一、Spark on Standalone
1.spark集群启动后,Worker向Master注册信息

2.spark-submit命令提交程序后,driver和application也会向Master注册信息


3.创建SparkContext对象:主要的对象包含DAGScheduler和TaskScheduler
4.Driver把Application信息注册给Master后,Master会根据App信息去Worker节点启动Executor
5.Executor内部会创建运行task的线程池,然后把启动的Executor反向注册给Dirver
6.DAGScheduler:负责把Spark作业转换成Stage的DAG(Directed Acyclic Graph有向无环图),根据宽窄依赖切分Stage,然后把Stage封装成TaskSet的形式发送个TaskScheduler;
同时DAGScheduler还会处理由于Shuffle数据丢失导致的失败;
7.TaskScheduler:维护所有TaskSet,分发Task给各个节点的Executor(根据数据本地化策略分发Task),监控task的运行状态,负责重试失败的task;
8.所有task运行完成后,SparkContext向Master注销,释放资源;
注:job的失败不会重试

二、Spark on Yarn
yarn是一种统一的资源管理机制,可以通过队列的方式,管理运行多套计算框架。Spark on Yarn模式根据Dirver在集群中的位置分为两种模式
一种是Yarn-Client模式,另一种是Yarn-Cluster模式
yarn框架的基本运行流程图
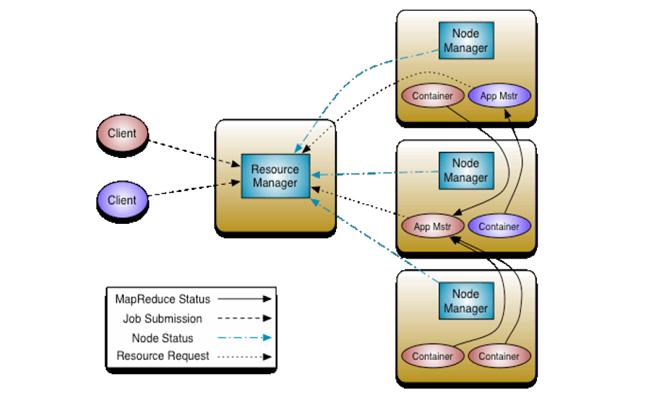
ResourceManager:负责将集群的资源分配给各个应用使用,而资源分配和调度的基本单位是Container,其中封装了集群资源(CPU、内存、磁盘等),每个任务只能在Container中运行,并且只使用Container中的资源;
NodeManager:是一个个计算节点,负责启动Application所需的Container,并监控资源的使用情况汇报给ResourceManager
ApplicationMaster:主要负责向ResourceManager申请Application的资源,获取Container并跟踪这些Container的运行状态和执行进度,执行完后通知ResourceManager注销ApplicationMaster,ApplicationMaster也是运行在Container中;
(1)client
yarn-client模式,Dirver运行在本地的客户端上。
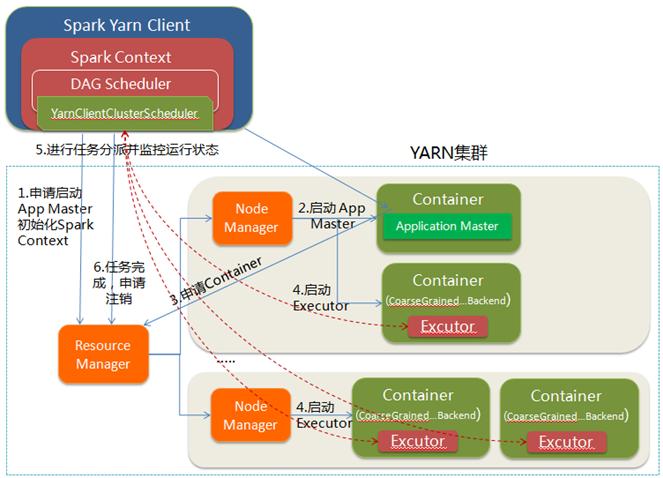
1.client向ResouceManager申请启动ApplicationMaster,同时在SparkContext初始化中创建DAGScheduler和TaskScheduler
2.ResouceManager收到请求后,在一台NodeManager中启动第一个Container运行ApplicationMaster
3.Dirver中的SparkContext初始化完成后与ApplicationMaster建立通讯,ApplicationMaster向ResourceManager申请Application的资源
4.一旦ApplicationMaster申请到资源,便与之对应的NodeManager通讯,启动Executor,并把Executor信息反向注册给Dirver
5.Dirver分发task,并监控Executor的运行状态,负责重试失败的task
6.运行完成后,Client的SparkContext向ResourceManager申请注销并关闭自己
(2)cluster
yarn-cluster模式中,当用户向yarn提交应用程序后,yarn将分为两阶段运行该应用程序:
第一个阶段是把Spark的Dirver作为一个ApplicationMaster在yarn中启动;
第二个阶段是ApplicationMaster向ResourceManager申请资源,并启动Executor来运行task,同时监控task整个运行流程并重试失败的task;
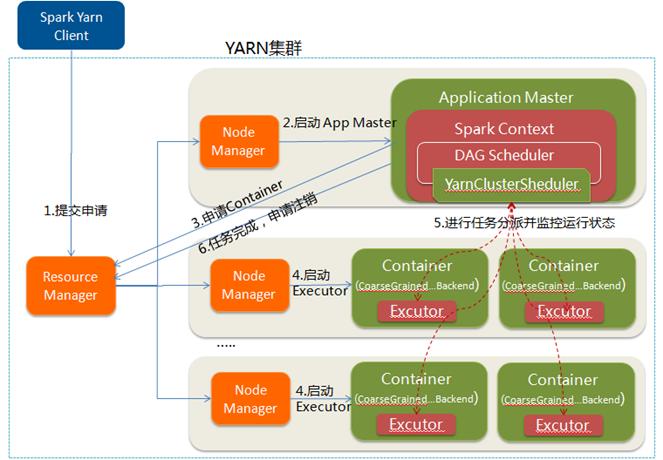
Yarn-client和Yarn-cluster的区别:
yarn-cluster模式下,Dirver运行在ApplicationMaster中,负责申请资源并监控task运行状态和重试失败的task,当用户提交了作业之后就可以关掉client,作业会继续在yarn中运行;
yarn-client模式下,Dirver运行在本地客户端,client不能离开。
Dirver与集群间的通信主要有以下几点:
1.注册Dirver信息
2.根据宽窄依赖切分stage
3.注册Application信息
4.分发task
5.监听task的运行状态
6.重试失败的task
7.重试失败的stage
Spark的数据本地化机制有以下5种:
1、PROCESS_LOCAL 进程本地化
2、NODE_LOCAL 节点本地化
3、NO_PREF 读取的数据在数据库中
4、RACK_LOCAL 机架本地化
5、ANY 跨机架
如何选择数据本地化的级别?
TaskScheduler发送的task在Executor上无法执行时,TaskScheduler会降低数据本地化的级别,再次发送,如果还是无法执行,再降低一次数据本地化的级别,再次发送,直至可以执行。
默认每次等待3s,重试5次,之后降一级本地化级别。
如何提高数据本地化的级别?
task执行的等待时间延长,从原来的3s提高到6s
提高数据本地化的级别要注意,不要本末倒置
spark.locality.wait 默认3s
spark.locality.process 等待进程本地化的时间,默认与spark.locality.wait相等
spark.locality.node
spark.locality.rack
Spark shuffle阶段的数据传输
MapOutputTrackerWorker(从):在spark集群的每个worker中,负责将本地的map output block信息发送给master中的MapOutputTrackerMaster
MapOutputTrackerMaster(主):在spark集群的master中,负责记录各个worker节点的map output block信息
BlockManager:每个Executor中的BlockManager实例化的时候都会向Dirver中的BlockManagerMaster注册信息,而BlockManagerMaster会创建BlockManagerInfo来管理元数据信息
BlockManagerMaster:在DAGScheduler对象中,管理元数据信息
BlockManagerSlaveEndpoint:在Executor端,负责接收BlockManagerMaster发送过来的信息
BlockTransferService:传输各个节点的block
MemoryStore、DiskStore