模型选择与交叉验证
需要选择合适的模型,能够正确的训练模型,并更好的拟合数据。如下的例子是房价面积和价格的线性回归模型,
更少的参数拟合效果不够好,更多的参数导致过拟合。

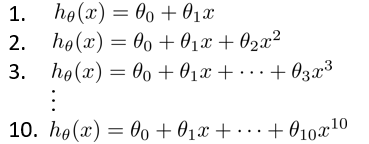
因此,在使用过程中,将数据集划分为:训练集、验证集、测试集。比例为:6:2:2。选择完以后,使用如下的第一个J函数作为训练依据,训练一批模型。
使用第二的J函数,代入验证集,判断要选择的模型,选择J值最小的模型。在得到模型维数d以后,使用该模型,代入测试集到该模型得到J函数值,得出模型模型误差(训练效果)。

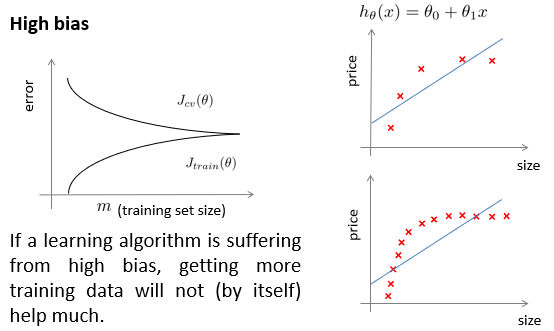
诊断偏差和方差
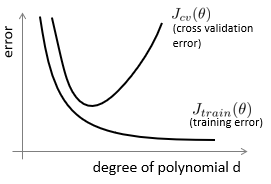
在下图所示的是训练误差Jtrain和验证误差Jcv,当模型的维数d过低,往往没有办法完全表达出数据集的信息,训练和验证集误差都大,为欠拟合状态,模型具有高偏差。
当模型维数过高,训练集过于表示了训练集的数据内容,将训练集的一些误差或者噪声等,也完全的学习到模型中,导致验证集的误差再次变高,为过拟合状态,模型具有高方差。
良好的模型应该是中间的,使得训练集和验证集都能有较低的误差。
正则化与偏差、方差
使用正则化方法可以缓解欠拟合(偏差)、过拟合(方差)的问题。方法和模型选择类似。
1 选择一批lambda值,使用第一个J在训练集上训练所有模型。
2 训练结束后,使用验证集和第三个Jcv,得出一批误差。选择误差Jcv最小的值对应的模型。
3 使用选择的模型,进行测试集验证吧。整个训练过程都是用的带正则化的J吧,原来的Jtrain可能被弃了。
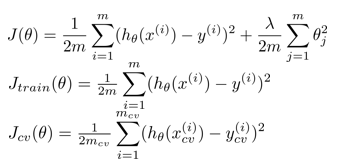
实验认为,lambda的取值较小,导致训练参数theta过大,当数据条目不够而训练参数过多,模型表达的能力“过强”,容易出现过拟合。
随着lambda增大到一定程度,因为J的梯度下降原因,theta的值过小,甚至为0,导致数据难以被模型表达,出现欠拟合。
所以选择合适的lambda呗
学习曲线
针对过拟合状态,当数据量过少的时候,模型只能根据已有的少量训练数据训练,过度表达,导致验证集上的数据分布无法完全和训练模型的数据分布符合。从下图的曲线,说,让更多的数据被训练和验证吧,在更远处的m位置上,训练了更多的数据,使得模型表达更完整,从而验证和测试效果更好。
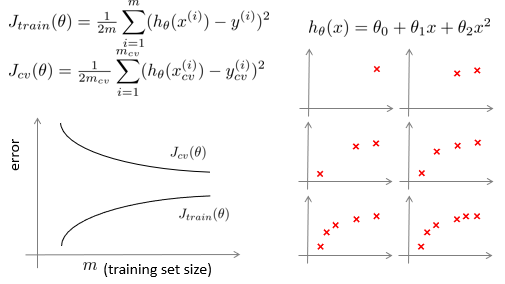
针对欠拟合状态,往往是模型无法完整表达数据,如下图右边表达式,其模型的能力不够而导致对数据集的误差,无论在训练集还是验证集都大,达到一致。因而,增加训练数据无法解决欠拟合(高偏差)的问题(从曲线也可以看出,再怎么增加数据量,也只能达到相交状态,不能使得误差下降),解决方式如,增加模型的维数d,使得模型表示能力更强。(另外,虽然减少数据量,也可以降低欠拟合,但是那样,使得训练数据减少,那么训练数据会损失真实的数据分布特征,对实际应用也是不利的吧)
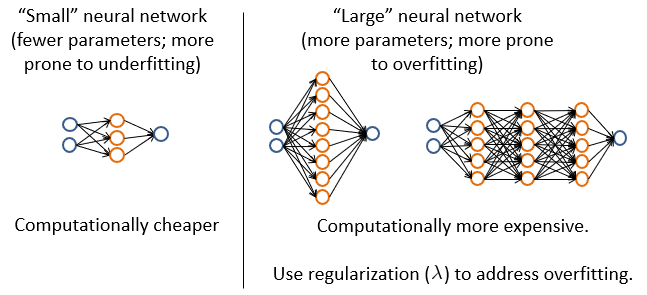
小结与下一步
如下六种,是当模型不适当的时候可以使用的方法。更多的训练样例,是解决过拟合。增加多项式特征,即修改模型的维数d,是解决欠拟合。
减少lambda,使得theta增高,增强模型对每条数据中的特征表达强度。增加额外的训练样本特征,传入训练模型。这两种方法解决欠拟合。
增加lambda,对应使得theta降低,theta降低则限制了每条数据的特征表示。更少的特征表示传入训练模型。这两种方法是解决过拟合。

另外的一些说明如下图,总之,合适的模型加上一点正则化调整,这样的模型可能更有效一点吧。
设计一套机器学习系统,首先要做的
如下的设计一套学习系统,用于区分垃圾邮件与非垃圾邮件。系统设计分为了四步:收集数据、邮件路由鉴别模块,邮件文本鉴别模块,误拼写模块。

误差分析
针对特定问题而设计机器学习算法时,首先快速设计一个简单的算法,采用交叉验证方法测试。
之后,绘制学习曲线分析该算法的问题,针对不同的过拟合、欠拟合问题进行优化。
然后,进行误差分析,提取出被错误分类的样本,总结分析该错误产生的原因,调整学习系统。
总之一个特点是,不是仅仅凭直觉调整机器学习系统,而是根据具体的系统结果分析到该结果导致的原因,对症下药。
另外,初始设计一套系统直接以一个复杂的系统开始,是不合适的,不利于分析,而且有些冗余和干扰因素。