1.基本概念
时序数据库(Time Series Database)是用于存储和管理时间序列数据的专业化数据库。时序数据库特别适用于物联网设备监控和互联网业务监控场景。
下面介绍下时序数据库的一些基本概念(不同的时序数据库称呼略有不同)。
1.1 度量(metric)
监测数据的指标,例如风力和温度。相当于关系型数据库中的table。
1.2 标签(tag)
指标项监测针对的具体对象,属于指定度量下的数据子类别。一个标签(Tag)由一个标签键(TagKey)和一个对应的标签值(TagValue)组成。
例如在监测数据的时候,指定度量(Metric)是“气温”,“城市(TagKey)= 杭州(TagValue)”就是一个标签(Tag),则监测的就是杭州市的气温。更多标签示例:机房 = A 、IP = 172.220.110.1。
1.3 域(field)
在指定度量下数据的子类别,一般情况下存放的是会随着时间戳的变化而变化的数据。一个metric可支持多个field,如metric为风力,该度量可以有两个field:direction和speed。
1.4 度量值(value)
度量对应的数值,如56°C、1000r/s等(实际中不带单位)。如果有多个field,每个field都有相应的value。不同的field支持不同的数据类型写入。对于同一个field,如果写入了某个数据类型的value之后,相同的field不允许写入其他数据类型。
1.5 时间戳(Timestamp)
数据(度量值)产生的时间点。
1.6 数据点 (Data Point)
针对监测对象的某项指标(由度量和标签定义)按特定时间间隔(连续的时间戳)采集的每个度量值就是一个数据点。1个metric+1个field(可选)+1个timestamp+1个value + n个tag(n>=1)”唯一定义了一个数据点。相当于关系型数据库中的row。
1.7 时间序列(Time Series)
1个metric+1个field(可选) +n个tag(n>=1)”定义了一个时间序列。主要是针对某个监测对象的某项指标(由度量和标签定义)的描述。某个时间序列上产生的数据值的增加,不会导致时间序列的增加。
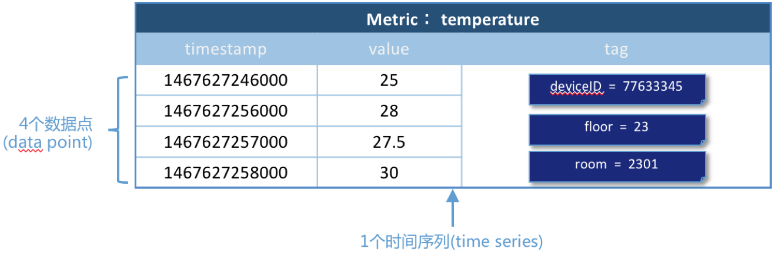
例1(单域):对温度的时间序列监测值
温度(temperature)作为一个度量(metric),共4个数据点,每个数据点由如下组成:
timestamp:时间戳
三个tag:每个tag都是一个key-value对,tag的key分别是deivceID、floor、room。
一个field:温度值
其中4个数据点使用的metric、tag是相同的,所以是同一个时间序列。如图所示:
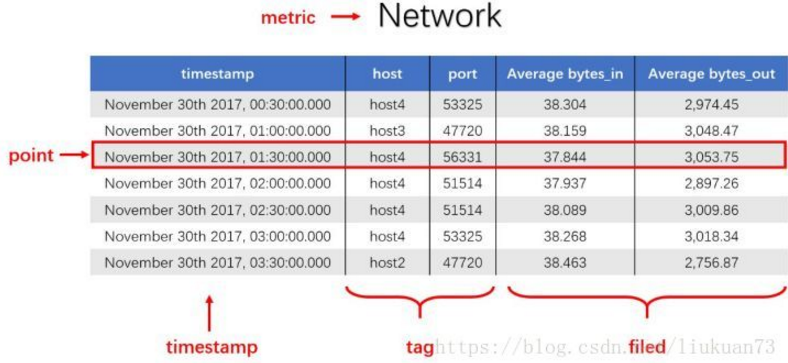
例2(多域,单一数据源采集):记录一段时间内的某个集群里各机器上各端口的出入流量,每半小时记录一个观测值。
网络(Network)作为一个度量(metric),总共7个数据点。每个数据点由以下部分组成:
timestamp:时间戳
两个tag:host、port,代表每个point归属于哪台机器的哪个端口
两个field:bytes_in、bytes_out,代表piont的测量值,半小时内出入流量的平均值
同一个host、同一个port,每半小时产生一个point,随着时间的增长,field(bytes_in、bytes_out)不断变化。
如host:host4,port:51514,timestamp从02:00 到02:30的时间段内,bytes_in 从 37.937上涨到38.089,bytes_out从2897.26上涨到3009.86,说明这一段时间内该端口服务压力升高。
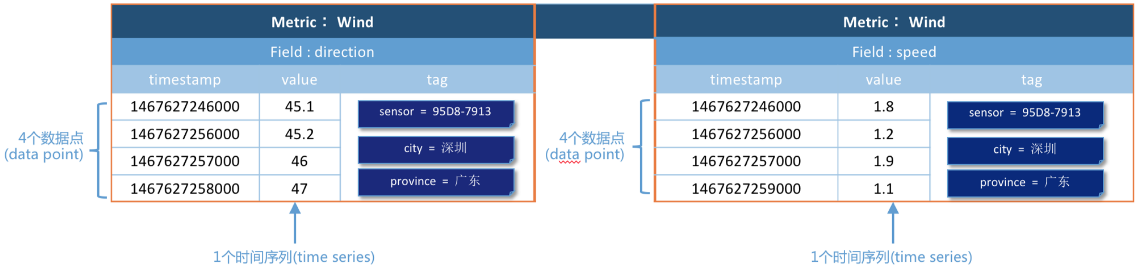
例3(多域,多个数据源采集):监测风力的两个域(speed和direction)的监测数据,监测数据来自不同的传感器
风力(wind)作为一个度量(metric),总共2个时间序列,8个数据点。每个数据点由以下部分组成:
3个tag:key分别是sensor、city、province。为了表示在广东省深圳市传感器编号95D8-7913上传风向(direction)数据,可以将这个数据点的tag为标记为sensor=95D8-7913、city=深圳、province=广东。
两个域:风向(direction)和速度(speed),分别来自不同的传感器。
如图,当使用的是metric、field和tag是相同的时,是同一个时间序列。
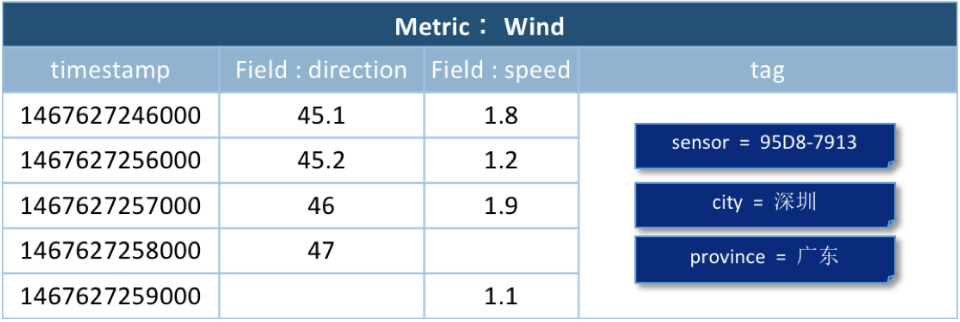
将数据采用metric+field的方式存储的优势在于,可以在同一个时间序列下联合查询。以上图为例,要查询1467627246000-1467627249000时间内风力(wind)的情况,可以联合查询多个field的值,得到下图的数据。
1.8 时间精度
时间线数据的写入时间精度——毫秒、秒、分钟、小时或者其他稳定时间频度。例如,每秒一个温度数据的采集频度,每 5 分钟一个负载数据的采集频度。
1.9-1 数据组(Data Group)
可以按标签这些数据分成不同的数据组。用来对比不同监测对象(由标签定义)的同一指标(由度量定义)的数据。
例如,将温度指标数据按照不同城市进行分组查询,操作类似于该 SQL 语句:select temperature from xxx group by city where city in (shanghai, hangzhou)。
1.9-2 聚合( Aggregation)
可以对一段时间的数据点做聚合,如每10分钟的和值、平均值、最大值、最小值等。
例如,当选定了某个城市某个城区的污染指数时,通常将各个环境监测点的指标数据平均值作为最终区域的指标数据,这个计算过程就是空间聚合。
2.应用场景
2.1系统运维和业务实时监控
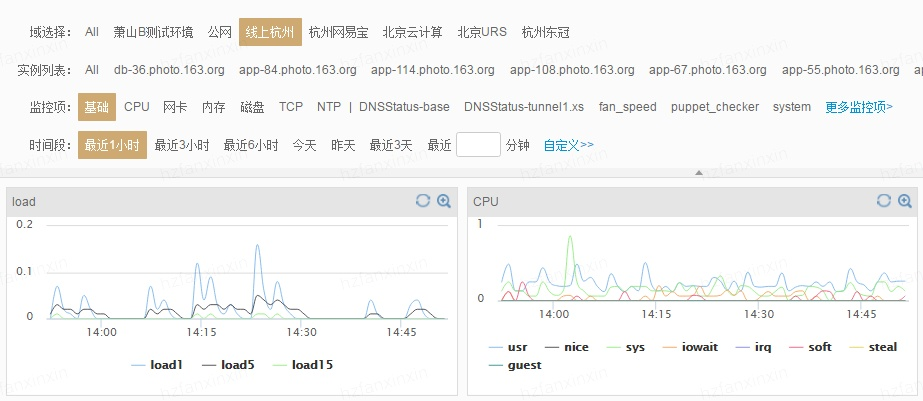
在业务服务器上部署各种脚本客户端,实时采集服务器指标数据(IO指标、CPU指标、带宽内存指标等等),业务相关数据(方法调用异常次数、响应延迟、JVM GC相关数据等等)、数据库相关数据(读取延迟、写入延迟等等),很显然,这些数据都是时间序列相关的。客户端采集和实时计算之后会发送给哨兵服务器,哨兵服务器会将这些数据进行存储,并实现实现监控和分析的展现,供用户查询。
如下图所示,用户可以登录哨兵系统查看某台服务器的负载,负载曲线就是按照时间进行绘制的,带有明显的时序特征:
2.2 物联网设备状态监控存储分析
在可预知的未来3~5年,随着物联网以及工业4.0的到来,所有设备都会携带传感器并联网,传感器收集的时序数据将严重依赖TSDB的实时分析能力、存储能力以及查询统计能力。

上图是一个智慧工厂示意图,工厂中所有设备都会携带传感设备,这些传感设备会实时采集设备温度、压力等基本信息,并发送给服务器端进行实时分析、存储以及后期的查询统计。除此之外,比如现在比较流行的各种穿戴设备,以后都可以联网,穿戴设备上采集的心跳信息、血流信息、体感信息等等也都会实时传输给服务器进行实时分析、存储以及查询统计。
PS:阿里云拥有自主研发的时序数据库产品 TSDB ,此产品在阿里内部磨练多年, 历经多次双十一高严苛场景的功能和性能验证, 在应用监控,服务器资源监控,数据库监控, 智慧园区设备监控,以及盒马新零售边缘设备监控都有丰富的落地使用场景 ,覆盖了阿里集团80%以上的时序监控业务。
3.基本特点
时序业务和普通业务在很多方面都有巨大的区别,归纳起来主要有如下几个方面:
3.1 持续产生海量数据,没有波峰波谷
举几个简单的例子,比如类似哨兵的监控系统,假如现在系统监控1w台服务器的各类指标,每台服务器每秒采集100种metrics,这样每秒钟将会有100w的TPS。再比如说,现在比较流行的运动手环,假如当前有100w人佩戴,每个手环一秒只采集3种metrcis(心跳、脉搏、步数),这样每秒钟也会产生300w的TPS。
3.2 数据都是插入操作,基本没有更新删除操作
时序业务产生的数据很少有更新删除的操作,基于这样的事实,在时序数据库架构设计上会有很大的简化。
3.3 近期数据关注度更高,未来会更关注流式处理这个环节,时间久远的数据极少被访问,甚至可以丢弃
这个很容易理解,哨兵系统我们通常最关心最近一小时的数据,最多看看最近3天的数据,很少去看3天以前的数据。随着流式计算的到来,时序数据在以后的发展中必然会更关注即时数据的价值,这部分数据的价值毫无疑问也是最大的。数据产生之后就可以根据某些规则进行报警是一个非常常见并重要的场景,报警时效性越高,对业务越有利。
3.4 数据存在多个维度的标签,往往需要多维度联合查询以及统计查询。
时序数据另一个非常重要的功能是多维度聚合统计查询,比如业务需要统计最近一小时广告主google发布在USA地区的广告点击率和总收入分别是多少,这是一个典型的多维度聚合统计查询需求。这个需求通常对实效性要求不高,但对查询聚合性能有比较高的要求。
4.TSDB核心特性
总结起来TSDB需要关注的技术点主要有这么几个:
4.1 高吞吐量写入能力
这是针对时序业务持续产生海量数据这么一个特点量身定做的,当前要实现系统高吞吐量写入,必须要满足两个基本技术点要求:系统具有水平扩展性和单机LSM体系结构。系统具有水平扩展性很容易理解,单机肯定是扛不住的,系统必须是集群式的,而且要容易加节点扩展,说到底,就是扩容的时候对业务无感知,目前Hadoop生态系统基本上都可以做到这一点;而LSM体系结构是用来保证单台机器的高吞吐量写入,LSM结构下数据写入只需要写入内存以及追加写入日志,这样就不再需要随机将数据写入磁盘,HBase、Kudu以及Druid等对写入性能有要求的系统目前都采用的这种结构。
4.2 数据分级存储/TTL
这是针对时序数据冷热性质定制的技术特性。数据分级存储要求能够将最近小时级别的数据放到内存中,将最近天级别的数据放到SSD,更久远的数据放到更加廉价的HDD或者直接使用TTL过期淘汰掉。
4.3 高压缩率
提供高压缩率有两个方面的考虑,一方面是节省成本,这很容易理解,将1T数据压缩到100G就可以减少900G的硬盘开销,这对业务来说是有很大的诱惑的。另一个方面是压缩后的数据可以更容易保证存储到内存中,比如最近3小时的数据是1T,我现在只有100G的内存,如果不压缩,就会有900G的数据被迫放到硬盘上,这样的话查询开销会非常之大,而使用压缩会将这1T数据都放入内存,查询性能会非常之好。
4.4 多维度查询能力
时序数据通常会有多个维度的标签来刻画一条数据,就是上文中提到的维度列。如何根据随机几个维度进行高效查询就是必须要解决的一个问题,这个问题通常需要考虑位图索引或者倒排索引技术。
4.5 高效聚合能力
时序业务一个通用的需求是聚合统计报表查询,比如哨兵系统中需要查看最近一天某个接口出现异常的总次数,或者某个接口执行的最大耗时时间。这样的聚合实际上就是简单的count以及max,问题是如何能高效的在那么大的数据量的基础上将满足条件的原始数据查询出来并聚合,要知道统计的原始值可能因为时间比较久远而不在内存中哈,因此这可能是一个非常耗时的操作。目前业界比较成熟的方案是使用预聚合,就是在数据写进来的时候就完成基本的聚合操作。
未来技术点:异常实时检测、未来预测等等。
5.传统关系型数据库存储时序数据的问题
很多人可能认为在传统关系型数据库上加上时间戳一列就能作为时序数据库。数据量少的时候确实也没问题。但时序数据往往是由百万级甚至千万级终端设备产生的,写入并发量比较高,属于海量数据场景。
5.1 MySQL在海量的时序数据场景下存在如下问题:
存储成本大:对于时序数据压缩不佳,需占用大量机器资源;
维护成本高:单机系统,需要在上层人工的分库分表,维护成本高;
写入吞吐低:单机写入吞吐低,很难满足时序数据千万级的写入压力;
查询性能差:适用于交易处理,海量数据的聚合分析性能差。
5.2 使用Hadoop生态(Hadoop、Spark等)存储时序数据会有以下问题:
数据延迟高:离线批处理系统,数据从产生到可分析,耗时数小时、甚至天级;
查询性能差:不能很好的利用索引,依赖MapReduce任务,查询耗时一般在分钟级。
5.3 时序数据库需要解决以下几个问题:
时序数据的写入:如何支持每秒钟上千万上亿数据点的写入。
时序数据的读取:如何支持在秒级对上亿数据的分组聚合运算。
成本敏感:由海量数据存储带来的是成本问题。如何更低成本的存储这些数据,将成为时序数据库需要解决的重中之重。
6.时序数据库发展简史与现状
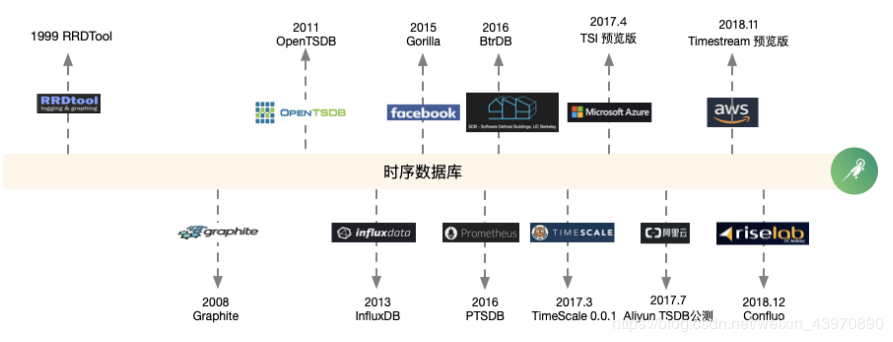
目前,DB-Engines把时间序列数据库作为独立的目录来分类统计,下图就是2018年业内流行的时序数据库的关注度排名和最近5年的变化趋势。

参考文档: