mysql
-- 20201201至今每日订单量top10的城市及其订单量(订单量对order_id去重)
select from_unixtime(ctime,"%Y-%m-%d") 日期,city_id,order_id,sum(sale_num) as 每日订单量
from t_order
where ctime>unix_timestamp('20201201')
group by from_unixtime(ctime,"%Y-%m-%d"),city_id,order_id
order by sum(sale_num) desc;
hql
-
行列转换
- 多行转一行
select id , concat_ws(',',collect_set(col_name)) as col_new from table_name group by id ;- 一行转多行
select id , col_name , split_col_name from table_name lateral view explode(split(col_name,',')) num as split_col_name -- group by 是为了去重,可以不要 group by id, col_name, split_col_name ; -
一个文件只有一行,但是这行有100G大小,mr会不会切分,我们应该怎么解决
public class TextInputFormat extends FileInputFormat<LongWritable, Text> {
@Override
public RecordReader<LongWritable, Text>
createRecordReader(InputSplit split,
TaskAttemptContext context) {
String delimiter = context.getConfiguration().get(
"textinputformat.record.delimiter");
byte[] recordDelimiterBytes = null;
if (null != delimiter)
recordDelimiterBytes = delimiter.getBytes(Charsets.UTF_8);
return new LineRecordReader(recordDelimiterBytes);
}
//这个对文件做压缩用的
@Override
protected boolean isSplitable(JobContext context, Path file) {
final CompressionCodec codec =
new CompressionCodecFactory(context.getConfiguration()).getCodec(file);
if (null == codec) {
return true;
}
return codec instanceof SplittableCompressionCodec;
}
}
//TextInputFormat类是继承自FileInputFormat ,FileInputFormat 实现了 InputFormat接口
//TextInputFormat中可以看到,在getRecordReader函数中调用了LineRecordReader这个类。我们注意观察在传入的参数中有一个delimiter参数,这个参数就是用来指定分割符的(具体可以查看LineRecordReader中实现对文件分割的实现),所以我们可以自己定义一个类MyInputFormat继承FileInputFormat类然后将
String delimiter = context.getConfiguration().get(
"textinputformat.record.delimiter");
//改为:String delimiter = "|-|
";
//然后在程序中,在Job中设置InputFormat类为MyInputFormat.class即可。
job.setInputFormatClass(MyInputFormat.class);
//如果不选择重写InputFormat类,也是可以实现的,给参数Configuaration对象设置属性textinputformat.record.delimiter
//以下是伪代码示例
private int run(long cols, String data_length, String primarykey_order_id, Configuration conf)
throws IOException, ClassNotFoundException, InterruptedException, SQLException
{
conf.set("colnumSize", String.valueOf(cols));
conf.set("textinputformat.record.delimiter", "|-|
");
Job job = new Job(conf, JobUtil.getJobName(dataTime, interfaceCode));
job.setJarByClass(RunTxt.class);
job.setMapperClass(Mapper_RunTxt.class);
// job.setInputFormatClass(MyTextFormat.class);
}
这样程序读取文本时不再以原来默认的" "逐行读取了,而是以用户自定义的行分割符来作为“行”(可能是一行或者多行)读取文件内容了。
- hdfs HA机制,一台namenode宕机了,joualnode,namenode,edit.log fsimage的变化
-
jounalnode
HA是为了解决单点问题,通过JN集群共享状态,通过ZKFC 选举active,监控状态,自动备援。
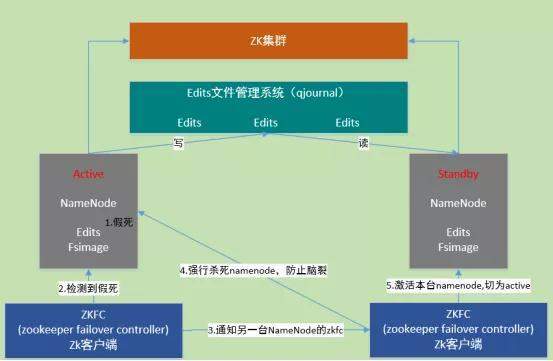
Active Namenode将数据写入共享文件管理系统,而StandbyNamenode监听该系统,一旦发现有新数据写入,则读取这些数据,并加载到自己内存中,以保证自己内存状态与Active NameNode保持基本一致。如此,在紧急情况下standby便可快速切为active namenode。- 自动故障转移机制:
-
active Namenode宕机(假死)。
-
active Namenode zkfc检测到假死
-
通知另一台namenode的zkfc
-
另一台机机器强行杀死之前的active namenode
-
激活standby namenode,切为active状态
-
- 自动故障转移机制:
-
namenode,edit,fsimage
-
Namenode滚动当前正在写的edit文件,该文件为待合并状态,也会生成新的edits.inprogress文件,后续的修改日志将写入该文件中
-
namenode将fsimage文件和edits文件加载到内存进行合并。dump成新的fsimage文件fsimage.chkpoint。
-
namenode将fsimage.chkpoint重命名为fsimage
- 如何判断一个模型的好坏
- 算法模型
我们会用不同的度量去评估我们的模型,而度量的选择,完全取决于模型的类型和模型以后要做的事;一般基于方差,基尼系数等可以对算法进行评估的数学模型。 - 数仓模型
- 模型完整度:des,ads,dm层直接饮用ods的比例太大就是跨层引用率过高就不是最优
- **复用率:dw,dws层产出的表的数量 **
- 规范度
- 数据可回滚,重跑数据结果不变
- 核心模型和扩展模型分离
-
rowkey一般如何设计,你项目中是如何设计的:保证唯一,有序,简短64kb以下
核心数据比如userid和itemid+时间戳+随机hash -
你们需求的开发流程是什么样的

- 需求提出:产品或者客户提出,UI,前后端开发,测试评估业务意义,成本等。
- 需求PRD:产品根据需求列出需求的细节,流程歧义等定义边界。并配有原型图,文字说明,主要是,需求,需求目标,业务逻辑,参与敲定版本的还是上述那些人。
- 交互设计:UI根据PRD设计出效果图,一般变动不大,如果大说明需求PRD没有设计好。
- 概要设计和详细设计:小需求改动可能直接详细设计或者确认-改动-发布完成即可。
- 技术是把双刃剑,你用了技术之后你是不是需要列出他的优点缺点,出问题之后的解决方案,还有可能出现的问题,注意点等等。
- 你需要考虑这个需求涉及到哪些服务了,需要新增哪些接口(功能列表),修改哪些接口,表有现场的还是要新建表,字段要新建么?
-
两个数 a=3,b=5,如何不使用中间变量不使用函数的情况下调换他们: ^按位异或,不相同二进制位异或的1
a=a^b b=a^b a=a^b
或者
a=a+b b=a-b a=a-b -
hive常用的优化:
- 行列过滤,代码优化
- 列处理:在SELECT中,只拿需要的列,如果有,尽量使用分区过滤,少用SELECT *
- 行处理:在分区剪裁中,当使用外关联时,如果将副表的过滤条件写在Where后面,那么就会先全表关联,之后再过滤,这样效率低,可以直接先子查询后再关联。(这个非常有用,实际开发中大数据处理效率会高很多,善用子查询关联);但是这种对左外关联和右外关联有时候就不一定适用了。尤其表中有null值的时候就不适合使用了,使用时要注意。
- 开启JVM重用
- CombineHiveInputFormat具有对小文件进行合并
- hive.exec.parallel值为true开启并行执行
- Fetch抓取: Fetch抓取是指,Hive中对某些情况的查询可以不必使用MapReduce计算;hive-default.xml.template文件中hive.fetch.task.conversion默认是more,该属性修改为more以后,在全局查找、字段查找、limit查找等都不走mapreduce。
-
hive的执行计划有看过吗,你一般会关注哪几个点:查看命令关键字Explain
EXPLAIN [EXTENDED|DEPENDENCY|AUTHORIZATION] query
- 执行计划一共有三个部分:
- 这个语句的抽象语法树
- 在语法树中的TOK_FROM中我们可以看到查询的这两张表及他们需要连接的条件
- 在TOK_INSERT中因为我们没有指定将查询信息写入哪张表,没有插入就为空
- 在TOK_SELECT中,显示了我们要查询的字段,逐个显示。
- 这个计划不同阶段之间的依赖关系:shuffle
可以stage十分明显的看出依赖关系。 - 对于每个阶段的详细描述
对每个stage都进行详细展示;-
TableScan 查看表 -
alias: emp 所需要的表 -
Statistics:Num rows: 2 这张表的基本信息 -
expressions:empno (type: int) 需要输出的字段及类型 -
outputColumnNames: _col0 输出字段编号 -
Filter Operator 过滤操作 -
Reduce Output Operator 输入到reduce阶段的操作及字段等信息 -
Join Operator join操作及类型信息 -
keys 连接字段 -
inputformat,outputfomat 输入输出格式
-
- 这个语句的抽象语法树
总的来说,Hive是通过给用户提供的一系列交互接口,接收到用户的指令(SQL),使用自己的Driver,结合元数据(MetaStore),将这些指令翻译成MapReduce,提交到Hadoop中执行,最后,将执行返回的结果输出到用户交互接口
驱动器里主要有:
(1)解析器(SQL Parser):将SQL字符串转换成抽象语法树AST,这一步一般都用第三方工具库完成,比如antlr;对AST进行语法分析,比如表是否存在、字段是否存在、SQL语义是否有误。
(2)编译器(Physical Plan):将AST编译生成逻辑执行计划。
(3)优化器(Query Optimizer):对逻辑执行计划进行优化。
(4)执行器(Execution):把逻辑执行计划转换成可以运行的物理计划。对于Hive来说,就是MR/Spark。
- 用phenix和es作为hbase二级索引的区别,最新的hbase已经支持二级索引了,你清楚吗?
es没有Phoenix并发高,速度快的。弄到solr/es主要目的是解决全文模糊查询.- Phoenix 社区好,用的比较多,sql话,索引分析支持没有ES灵活
- ES 模糊搜索等多种功能,需要自己定制开发链接两个框架
- Hbase的二级索引只是基于Coprocessor方案,目前市场使用的少。
JAVA
spring
- spring AOP应用场景
-
AOP(Aspect-OrientedProgramming,面向方面编程),可以说是OOP(Object-Oriented Programing,面向对象编程)的补充和完善。OOP引入封装、继承和多态性等概念来建立一种对象层次结构,用以模拟公共行为的一个集合。当我们需要为分散的对象引入公共行为的时候,OOP则显得无能为力。也就是说,OOP允许你定义从上到下的关系,但并不适合定义从左到右的关系。例如日志功能。日志代码往往水平地散布在所有对象层次中,而与它所散布到的对象的核心功能毫无关系。对于其他类型的代码,如安全性、异常处理和透明的持续性也是如此。这种散布在各处的无关的代码被称为横切(cross-cutting)代码,在OOP设计中,它导致了大量代码的重复,而不利于各个模块的重用。
而AOP技术则恰恰相反,它利用一种称为“横切”的技术,剖解开封装的对象内部,并将那些影响了多个类的公共行为封装到一个可重用模块,并将其名为“Aspect”,即方面。 -
AOP用来封装横切关注点,具体可以在下面的场景中使用:
-
Authentication 权限 -
Caching 缓存 -
Context passing 内容传递 -
Error handling 错误处理 -
Lazy loading 懒加载 -
Debugging 调试 -
logging, tracing, profiling and monitoring 记录跟踪 优化 校准 -
Performance optimization 性能优化 -
Persistence 持久化 -
Resource pooling 资源池 -
Synchronization 同步 -
Transactions 事务
-
-
AOP相关概念
-
方面(Aspect):一个关注点的模块化,这个关注点实现可能另外横切多个对象。事务管理是J2EE应用中一个很好的横切关注点例子。方面用spring的 Advisor或拦截器实现。
-
连接点(Joinpoint): 程序执行过程中明确的点,如方法的调用或特定的异常被抛出。
-
通知(Advice): 在特定的连接点,AOP框架执行的动作。各种类型的通知包括“around”、“before”和“throws”通知。通知类型将在下面讨论。许多AOP框架包括Spring都是以拦截器做通知模型,维护一个“围绕”连接点的拦截器链。Spring中定义了四个advice: BeforeAdvice, AfterAdvice, ThrowAdvice和DynamicIntroductionAdvice
-
切入点(Pointcut): 指定一个通知将被引发的一系列连接点的集合。AOP框架必须允许开发者指定切入点:例如,使用正则表达式。 Spring定义了Pointcut接口,用来组合MethodMatcher和ClassFilter,可以通过名字很清楚的理解, MethodMatcher是用来检查目标类的方法是否可以被应用此通知,而ClassFilter是用来检查Pointcut是否应该应用到目标类上
-
引入(Introduction): 添加方法或字段到被通知的类。 Spring允许引入新的接口到任何被通知的对象。例如,你可以使用一个引入使任何对象实现 IsModified接口,来简化缓存。Spring中要使用Introduction, 可有通过DelegatingIntroductionInterceptor来实现通知,通过DefaultIntroductionAdvisor来配置Advice和代理类要实现的接口
-
目标对象(Target Object): 包含连接点的对象。也被称作被通知或被代理对象。POJO
-
AOP代理(AOP Proxy): AOP框架创建的对象,包含通知。 在Spring中,AOP代理可以是JDK动态代理或者CGLIB代理。
-
织入(Weaving): 组装方面来创建一个被通知对象。这可以在编译时完成(例如使用AspectJ编译器),也可以在运行时完成。Spring和其他纯Java AOP框架一样,在运行时完成织入。
-
- 分布式锁的几种实现方式?
-
背景
- 单机的情况下,如果有多个线程要同时访问某个共享资源的时候,我们可以采用线程间加锁的机制;
- 到了分布式系统的时代,这种线程之间的锁机制,就没作用了,系统可能会有多份并且部署在不同的机器上,这些资源已经不是在线程之间共享了,而是属于进程之间共享的资源。
-
分布式锁要满足哪些要求呢?
- 排他性:在同一时间只会有一个客户端能获取到锁,其它客户端无法同时获取
- 避免死锁:这把锁在一段有限的时间之后,一定会被释放(正常释放或异常释放)
- 高可用:获取或释放锁的机制必须高可用且性能佳
-
实现方式
- 基于数据库
- 悲观锁
- 乐观锁 - 基于redis
- SETNX
- expire
- delete
- 基于zk
- 基于数据库
-
缺点
一、数据库分布式锁实现的缺点:1、db操作性能较差,并且有锁表的风险。 2、非阻塞操作失败后,需要轮询,占用cpu资源。 3、长时间不commit或者长时间轮询,可能会占用较多连接资源。 二、Redis(缓存)分布式锁实现的缺点: 1、锁删除失败,过期时间不好控制。 2、非阻塞,操作失败后,需要轮询,占用cpu资源。 三、ZK分布式锁实现的缺点: 性能不如redis实现,主要原因是写操作(获取锁释放锁)都需要在Leader上执行,然后同步到follower。
scala
- 二分查找
package top.majia.example
import scala.collection.mutable.ArrayBuffer
object Dichotomy {
def main(args: Array[String]): Unit = {
val list = Array(1, 3, 4, 2, 5, 5, 6, 9, 3, 4, 4)
search(list.sorted, 8)
}
def search(unSorted: Array[Int], find: Int): Unit = {
val size = unSorted.size
if (size == 0) {
println(s"empty array")
return
}
println(unSorted.toList)
var start = 0
var end = size - 1
while (start <= end) {
val index = (start + end) / 2
if (unSorted(index) > find) {
end = index - 1
} else if (unSorted(index) < find) {
start = index + 1
} else {
println(s"${find} in index : ${index}")
return
}
}
println(s"${find} no found")
}
}
- 怎么从一个字符串中把数字拆出来?
object FindNumFromStr {
def main(args: Array[String]): Unit = {
val xs = List("X45C", "5K")
val ys = xs map {x => """d+""".r.findAllIn(x).toList}
println(ys)
}
}