本文首发于我的公众号 Linux云计算网络(id: cloud_dev),专注于干货分享,号内有 10T 书籍和视频资源,后台回复「1024」即可领取,欢迎大家关注,二维码文末可以扫。
本文通过 IP 命令操作来简单介绍 network namespace 的基本概念和用法。深入了解可以看看我之前写的两篇文章 Docker 基础技术之 Linux namespace 详解 和 Docker 基础技术之 Linux namespace 源码分析。
和 network namespace 相关的操作的子命令是 ip netns 。
1. ip netns add xx 创建一个 namespace
# ip netns add net1
# ip netns ls
net1
2. ip netns exec xx yy 在新 namespace xx 中执行 yy 命令
# ip netns exec net1 ip addr
1: lo: <LOOPBACK> mtu 65536 qdisc noop state DOWN group default qlen 1
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
# ip netns exec net1 bash // 在 net1 中打开一个shell终端
# ip addr // 在net1中的shell终端
1: lo: <LOOPBACK> mtu 65536 qdisc noop state DOWN group default qlen 1
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
# exit // 退出net1
上面 bash 不好区分是当前是在哪个 shell,可以采用下面的方法解决:
# ip netns exec net1 /bin/bash --rcfile <(echo "PS1="namespace net1> "")
namespace net1> ping www.baidu.com
每个 namespace 在创建的时候会自动创建一个回环接口 lo ,默认不启用,可以通过 ip link set lo up 启用。
3. network namespace 之间的通信
新创建的 namespace 默认不能和主机网络,以及其他 namespace 通信。
可以使用 Linux 提供的 veth pair 来完成通信。下面显示两个 namespace 之间通信的网络拓扑:

3.1 ip link add type veth 创建 veth pair
# ip link add type veth
# ip link
3: veth0@veth1: <BROADCAST,MULTICAST,M-DOWN> mtu 1500 qdisc noop state DOWN mode DEFAULT group default qlen 1000
link/ether 1a:53:39:5a:26:12 brd ff:ff:ff:ff:ff:ff
4: veth1@veth0: <BROADCAST,MULTICAST,M-DOWN> mtu 1500 qdisc noop state DOWN mode DEFAULT group default qlen 1000
link/ether 46:df:46:1f:bf:d6 brd ff:ff:ff:ff:ff:ff
使用命令 ip link add xxx type veth peer name yyy 指定 veth pair 的名字。
3.2 ip link set xx netns yy 将 veth xx 加入到 namespace yy 中
# ip link set veth0 netns net0
# ip link set veth1 netns net1
#
# ip netns exec net0 ip addr
1: lo: <LOOPBACK> mtu 65536 qdisc noop state DOWN group default qlen 1
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
10: veth0@if11: <BROADCAST,MULTICAST> mtu 1500 qdisc noop state DOWN group default qlen 1000
link/ether 1a:53:39:5a:26:12 brd ff:ff:ff:ff:ff:ff link-netnsid 1
3.3 给 veth pair 配上 ip 地址
# ip netns exec net0 ip link set veth0 up
# ip netns exec net0 ip addr
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
inet6 ::1/128 scope host
valid_lft forever preferred_lft forever
10: veth0@if11: <NO-CARRIER,BROADCAST,MULTICAST,UP> mtu 1500 qdisc noqueue state LOWERLAYERDOWN group default qlen 1000
link/ether 1a:53:39:5a:26:12 brd ff:ff:ff:ff:ff:ff link-netnsid 1
# ip netns exec net0 ip addr add 10.1.1.1/24 dev veth0
# ip netns exec net0 ip route
10.1.1.0/24 dev veth0 proto kernel scope link src 10.1.1.1 linkdown
#
# ip netns exec net1 ip link set veth1 up
# ip netns exec net1 ip addr add 10.1.1.2/24 dev veth1
可以看到,在配完 ip 之后,还自动生成了对应的路由表信息。
3.4. ping 测试两个 namespace 的连通性
# ip netns exec net0 ping 10.1.1.2
PING 10.1.1.2 (10.1.1.2) 56(84) bytes of data.
64 bytes from 10.1.1.2: icmp_seq=1 ttl=64 time=0.069 ms
64 bytes from 10.1.1.2: icmp_seq=2 ttl=64 time=0.054 ms
64 bytes from 10.1.1.2: icmp_seq=3 ttl=64 time=0.053 ms
64 bytes from 10.1.1.2: icmp_seq=4 ttl=64 time=0.053 ms
Done!
4. 多个不同 namespace 之间的通信
2 个 namespace 之间通信可以借助 veth pair ,多个 namespace 之间的通信则可以使用 bridge 来转接,不然每两个 namespace 都去配 veth pair 将会是一件麻烦的事。下面就看看如何使用 bridge 来转接。
拓扑图如下:
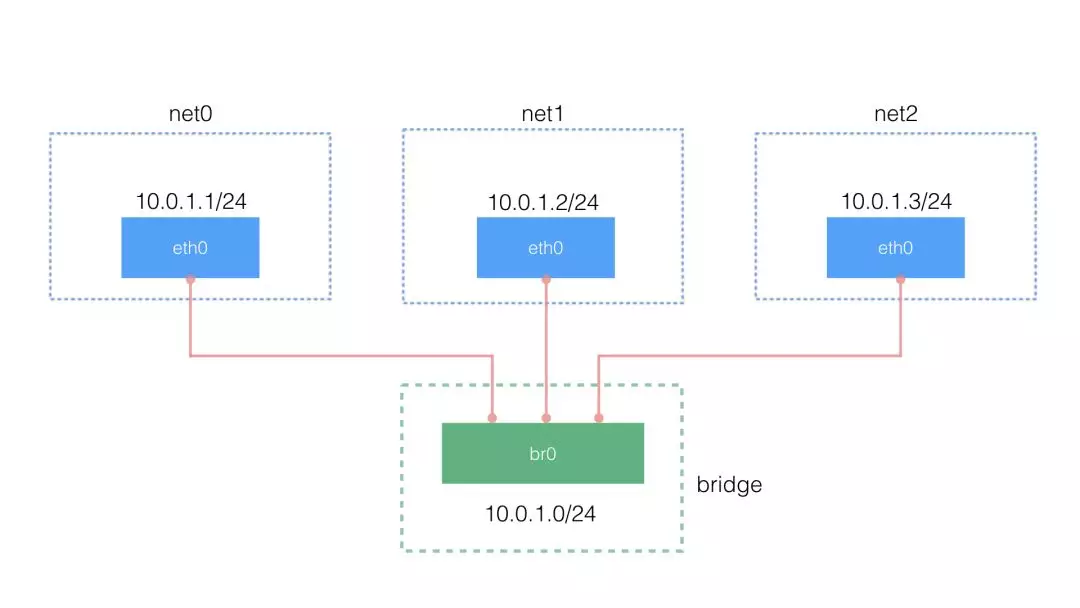
4.1 使用 ip link 和 brctl 创建 bridge
通常 Linux 中和 bridge 有关的操作是使用命令 brctl (yum install -y bridge-utils ) 。但为了前后照应,这里都用 ip 相关的命令来操作。
// 建立一个 bridge
# ip link add br0 type bridge
# ip link set dev br0 up
9: br0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UNKNOWN group default qlen 1000
link/ether 42:55:ed:eb:a0:07 brd ff:ff:ff:ff:ff:ff
inet6 fe80::4055:edff:feeb:a007/64 scope link
valid_lft forever preferred_lft forever
4.2 创建 veth pair
//(1)创建 3 个 veth pair
# ip link add type veth
# ip link add type veth
# ip link add type veth
4.3 将 veth pair 的一头挂到 namespace 中,一头挂到 bridge 上,并设 IP 地址
// (1)配置第 1 个 net0
# ip link set dev veth1 netns net0
# ip netns exec net0 ip link set dev veth1 name eth0
# ip netns exec net0 ip addr add 10.0.1.1/24 dev eth0
# ip netns exec net0 ip link set dev eth0 up
#
# ip link set dev veth0 master br0
# ip link set dev veth0 up
// (2)配置第 2 个 net1
# ip link set dev veth3 netns net1
# ip netns exec net1 ip link set dev veth3 name eth0
# ip netns exec net1 ip addr add 10.0.1.2/24 dev eth0
# ip netns exec net1 ip link set dev eth0 up
#
# ip link set dev veth2 master br0
# ip link set dev veth2 up
// (3)配置第 3 个 net2
# ip link set dev veth5 netns net2
# ip netns exec net2 ip link set dev veth5 name eth0
# ip netns exec net2 ip addr add 10.0.1.3/24 dev eth0
# ip netns exec net2 ip link set dev eth0 up
#
# ip link set dev veth4 master br0
# ip link set dev veth4 up
这样之后,竟然通不了,经查阅 参见 ,是因为
原因是因为系统为bridge开启了iptables功能,导致所有经过br0的数据包都要受iptables里面规则的限制,而docker为了安全性(我的系统安装了 docker),将iptables里面filter表的FORWARD链的默认策略设置成了drop,于是所有不符合docker规则的数据包都不会被forward,导致你这种情况ping不通。
解决办法有两个,二选一:
- 关闭系统bridge的iptables功能,这样数据包转发就不受iptables影响了:echo 0 > /proc/sys/net/bridge/bridge-nf-call-iptables
- 为br0添加一条iptables规则,让经过br0的包能被forward:iptables -A FORWARD -i br0 -j ACCEPT
第一种方法不确定会不会影响docker,建议用第二种方法。
我采用以下方法解决:
iptables -A FORWARD -i br0 -j ACCEPT
结果:
# ip netns exec net0 ping -c 2 10.0.1.2
PING 10.0.1.2 (10.0.1.2) 56(84) bytes of data.
64 bytes from 10.0.1.2: icmp_seq=1 ttl=64 time=0.071 ms
64 bytes from 10.0.1.2: icmp_seq=2 ttl=64 time=0.072 ms
--- 10.0.1.2 ping statistics ---
2 packets transmitted, 2 received, 0% packet loss, time 999ms
rtt min/avg/max/mdev = 0.071/0.071/0.072/0.008 ms
# ip netns exec net0 ping -c 2 10.0.1.3
PING 10.0.1.3 (10.0.1.3) 56(84) bytes of data.
64 bytes from 10.0.1.3: icmp_seq=1 ttl=64 time=0.071 ms
64 bytes from 10.0.1.3: icmp_seq=2 ttl=64 time=0.087 ms
--- 10.0.1.3 ping statistics ---
2 packets transmitted, 2 received, 0% packet loss, time 1000ms
rtt min/avg/max/mdev = 0.071/0.079/0.087/0.008 ms
Done!
我的公众号 「Linux云计算网络」(id: cloud_dev) ,号内有 10T 书籍和视频资源,后台回复 「1024」 即可领取,分享的内容包括但不限于 Linux、网络、云计算虚拟化、容器Docker、OpenStack、Kubernetes、工具、SDN、OVS、DPDK、Go、Python、C/C++编程技术等内容,欢迎大家关注。
