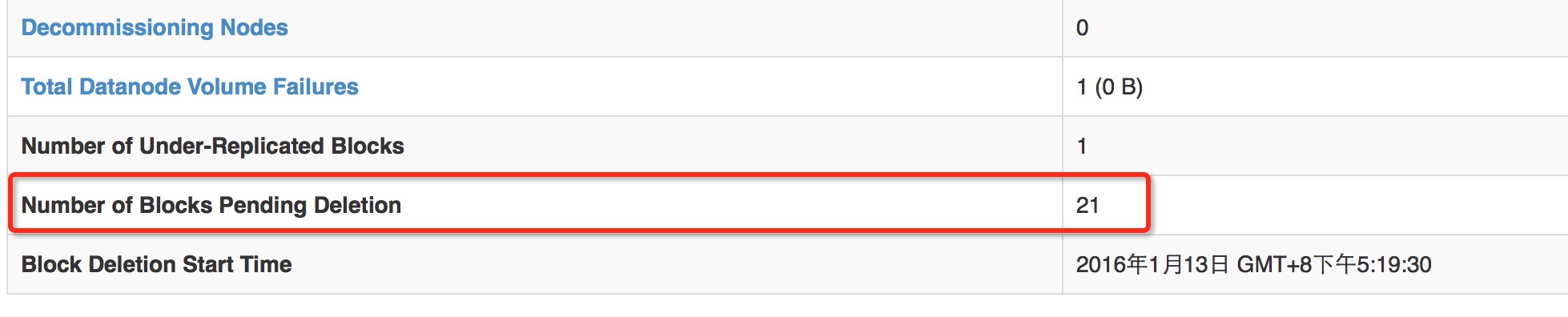
相关代码如下:
@Override
@Metric
public long getPendingDeletionBlocks() {
return blockManager.getPendingDeletionBlocksCount();
}/** Used by metrics */
public long getPendingDeletionBlocksCount() {
return invalidateBlocks.numBlocks();
}toInvalidate无效块还是非常重要的,知道这些无效块的缘由和去向对我们处理问题来说还是非常有帮助的.
ToCorrupt: 损坏的块
损坏的块一般发生于非系统内部的损坏操作导致,如人工的误删除.之后,就会在namenode的50070页面的上方区域显示出来,如下:
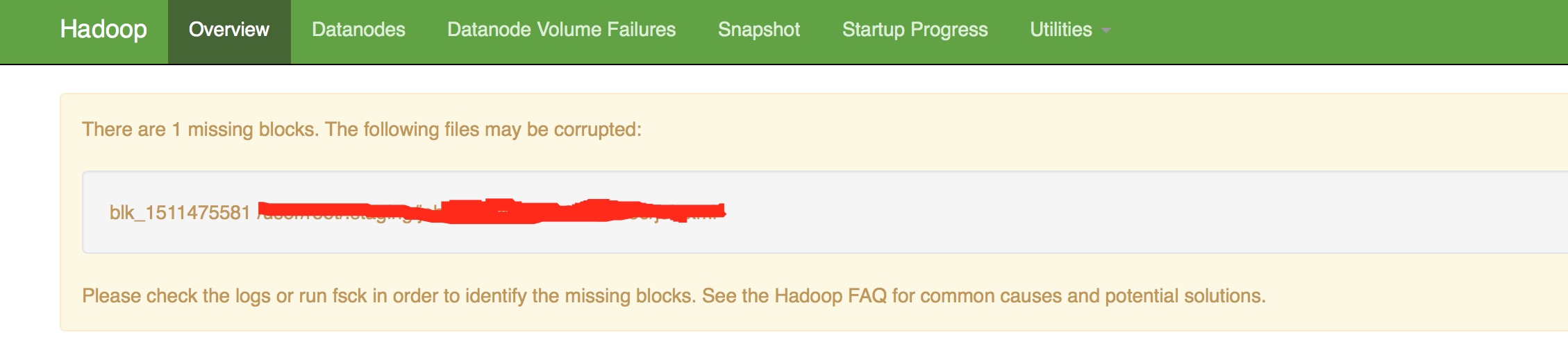
在processReportedBlock的处理逻辑中,对损坏块的判断逻辑主要在checkReplicaCorrupt
...
BlockToMarkCorrupt c = checkReplicaCorrupt(
block, reportedState, storedBlock, ucState, dn);
if (c != null) {
if (shouldPostponeBlocksFromFuture) {
// If the block is an out-of-date generation stamp or state,
// but we're the standby, we shouldn't treat it as corrupt,
// but instead just queue it for later processing.
// TODO: Pretty confident this should be s/storedBlock/block below,
// since we should be postponing the info of the reported block, not
// the stored block. See HDFS-6289 for more context.
queueReportedBlock(storageInfo, storedBlock, reportedState,
QUEUE_REASON_CORRUPT_STATE);
} else {
toCorrupt.add(c);
}
return storedBlock;
}
...private BlockToMarkCorrupt checkReplicaCorrupt(
Block reported, ReplicaState reportedState,
BlockInfoContiguous storedBlock, BlockUCState ucState,
DatanodeDescriptor dn) {
switch(reportedState) {
case FINALIZED:
switch(ucState) {
case COMPLETE:
case COMMITTED:
if (storedBlock.getGenerationStamp() != reported.getGenerationStamp()) {
final long reportedGS = reported.getGenerationStamp();
return new BlockToMarkCorrupt(storedBlock, reportedGS,
"block is " + ucState + " and reported genstamp " + reportedGS
+ " does not match genstamp in block map "
+ storedBlock.getGenerationStamp(), Reason.GENSTAMP_MISMATCH);
} else if (storedBlock.getNumBytes() != reported.getNumBytes()) {
return new BlockToMarkCorrupt(storedBlock,
"block is " + ucState + " and reported length " +
reported.getNumBytes() + " does not match " +
"length in block map " + storedBlock.getNumBytes(),
Reason.SIZE_MISMATCH);
} else {
return null; // not corrupt
}
... private void markBlockAsCorrupt(BlockToMarkCorrupt b,
DatanodeStorageInfo storageInfo,
DatanodeDescriptor node) throws IOException {
...
// Add this replica to corruptReplicas Map
corruptReplicas.addToCorruptReplicasMap(b.corrupted, node, b.reason,
b.reasonCode);
...这个对象中的某些方法信息,会在fsck命令中用到.仔细留意过namenode页面的corrupt信息的同学,肯定会发现,这个损坏块的信息每次打开信息都在,并不会消失,的确是这样的,除非你执行了fsck的-delete或-move操作,可以将损坏的块彻底删除掉了,元信息也将会删除掉.在namenode页面上所表示的损坏的块的个数就是corruptReplicas的大小.
/** Returns number of blocks with corrupt replicas */
@Metric({"CorruptBlocks", "Number of blocks with corrupt replicas"})
public long getCorruptReplicaBlocks() {
return blockManager.getCorruptReplicaBlocksCount();
}void updateState() {
...
corruptReplicaBlocksCount = corruptReplicas.size();
}ToUc: 正在处理中的块
Uc就是underConstruction,正在构建的意思,表明此block块正在写动作.判断是否是正在构建中的块的逻辑如下:
if (isBlockUnderConstruction(storedBlock, ucState, reportedState)) {
toUC.add(new StatefulBlockInfo(
(BlockInfoContiguousUnderConstruction) storedBlock,
new Block(block), reportedState));
return storedBlock;
}private boolean isBlockUnderConstruction(BlockInfoContiguous storedBlock,
BlockUCState ucState, ReplicaState reportedState) {
switch(reportedState) {
case FINALIZED:
switch(ucState) {
case UNDER_CONSTRUCTION:
case UNDER_RECOVERY:
return true;
default:
return false;
}
case RBW:
case RWR:
return (!storedBlock.isComplete());
case RUR: // should not be reported
case TEMPORARY: // should not be reported
default:
return false;
}
}// Process the blocks on each queue
for (StatefulBlockInfo b : toUC) {
addStoredBlockUnderConstruction(b, storageInfo);
}void addStoredBlockUnderConstruction(StatefulBlockInfo ucBlock,
DatanodeStorageInfo storageInfo) throws IOException {
BlockInfoContiguousUnderConstruction block = ucBlock.storedBlock;
block.addReplicaIfNotPresent(
storageInfo, ucBlock.reportedBlock, ucBlock.reportedState);
...void addReplicaIfNotPresent(DatanodeStorageInfo storage,
Block block,
ReplicaState rState) {
Iterator<ReplicaUnderConstruction> it = replicas.iterator();
...
replicas.add(new ReplicaUnderConstruction(block, storage, rState));
}/**
* Block replicas as assigned when the block was allocated.
* This defines the pipeline order.
*/
private List<ReplicaUnderConstruction> replicas;toUc的相关块处理比较简单,主要过程就是上面所描述的.
总结
以上就是本文所讲的上报block块处理5大分支,每个分支处理都尽量地把与其相关的操作也纳入进来了,本文在解读此方面的代码时,其实也略过了一些细节,如果读者想要了解更加详细的过程,请阅读BlockManager中的processReport以及内部的reportDiff方法.