语法树是句子结构的图形表示,它代表了句子的推导结果,有利于理解句子语法结构的层次。简单说,语法树就是按照某一规则进行推导时所形成的树。
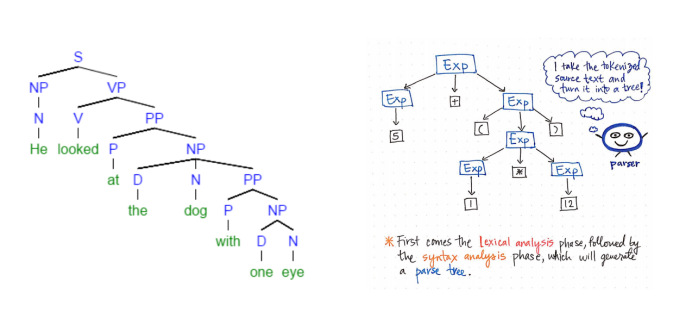
有了语法树,我们就可以根据其规则自动生成语句,但是语法树本身是死的,在日常生活中我们会有很多并不符合语法树的情况,比如:

我们转换一种思想,我不在意一句话对与不对,而是判断这句话出现概率的高低,如果一句话出现的最终概率越接近1,那么说明它越容易出现,反之亦然。这里我们就需要语言模型:N-gram,该模型基于这样一种假设,第N个词的出现只与前面N-1个词相关,而与其它任何词都不相关,整句的概率就是各个词出现概率的乘积。

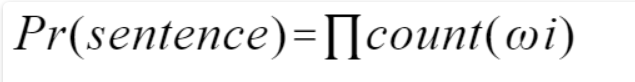
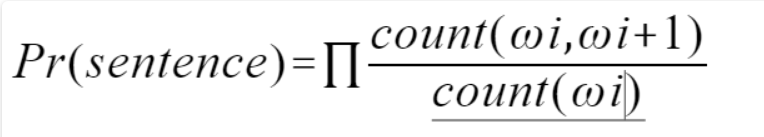
我们可以看出其实1-gram模型就是个词汇单独出现的概率累乘,与我们的初衷不符合,相反N值越大,其实模型应该越好,不过由于计算量的缘故,实际中我们常用的是2-gram(Bi-Gram)与3-gram(Tri-Gram),当N>=4时,实在是太慢了。
2-gram:需要统计句子中词汇与前一词汇同时出现的次数,最后累乘
3-gram:需要统计句子中词汇与前两词汇同时出现的次数,最后累乘
1 BaseDir = os.path.dirname(os.path.dirname(os.path.abspath(__file__))) 2 3 file_path = f"{BaseDir}/day1/data/article_9k.txt" 4 with open(file_path, 'r', encoding='utf-8') as f: 5 FILE = f.read() 6 7 8 def cut(string): 9 return list(jieba.cut(string)) 10 11 12 TOKENS = cut(FILE[:1000000]) 13 words_count = Counter(TOKENS) 14 _2_gram_words = [ 15 TOKENS[i] + TOKENS[i+1] for i in range(len(TOKENS)-1) 16 ] 17 _2_gram_word_counts = Counter(_2_gram_words) 18 19 20 def get_gram_count(word, wc): 21 """ 22 获取字符串在总字符表中的次数 23 :param word: 需要查询的字符串 24 :param wc: 总字符表 25 :return: 该字符串出现的次数,如没有则定为出现最少次数字符串的次数 26 """ 27 return wc[word] if word in wc else wc.most_common()[-1][-1] 28 29 30 def two_gram_model(sentence): 31 """ 32 分别计算句子中该单词在总字符表中出现的次数 33 该单词跟后一单词在二连总字符表中出现的次数 34 做比后的连续乘积 35 :param sentence: 需要验证的句子 36 :return: 37 """ 38 tokens = cut(sentence) 39 40 probability = 1 41 42 for i in range(len(tokens)-1): 43 word = tokens[i] 44 next_word = tokens[i+1] 45 46 _two_gram_c = get_gram_count(word + next_word, _2_gram_word_counts) 47 _one_gram_c = get_gram_count(next_word, words_count) 48 pro = _two_gram_c / _one_gram_c 49 50 probability *= pro 51 52 return probability 53 54 55 r = two_gram_model("这个花特别好看") 56 print(r) 57 r = two_gram_model("花这个特别好看") 58 print(r) 59 r = two_gram_model("自然语言处理") 60 print(r) 61 r = two_gram_model("处语言理自然") 62 print(r) 63 r = two_gram_model("前天早上") 64 print(r)
1 1.7475796022508822e-05 2 9.342406678699686e-07 3 0.030927835051546393 4 0.00018491124260355032 5 0.02857142857142857
从得出的结果我们就可以判断出这个句子出现的概率是多少了,当然N-gram模型的结果是受原始词袋影响的。