1、引入elasticsearch 需要的jar包
<!--elasticsearch-->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-elasticsearch</artifactId>
</dependency>
2、在application.properties中添加elasticsearch配置
spring.data.elasticsearch.cluster-name=xxx(你的elasticsearch的名称) spring.data.elasticsearch.cluster-nodes=xxxxx:9300,xxxxxxx:9300 spring.data.elasticsearch.repositories.enabled=true
3、创建实体类
/**
* indexName(索引名称):对应数据库名称
* type:表名称
*/
@Document(indexName="wx_log_index",type="accountinfo",shards=5,replicas=1,refreshInterval="-1")
public class Account {
@Id
private String id;
private String nickName;
private String accountName;
public String getId() {
return id;
}
public void setId(String id) {
this.id = id;
}
public String getNickName() {
return nickName;
}
public void setNickName(String nickName) {
this.nickName = nickName;
}
public String getAccountName() {
return accountName;
}
public void setAccountName(String accountName) {
this.accountName = accountName;
}
}
4、编写Reposity相当于数据库连接的dao层
@Component("elasticAccountInfoRepository")
public interface ElasticAccountInfoRepository extends ElasticsearchRepository<Account, String> {
}
5、编写Service和实现类
public interface ESAccountInfoService {
Account queryAccountInfoById(String id);
Account save(Account c);
}
@Service("esAccountInfoServiceImpl")
@Transactional
public class ESAccountInfoServiceImpl implements ESAccountInfoService {
@Autowired
private ElasticAccountInfoRepository elasticAccountInfoRepository;
@Override
public Account queryAccountInfoById(String id) {
return elasticAccountInfoRepository.queryAccountInfoById(id);
}
@Override
public Account save(Account c) {
return elasticAccountInfoRepository.save(c);
}
}
6、编写Controller
@RestController
@RequestMapping("/account")
public class ESController {
@Autowired
private ESAccountInfoService esAccountInfoServiceImpl;
@RequestMapping(value = "/add", method = RequestMethod.POST)
public void addUserToEs(@RequestBody @NonNull Account account) {
System.out.println("进入es添加方法");
esAccountInfoServiceImpl.save(account);
}
@RequestMapping(value = "/get", method = RequestMethod.GET)
public Account get(@RequestParam("id") String id) {
System.out.println("进入es查询方法");
Account acount = esAccountInfoServiceImpl.queryAccountInfoById(id);
System.out.println(acount.getAccountName());
return acount;
}
}
整个实现逻辑就是以上那么多步骤。此时还缺少一个客户端。
下载链接:https://github.com/ElasticHQ/elasticsearch-HQ
以下是安装客户端和连接客户端详细步骤,首先你的电脑要安装python
Download or clone the repository https://github.com/ElasticHQ/elasticsearch-HQ Navigate to the root of the repository: pip install -r requirements.txt Start the server: python3 application.py Point your browser to: http://localhost:5000
参考文档:http://www.cnblogs.com/eggTwo/p/4039779.html
以下是对elasticsearch 学习的一些总结:
一、Elasticsearch 文档更新和删除过程描述
-
删除和更新也都是写操作,但是Elasticsearch中的文档是不可变的,因此不能被删除或者改动以展示其变更;
-
磁盘上的每个段都有一个相应的.del文件。当删除请求发送后,文档并没有真的被删除,而是在.del文件中被标记为删除。该文档依然能匹配查询,但是会在结果中被过滤掉。当段合并时,在.del文件中被标记为删除的文档将不会被写入新段。
-
在新的文档被创建时,Elasticsearch会为该文档指定一个版本号,当执行更新时,旧版本的文档在.del文件中被标记为删除,新版本的文档被索引到一个新段。旧版本的文档依然能匹配查询,但是会在结果中被过滤掉。
二、在并发情况下,Elasticsearch如果保证读写一致?
-
可以通过版本号使用乐观并发控制,以确保新版本不会被旧版本覆盖,由应用层来处理具体的冲突;
-
另外对于写操作,一致性级别支持quorum/one/all,默认为quorum,即只有当大多数分片可用时才允许写操作。但即使大多数可用,也可能存在因为网络等原因导致写入副本失败,这样该副本被认为故障,分片将会在一个不同的节点上重建。
-
对于读操作,可以设置replication为sync(默认),这使得操作在主分片和副本分片都完成后才会返回;如果设置replication为async时,也可以通过设置搜索请求参数_preference为primary来查询主分片,确保文档是最新版本。
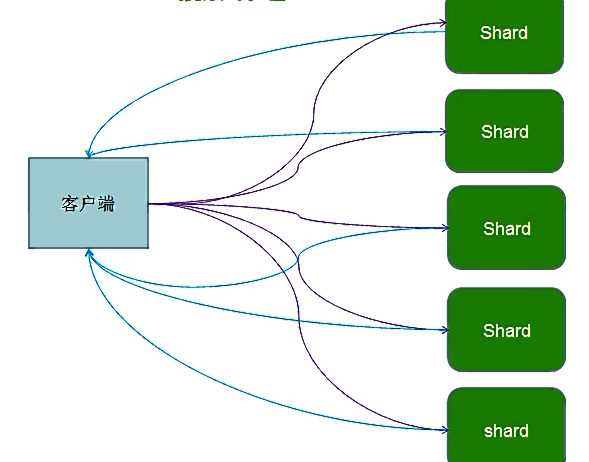
三、分布式搜索背景介绍:
ES 天生就是为分布式而生, 但分布式有分布式的缺点。 比如要搜索某个单词, 但是数据却分别在 5 个分片(Shard)上面, 这 5 个分片可能在 5 台主机上面。 因为全文搜索天生就要排序( 按照匹配度进行排名) ,但数据却在 5 个分片上, 如何得到最后正确的排序呢? ES是这样做的, 大概分两步:
step1、 ES 客户端将会同时向 5 个分片发起搜索请求。
step2、 这 5 个分片基于本分片的内容独立完成搜索, 然后将符合条件的结果全部返回。
客户端将返回的结果进行重新排序和排名,最后返回给用户。也就是说,ES的一次搜索,是一次scatter/gather过程(这个跟mapreduce也很类似)。
具体步骤如图所示:
四、Elasticsearch的搜索类型(SearchType类型)
1、 query and fetch
向索引的所有分片 ( shard)都发出查询请求, 各分片返回的时候把元素文档 ( document)和计算后的排名信息一起返回。
这种搜索方式是最快的。 因为相比下面的几种搜索方式, 这种查询方法只需要去 shard查询一次。 但是各个 shard 返回的结果的数量之和可能是用户要求的 size 的 n 倍。
优点:这种搜索方式是最快的。因为相比后面的几种es的搜索方式,这种查询方法只需要去shard查询一次。
缺点:返回的数据量不准确, 可能返回(N*分片数量)的数据并且数据排名也不准确,同时各个shard返回的结果的数量之和可能是用户要求的size的n倍。
2、 query then fetch( es 默认的搜索方式)
如果你搜索时, 没有指定搜索方式, 就是使用的这种搜索方式。 这种搜索方式, 大概分两个步骤:
第一步, 先向所有的 shard 发出请求, 各分片只返回文档 id(注意, 不包括文档 document)和排名相关的信息(也就是文档对应的分值), 然后按照各分片返回的文档的分数进行重新排序和排名, 取前 size 个文档。
第二步, 根据文档 id 去相关的 shard 取 document。 这种方式返回的 document 数量与用户要求的大小是相等的。
优点:
返回的数据量是准确的。
缺点:
性能一般,并且数据排名不准确。
3、 DFS query and fetch
这种方式比第一种方式多了一个 DFS 步骤,有这一步,可以更精确控制搜索打分和排名。也就是在进行查询之前, 先对所有分片发送请求, 把所有分片中的词频和文档频率等打分依据全部汇总到一块, 再执行后面的操作、
优点:
数据排名准确
缺点:
性能一般
返回的数据量不准确, 可能返回(N*分片数量)的数据
4、 DFS query then fetch
比第 2 种方式多了一个 DFS 步骤。
也就是在进行查询之前, 先对所有分片发送请求, 把所有分片中的词频和文档频率等打分依据全部汇总到一块, 再执行后面的操作、
优点:
返回的数据量是准确的
数据排名准确
缺点:
性能最差【 这个最差只是表示在这四种查询方式中性能最慢, 也不至于不能忍受,如果对查询性能要求不是非常高, 而对查询准确度要求比较高的时候可以考虑这个】
DFS 是一个什么样的过程?
从 es 的官方网站我们可以发现, DFS 其实就是在进行真正的查询之前, 先把各个分片的词频率和文档频率收集一下, 然后进行词搜索的时候, 各分片依据全局的词频率和文档频率进行搜索和排名。 显然如果使用 DFS_QUERY_THEN_FETCH 这种查询方式, 效率是最低的,因为一个搜索, 可能要请求 3 次分片。 但, 使用 DFS 方法, 搜索精度是最高的。
总结一下, 从性能考虑 QUERY_AND_FETCH 是最快的, DFS_QUERY_THEN_FETCH 是最慢的。从搜索的准确度来说, DFS 要比非 DFS 的准确度更高。