1.StackOverflowError
问题:简单代码记录 :
for (day <- days){
rdd = rdd.union(sc.textFile(/path/to/day) .... )
}
大概场景就是我想把数量比较多的文件合并成一个大rdd,从而导致了栈溢出;
解决:很明显是方法递归调用太多,我之后改成了几个小任务进行了合并;这里union也会造成最终rdd分区数过多
2.java.io.FileNotFoundException: /tmp/spark-90507c1d-e98 ..... temp_shuffle_98deadd9-f7c3-4a12(No such file or directory) 类似这种
报错:Exception in thread "main" org.apache.spark.SparkException: Job aborted due to stage failure: Task 0 in stage 76.0 failed 4 times, most recent failure: Lost task 0.3 in stage 76.0 (TID 341, 10.5.0.90): java.io.FileNotFoundException: /tmp/spark-90507c1d-e983-422d-9e01-74ff0a5a2806/executor-360151d5-6b83-4e3e-a0c6-6ddc955cb16c/blockmgr-bca2bde9-212f-4219-af8b-ef0415d60bfa/26/temp_shuffle_98deadd9-f7c3-4a12-9a30-7749f097b5c8 (No such file or directory)
场景:大概代码和上面差不多:
for (day <- days){
rdd = rdd.union(sc.textFile(/path/to/day) .... )
}
rdd.map( ... )
解决:简单的map都会报错,怀疑是临时文件过多;查看一下rdd.partitions.length 果然有4k多个;基本思路就是减少分区数
可以在union的时候就进行重分区:
for (day <- days){
rdd = rdd.union(sc.textFile(/path/to/day,numPartitions) .... )
rdd = rdd.coalesce(numPartitions)
} //这里因为默认哈希分区,并且分区数相同;所有最终union的rdd的分区数不会增多,贴一下源码以防说错
/** Build the union of a list of RDDs. */
def union[T: ClassTag](rdds: Seq[RDD[T]]): RDD[T] = withScope {
val partitioners = rdds.flatMap(_.partitioner).toSet
if (rdds.forall(_.partitioner.isDefined) && partitioners.size == 1) {
/*这里如果rdd的分区函数都相同则会构建一个PartitionerAwareUnionRDD:m RDDs with p partitions each
* will be unified to a single RDD with p partitions*/
new PartitionerAwareUnionRDD(this, rdds)
} else {
new UnionRDD(this, rdds)
}
}
或者最后在重分区
for (day <- days){
rdd = rdd.union(sc.textFile(/path/to/day) .... )
}
rdd.repartition(numPartitions)
3.java.lang.NoClassDefFoundError: Could not initialize class com.tzg.scala.play.UserPlayStatsByUuid$
at com.tzg.scala.play.UserPlayStatsByUuid$$anonfun$main$2.apply(UserPlayStatsByUuid.scala:42)
at com.tzg.scala.play.UserPlayStatsByUuid$$anonfun$main$2.apply(UserPlayStatsByUuid.scala:40)
场景:用scala 写的一个类,把所有的常量都放到了类的成员变量声明部分,结果在加载这个类的成员变量时报错
反编译成java代码
public final class implements Serializable {
public static final MODULE$; private final int USER_OPERATION_OPERATION_TYPE;
public int USER_OPERATION_OPERATION_TYPE() { return this.USER_OPERATION_OPERATION_TYPE; } static { new (); }
private Object readResolve(){return MODULE$; }
private () {MODULE$ = this; this.USER_OPERATION_OPERATION_TYPE = 4;}
}
报错部分类字节码:

解决:在加载类的一个成员变量失败,导致抛出NoClassDefFoundError:Could not initialize class,把这些常量移出类的声明体,那么在初始化时肯定不会加载失败了
4.ContextCleaner Time Out
17/01/04 03:32:49 [ERROR] [org.apache.spark.ContextCleaner:96] - Error cleaning broadcast 414
akka.pattern.AskTimeoutException: Timed out
解决:spark-submit增加了两个参数:
--conf spark.cleaner.referenceTracking.blocking=true
--conf spark.cleaner.referenceTracking.blocking.shuffle=true
参考自spark-issue:SPARK-3139
5. java.lang.NoSuchMethodError: scala.Predef$.ArrowAssoc(Ljava/lang/Object;)
解决:scala环境和spark环境不匹配,spark1.x 对应scala10 ; spark2.x 对应scala11
6.join操作:
不管是spark还是pandas,都不会对两个join的表进行去重,所以如果要join的关联键是重复的,结果肯定会让人意想不到,所以谨记join时保证关联键是不重复的
rdd1 = sc.makeRDD(List('A','A','B'))
val pairs1 = rdd1.map(k => (k,1))
val rdd2 = sc.makeRDD(List('A','B','B'))
val pairs2 = rdd2.map(k => (k,1))
pairs1.join(pairs2).collect() // Array[(Char, (Int, Int))] = Array((B,(1,1)), (B,(1,1)), (A,(1,1)), (A,(1,1)))
7.spark streaming Could not compute split, block input-0-1449191870000 not found
15/12/04 15:27:27 WARN [task-result-getter-0] TaskSetManager: Lost task 0.0 in stage 3.0 (TID 56, 192.168.0.2): java.lang.Exception: Could not compute split, block input-0-1449191870000 not found at org.apache.spark.rdd.BlockRDD.compute(BlockRDD.scala:51) at org.apache.spark.rdd.RDD.computeOrReadCheckpoint(RDD.scala:277) at org.apache.spark.rdd.RDD.iterator(RDD.scala:244) at org.apache.spark.rdd.MapPartitionsRDD.compute(MapPartitionsRDD.scala:35) at org.apache.spark.rdd.RDD.computeOrReadCheckpoint(RDD.scala:277) at org.apache.spark.rdd.RDD.iterator(RDD.scala:244) at org.apache.spark.rdd.MapPartitionsRDD.compute(MapPartitionsRDD.scala:35) at org.apache.spark.rdd.RDD.computeOrReadCheckpoint(RDD.scala:277) at org.apache.spark.rdd.RDD.iterator(RDD.scala:244) at org.apache.spark.scheduler.ShuffleMapTask.runTask(ShuffleMapTask.scala:70) at org.apache.spark.scheduler.ShuffleMapTask.runTask(ShuffleMapTask.scala:41) at org.apache.spark.scheduler.Task.run(Task.scala:70) at org.apache.spark.executor.Executor$TaskRunner.run(Executor.scala:213) at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1142) at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:617) at java.lang.Thread.run(Thread.java:745)
解决:加大executor内存
8.JSON.parseFull(jsonArrayStr)抛出异常:
exception For input string: "1496713640091"
java.lang.NumberFormatException.forInputString(NumberFormatException.java:65)
java.lang.Integer.parseInt(Integer.java:495)
java.lang.Integer.parseInt(Integer.java:527)
scala.collection.immutable.StringLike$class.toInt(StringLike.scala:229)
scala.collection.immutable.StringOps.toInt(StringOps.scala:31)
kafka.utils.Json$$anonfun$1.apply(Json.scala:27)
kafka.utils.Json$$anonfun$1.apply(Json.scala:27)
scala.util.parsing.json.Parser$$anonfun$number$1.applyOrElse(Parser.scala:140)
scala.util.parsing.json.Parser$$anonfun$number$1.applyOrElse(Parser.scala:140)
问题很明显就是数值太大了,然后就各种找源码
scala-doc:http://www.scala-lang.org/api/2.10.5/index.html#scala.util.parsing.json.JSON$
scala-source:https://github.com/scala/scala/blob/v2.10.5/src/library/scala/util/parsing/json/JSON.scala#L1
https://github.com/scala/scala/blob/2.10.x/src/library/scala/util/parsing/combinator/Parsers.scala
kafka-source:
https://github.com/apache/kafka/blob/trunk/core/src/main/scala/kafka/utils/Json.scala
截取重要代码如下:
可以看到kafka.util.Json的parseFull类会调用scala.util.parsing.json.JSON.parseFull方法,而这个JSON实例有个属性gobalNumberParser来指定数字型的字符串默认转成Int,这里就是问题所在,当数字过大的时候就会报错NumberFormatException
解决方法:
修改默认转换函数:
val myConversionFunc = {input : String => input.toLong} //源码中是toInt,uid之类的会报错
JSON.globalNumberParser = myConversionFunc
9.最近学习google tensorflow下的wide and deep leanrning的教程,原教程是全部数据fit进去的,我的赛题数据太大,所以直接报错OOM,然后就开始找各种解决办法,如下是谷歌的官方回复,先贴在这里:
Wide_n_deep : question on input_fn(df) - Google Groups
然后我的需求就是将pandas对象直接转成tensor,然后做一个分批次的生成器,对应的核心代码剪切到这里:
1 def input_fn(): 2 """ 3 假定数据源是一个5行, 分隔的,类型全都是float的tsv文件;前4列是特征,后1列是目标变量 4 """ 5 parse_fn = lambda example: tf.decode_csv(records=example, 6 record_defaults=[[0.0], [0.0], [0.0], [0.0], [0.0]], 7 field_delim=' ') 8 9 inputs = tf.contrib.learn.read_batch_examples(file_pattern=file_paths, 10 batch_size=256, 11 reader=tf.TextLineReader, 12 randomize_input=True, 13 num_epochs=1, 14 queue_capacity=10000, 15 num_threads=1, 16 parse_fn=parse_fn, 17 seed = None) 18 19 feats = {} 20 21 for i, header in enumerate(["feature1", "feature2", "feature3", "feature4"]): 22 feats[header] = inputs[:, i] 23 targets = inputs[:, 4] 24 25 return feats, targets
初学TF,顺便贴下相关函数的函数API:
tf.contrib.learn.read_batch_examples
10.Unsupported major.minor version 52.0
Exception in thread "main" java.lang.UnsupportedClassVersionError: com/sensorsdata/analytics/tools/hdfsimporter/HdfsImporter : Unsupported major.minor version 52.0 at java.lang.ClassLoader.defineClass1(Native Method) at java.lang.ClassLoader.defineClass(ClassLoader.java:800) at java.security.SecureClassLoader.defineClass(SecureClassLoader.java:142) at java.net.URLClassLoader.defineClass(URLClassLoader.java:449) at java.net.URLClassLoader.access$100(URLClassLoader.java:71) at java.net.URLClassLoader$1.run(URLClassLoader.java:361) at java.net.URLClassLoader$1.run(URLClassLoader.java:355) at java.security.AccessController.doPrivileged(Native Method) at java.net.URLClassLoader.findClass(URLClassLoader.java:354) at java.lang.ClassLoader.loadClass(ClassLoader.java:425) at java.lang.ClassLoader.loadClass(ClassLoader.java:358) at java.lang.Class.forName0(Native Method) at java.lang.Class.forName(Class.java:270) at org.apache.hadoop.util.RunJar.run(RunJar.java:214) at org.apache.hadoop.util.RunJar.main(RunJar.java:136)
52是java 8的版本,需要升级原来的jdk,或者重新编译原来的类
11.java.sql.SQLException: Unable to open a test connection to the given database. JDBC url = jdbc:mysql://127.0.0.1/hive?createDatabaseIfNotExist=true
The last packet sent successfully to the server was 0 milliseconds ago. The driver has not received any packets from the server. at sun.reflect.NativeConstructorAccessorImpl.newInstance0(Native Method) at sun.reflect.NativeConstructorAccessorImpl.newInstance(NativeConstructorAccessorImpl.java:57) at sun.reflect.DelegatingConstructorAccessorImpl.newInstance(DelegatingConstructorAccessorImpl.java:45) at java.lang.reflect.Constructor.newInstance(Constructor.java:526) at com.mysql.jdbc.Util.handleNewInstance(Util.java:411) at com.mysql.jdbc.SQLError.createCommunicationsException(SQLError.java:1121) at com.mysql.jdbc.MysqlIO.<init>(MysqlIO.java:357) at com.mysql.jdbc.ConnectionImpl.coreConnect(ConnectionImpl.java:2482) at com.mysql.jdbc.ConnectionImpl.connectOneTryOnly(ConnectionImpl.java:2519) at com.mysql.jdbc.ConnectionImpl.createNewIO(ConnectionImpl.java:2304) at com.mysql.jdbc.ConnectionImpl.<init>(ConnectionImpl.java:834) at com.mysql.jdbc.JDBC4Connection.<init>(JDBC4Connection.java:47) at sun.reflect.NativeConstructorAccessorImpl.newInstance0(Native Method) at sun.reflect.NativeConstructorAccessorImpl.newInstance(NativeConstructorAccessorImpl.java:57) at sun.reflect.DelegatingConstructorAccessorImpl.newInstance(DelegatingConstructorAccessorImpl.java:45) at java.lang.reflect.Constructor.newInstance(Constructor.java:526) at com.mysql.jdbc.Util.handleNewInstance(Util.java:411) at com.mysql.jdbc.ConnectionImpl.getInstance(ConnectionImpl.java:416) at com.mysql.jdbc.NonRegisteringDriver.connect(NonRegisteringDriver.java:346) at java.sql.DriverManager.getConnection(DriverManager.java:571) at java.sql.DriverManager.getConnection(DriverManager.java:187) at com.jolbox.bonecp.BoneCP.obtainRawInternalConnection(BoneCP.java:361) at com.jolbox.bonecp.BoneCP.<init>(BoneCP.java:416) at com.jolbox.bonecp.BoneCPDataSource.getConnection(BoneCPDataSource.java:120) at org.datanucleus.store.rdbms.ConnectionFactoryImpl$ManagedConnectionImpl.getConnection(ConnectionFactoryImpl.java:501) at org.datanucleus.store.rdbms.RDBMSStoreManager.<init>(RDBMSStoreManager.java:298) at sun.reflect.NativeConstructorAccessorImpl.newInstance0(Native Method) at sun.reflect.NativeConstructorAccessorImpl.newInstance(NativeConstructorAccessorImpl.java:57) at sun.reflect.DelegatingConstructorAccessorImpl.newInstance(DelegatingConstructorAccessorImpl.java:45) at java.lang.reflect.Constructor.newInstance(Constructor.java:526) at org.datanucleus.plugin.NonManagedPluginRegistry.createExecutableExtension(NonManagedPluginRegistry.java:631) at org.datanucleus.plugin.PluginManager.createExecutableExtension(PluginManager.java:301) at org.datanucleus.NucleusContext.createStoreManagerForProperties(NucleusContext.java:1187) at org.datanucleus.NucleusContext.initialise(NucleusContext.java:356) at org.datanucleus.api.jdo.JDOPersistenceManagerFactory.freezeConfiguration(JDOPersistenceManagerFactory.java:775) at org.datanucleus.api.jdo.JDOPersistenceManagerFactory.createPersistenceManagerFactory(JDOPersistenceManagerFactory.java:333) at org.datanucleus.api.jdo.JDOPersistenceManagerFactory.getPersistenceManagerFactory(JDOPersistenceManagerFactory.java:202) at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method) at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:57) at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43) at java.lang.reflect.Method.invoke(Method.java:606) at javax.jdo.JDOHelper$16.run(JDOHelper.java:1965) at java.security.AccessController.doPrivileged(Native Method) at javax.jdo.JDOHelper.invoke(JDOHelper.java:1960) at javax.jdo.JDOHelper.invokeGetPersistenceManagerFactoryOnImplementation(JDOHelper.java:1166) at javax.jdo.JDOHelper.getPersistenceManagerFactory(JDOHelper.java:808) at javax.jdo.JDOHelper.getPersistenceManagerFactory(JDOHelper.java:701) at org.apache.hadoop.hive.metastore.ObjectStore.getPMF(ObjectStore.java:365) at org.apache.hadoop.hive.metastore.ObjectStore.getPersistenceManager(ObjectStore.java:394) at org.apache.hadoop.hive.metastore.ObjectStore.initialize(ObjectStore.java:291) at org.apache.hadoop.hive.metastore.ObjectStore.setConf(ObjectStore.java:258) at org.apache.hadoop.util.ReflectionUtils.setConf(ReflectionUtils.java:73) at org.apache.hadoop.util.ReflectionUtils.newInstance(ReflectionUtils.java:133) at org.apache.hadoop.hive.metastore.RawStoreProxy.<init>(RawStoreProxy.java:57) at org.apache.hadoop.hive.metastore.RawStoreProxy.getProxy(RawStoreProxy.java:66) at org.apache.hadoop.hive.metastore.HiveMetaStore$HMSHandler.newRawStore(HiveMetaStore.java:593) at org.apache.hadoop.hive.metastore.HiveMetaStore$HMSHandler.getMS(HiveMetaStore.java:571) at org.apache.hadoop.hive.metastore.HiveMetaStore$HMSHandler.createDefaultDB(HiveMetaStore.java:620) at org.apache.hadoop.hive.metastore.HiveMetaStore$HMSHandler.init(HiveMetaStore.java:461) at org.apache.hadoop.hive.metastore.RetryingHMSHandler.<init>(RetryingHMSHandler.java:66) at org.apache.hadoop.hive.metastore.RetryingHMSHandler.getProxy(RetryingHMSHandler.java:72) at org.apache.hadoop.hive.metastore.HiveMetaStore.newRetryingHMSHandler(HiveMetaStore.java:5762) at org.apache.hadoop.hive.metastore.HiveMetaStoreClient.<init>(HiveMetaStoreClient.java:199) at org.apache.hadoop.hive.ql.metadata.SessionHiveMetaStoreClient.<init>(SessionHiveMetaStoreClient.java:74) at sun.reflect.NativeConstructorAccessorImpl.newInstance0(Native Method) at sun.reflect.NativeConstructorAccessorImpl.newInstance(NativeConstructorAccessorImpl.java:57) at sun.reflect.DelegatingConstructorAccessorImpl.newInstance(DelegatingConstructorAccessorImpl.java:45) at java.lang.reflect.Constructor.newInstance(Constructor.java:526) at org.apache.hadoop.hive.metastore.MetaStoreUtils.newInstance(MetaStoreUtils.java:1521) at org.apache.hadoop.hive.metastore.RetryingMetaStoreClient.<init>(RetryingMetaStoreClient.java:86) at org.apache.hadoop.hive.metastore.RetryingMetaStoreClient.getProxy(RetryingMetaStoreClient.java:132) at org.apache.hadoop.hive.metastore.RetryingMetaStoreClient.getProxy(RetryingMetaStoreClient.java:104) at org.apache.hadoop.hive.ql.metadata.Hive.createMetaStoreClient(Hive.java:3005) at org.apache.hadoop.hive.ql.metadata.Hive.getMSC(Hive.java:3024) at org.apache.hadoop.hive.ql.session.SessionState.start(SessionState.java:503) at org.apache.spark.sql.hive.client.ClientWrapper.<init>(ClientWrapper.scala:204) at sun.reflect.NativeConstructorAccessorImpl.newInstance0(Native Method) at sun.reflect.NativeConstructorAccessorImpl.newInstance(NativeConstructorAccessorImpl.java:57) at sun.reflect.DelegatingConstructorAccessorImpl.newInstance(DelegatingConstructorAccessorImpl.java:45) at java.lang.reflect.Constructor.newInstance(Constructor.java:526) at org.apache.spark.sql.hive.client.IsolatedClientLoader.createClient(IsolatedClientLoader.scala:249) at org.apache.spark.sql.hive.HiveContext.metadataHive$lzycompute(HiveContext.scala:327) at org.apache.spark.sql.hive.HiveContext.metadataHive(HiveContext.scala:237) at org.apache.spark.sql.hive.HiveContext.setConf(HiveContext.scala:441) at org.apache.spark.sql.hive.HiveContext.defaultOverrides(HiveContext.scala:226) at org.apache.spark.sql.hive.HiveContext.<init>(HiveContext.scala:229) at org.apache.spark.sql.hive.HiveContext.<init>(HiveContext.scala:101) at sun.reflect.NativeConstructorAccessorImpl.newInstance0(Native Method) at sun.reflect.NativeConstructorAccessorImpl.newInstance(NativeConstructorAccessorImpl.java:57) at sun.reflect.DelegatingConstructorAccessorImpl.newInstance(DelegatingConstructorAccessorImpl.java:45) at java.lang.reflect.Constructor.newInstance(Constructor.java:526) at py4j.reflection.MethodInvoker.invoke(MethodInvoker.java:234) at py4j.reflection.ReflectionEngine.invoke(ReflectionEngine.java:381) at py4j.Gateway.invoke(Gateway.java:214) at py4j.commands.ConstructorCommand.invokeConstructor(ConstructorCommand.java:79) at py4j.commands.ConstructorCommand.execute(ConstructorCommand.java:68) at py4j.GatewayConnection.run(GatewayConnection.java:209) at java.lang.Thread.run(Thread.java:745) Caused by: java.net.ConnectException: Connection refused at java.net.PlainSocketImpl.socketConnect(Native Method) at java.net.AbstractPlainSocketImpl.doConnect(AbstractPlainSocketImpl.java:339) at java.net.AbstractPlainSocketImpl.connectToAddress(AbstractPlainSocketImpl.java:200) at java.net.AbstractPlainSocketImpl.connect(AbstractPlainSocketImpl.java:182) at java.net.SocksSocketImpl.connect(SocksSocketImpl.java:392) at java.net.Socket.connect(Socket.java:579) at java.net.Socket.connect(Socket.java:528) at java.net.Socket.<init>(Socket.java:425) at java.net.Socket.<init>(Socket.java:241) at com.mysql.jdbc.StandardSocketFactory.connect(StandardSocketFactory.java:259) at com.mysql.jdbc.MysqlIO.<init>(MysqlIO.java:307) ... 91 more
解决:修改$SPARK_HOME/conf/hive-site.xml的javax.jdo.option.ConnectionURL值为正确的mysql连接串
keras训练多文本分类的时候,总是碰到loss为nan的情况,如下图:
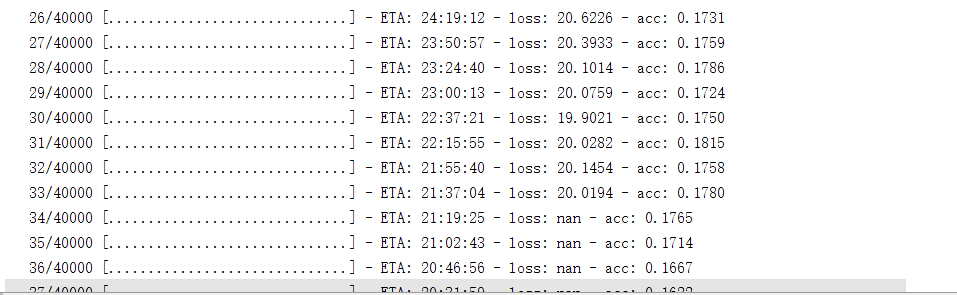
那么我试验中两个debug的地方就是修改激活函数和最后一个全连接层的神经元个数:
激活函数是softmax,最后一层神经元是类别个数的两倍
12.Mongo Hadoop Connector使用过程中,hive查询where不可以使用等号"="

从上图可以明显看出,“=”并不能获得期望的结果,可以通过使用“in”或者“like”来获取期望结果。同时,“==”并不会报错,而且效果与“=”一致,都是错误的。
13.Caused by: java.io.FileNotFoundException: File does not exist: hdfs://nameservice/user/hive/warehouse/prod.db/my_table/000000_0_copy_2
场景:hadoop多用户使用,一个程序往hive数据库写,另一个程序去查;就会出现数据不存在的问题