Oracle数据库中的函数有多种,比如单行函数、聚合函数、对象引用函数、模型函数、OLAP函数等。本篇将详细介绍Oracle数据库中的分析函数。
一 分析函数概述
所谓分析函数,是基于一组数据行计算聚合值,其与聚合函数的不同之处在于,它为每一组返回多个数据行。一组数据行称为一个窗口,由analytic_clause子句进行定义,对于每一行,定义一个行移动窗口,窗口确定用于为当前行执行计算的行的范围,它的大小可以基于物理行或逻辑间隔(如时间)。
二 分析函数语法

说明:
analytic_function
指出分析函数的名称;
arguments
分析函数的参数,参数数量在0个到3个之间,该参数类型可以是任何数值数据类型,或者任何可以隐式转换为数值数据类型的非数值类型。

analytic_clause
使用OVER analytic_clause子句展示在查询结果集上所进行的函数操作,该子句是在FROM、WHERE、GROUP BY和HAVING子句后进行计算的。
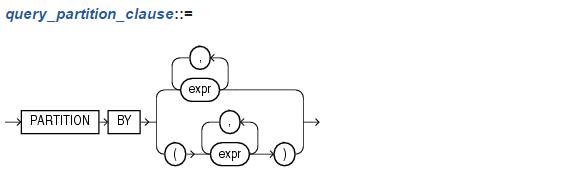
使用PARTITION BY子句可以基于一个或多个expr将查询结果集划分为多个组,如果忽略该子句,则函数会将整个查询结果集当做一个组。
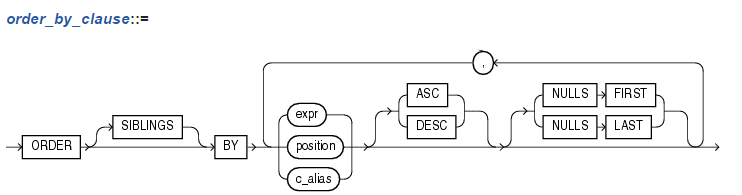
order_by_clause子句用于指定数据是在一个分组里是如何进行排序的。
![]()
三 分析函数类型
Oracle有以下类型的分析函数,其中,带有*号的函数可以使用上面的完全语句,包括窗口子句。
- AVG *
- COPR *
- COUNT *
- COVAR_POP *
- COVAR_SAMP *
- CUME_DIST
- DENSE_RANK
- FIRST
- FIRST_VALUE *
- LAG
- LAST
- LAST_VALUE *
- LEAD
- LISTAGG
- MAX *
- MEDIAN
- MIN *
- NTH_VALUE *
- NTILE
- PERCENT_RANK
- PERCENTILE_COUNT
- PERCENTILE_DISC
- RANK
- RATIO_TO_REPORT
- REGR_(Linear Regression) Functions *
- ROW_NUMBER
- STDDEV *
- STDDEV_POP *
- STDDEV_SAMP *
- SUM *
- VAR_POP *
- VAR_SAMP *
- VARIANCE *
四 分析函数详解
1 演示数据库版本
SQL> select * from v$version;
BANNER
--------------------------------------------------------------------------------
Oracle Database 11g Enterprise Edition Release 11.2.0.4.0 - 64bit Production
PL/SQL Release 11.2.0.4.0 - Production
CORE 11.2.0.4.0 Production
TNS for Linux: Version 11.2.0.4.0 - Production
NLSRTL Version 11.2.0.4.0 - Production2 AVG函数
1)语法结构

AVG函数用于返回expr的平均值,如果指定DISTINCT,那么只能指定analytic_clause中的query_partition_clause子句,不能指定order_by_clause andwindowing_clause子句。
2)示例
SQL> SELECT empno,
ename,
job,
mgr,
hiredate,
deptno,
sal,
round(AVG(sal) over(), 2) avg_all_sal,
round(AVG(sal) over(PARTITION BY deptno), 2) avg_dept_sal,
round(AVG(sal) over(PARTITION BY deptno ORDER BY empno
rows BETWEEN 1 preceding AND 1 following),2) avg_sal1,
round(AVG(sal) over(PARTITION BY deptno ORDER BY empno
rows BETWEEN CURRENT ROW AND 1 following),2) avg_sal2
FROM emp; 3 COUNT
3 COUNT
1)语法结构
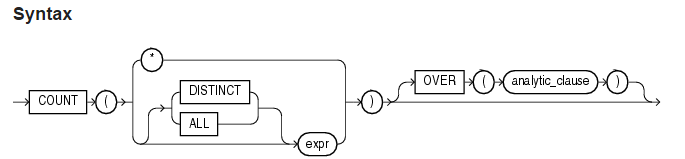
COUNT返回查询的行数,如果指定DISTINCT,那么只能指定analytic_clause中的query_partition_clause子句,不能指定order_by_clause andwindowing_clause子句。如果指定expr,COUNT返回expr非空的行数,如果指定*,则返回所有行数,包括重复行和空行。
2)示例
SQL> SELECT empno,
ename,
job,
mgr,
hiredate,
deptno,
sal,
comm,
COUNT(1) over() qty1,
COUNT(*) over() qty2,
COUNT(comm) over() qty3,
COUNT(DISTINCT deptno) over() qty4,
COUNT(1) over(PARTITION BY deptno) qty5
FROM emp;![]()
4 RANK、DENSE_RANK、ROW_NUMBER
1)语法结构
![]()
2)示例
SQL> SELECT empno,
ename,
job,
mgr,
hiredate,
sal,
deptno,
--row_number() over(ORDER BY sal) rn1,
row_number() over(PARTITION BY deptno ORDER BY sal) rn2,
--rank()over(order by sal) rn3
rank() over(PARTITION BY deptno ORDER BY sal) r4,
dense_rank() over(PARTITION BY deptno ORDER BY sal) r5
FROM emp;![]()
注:这三个函数主要用于进行排序,ROW_NUMBER函数排序的结果是连续的,而DENSE函数排序会出现跳号,DENSE_RANK函数排序,不会出现跳号。
5 FIRST_VALUE
1)语法结构
![]()
FIRST_VALUE用于返回在一个排序结果集中的第一个值。
2)示例
SQL> SELECT empno,
ename,
job,
mgr,
hiredate,
sal,
deptno,
first_value(sal) over(PARTITION BY deptno ORDER BY sal) sal,
first_value(sal) over(PARTITION BY deptno ORDER BY sal DESC) sal2
FROM emp;![]()
6 LAST_VALUE
1)语法结构
![]()
对于该函数,如果忽略了analytic_clause子句中的windowing_clause子句,默认是使用RANGE BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW ,使用默认值有时可能返回不是预期的结果,因为LAST VALUE是窗口中的最后一个值,它不是固定的,而是随着当前行的改变而改变。为了得到与其的结果,可以使用RANGE BETWEEN UNBOUNDED PRECEDING AND UNBOUNDED FOLLOWING窗口,也可以使用RANGE BETWEEN CURRENT ROW AND UNBOUNDED FOLLOWING窗口。
2)示例
SQL> SELECT empno,
ename,
job,
mgr,
hiredate,
sal,
deptno,
last_value(sal) over(PARTITION BY deptno ORDER BY sal) sal1,
last_value(sal) over(PARTITION BY deptno ORDER BY sal RANGE BETWEEN unbounded preceding AND CURRENT ROW) sal2,
last_value(sal) over(PARTITION BY deptno ORDER BY sal RANGE BETWEEN unbounded preceding AND unbounded following) sal3,
last_value(sal) over(PARTITION BY deptno ORDER BY sal RANGE BETWEEN CURRENT ROW AND unbounded following) sal4,
last_value(sal) over(PARTITION BY deptno ORDER BY sal DESC RANGE BETWEEN unbounded preceding AND unbounded following) sal5,
last_value(sal) over(PARTITION BY deptno ORDER BY sal rows BETWEEN unbounded preceding AND unbounded following) sal6
FROM emp;![]()
7 LAG
1)语法结构
![]()
该函数提供了在不使用自连接的情况下同时访问表的多行的能力,即将数据行根据偏移量靠后,offset参数指定偏移量,默认值为1,default参数指定超过窗口边界的默认值,没有指定,则为NULL。
2)示例
SQL> SELECT empno,
ename,
job,
mgr,
hiredate,
sal,
deptno,
lag(sal) over(PARTITION BY deptno ORDER BY sal) sal1,
lag(sal, 1) over(PARTITION BY deptno ORDER BY sal) sal2,
lag(sal, 2, 0) over(PARTITION BY deptno ORDER BY sal) sal3
FROM emp;![]()
8 LEAD
1)语法结构
![]()
该函数和LAG函数功能相反,主要用于将行数据提前。
2)示例
SQL> SELECT empno,
ename,
job,
mgr,
hiredate,
sal,
deptno,
lead(sal) over(PARTITION BY deptno ORDER BY sal) sal1,
lead(sal, 1) over(PARTITION BY deptno ORDER BY sal) sal2,
lead(sal, 2, 0) over(PARTITION BY deptno ORDER BY sal) sal3
FROM emp;![]()
9 LISTAGG
1)语法结构
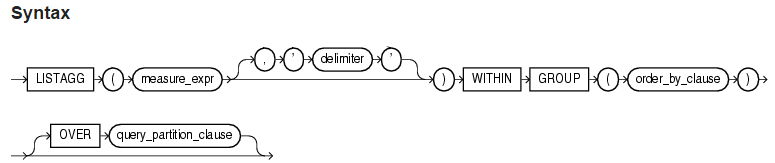
该函数用于在分组内对数据进行排序,然后将对应的值进行拼接,参数delimilter用于指定拼接符。
2)示例
SQL> SELECT empno,
ename,
job,
mgr,
hiredate,
sal,
deptno,
listagg(ename, ',') within GROUP(ORDER BY empno) over(PARTITION BY deptno) name1
FROM emp;![]()
思考:如果拼接的列数据类型为varchar2,则有无长度限制,如果超过了该怎么处理?
SQL> SELECT deptno,
dbms_lob.substr(substr(rtrim(xmlcast(xmlagg(xmlelement(e,
ename || ',')
ORDER BY empno) AS CLOB),
','),
1,
100)) NAME
FROM emp
GROUP BY deptno;
10 MAX、MIN、SUM
1)语法结构
![]()
这三个函数主要用于在分组内求最大值、最小值以及求和。
2)示例
SQL> SELECT empno,
ename,
job,
mgr,
hiredate,
sal,
deptno,
MAX(sal) over() sal1,
MAX(sal) over(PARTITION BY deptno) sal2,
MAX(sal) over(PARTITION BY deptno ORDER BY empno rows BETWEEN unbounded preceding AND 1 following) sal3,
MIN(sal) over() sal4,
MIN(sal) over(PARTITION BY deptno) sal5,
MIN(sal) over(PARTITION BY deptno ORDER BY empno rows BETWEEN unbounded preceding AND 1 following) sal6,
SUM(sal) over() sal7,
SUM(sal) over(PARTITION BY deptno) sal8,
SUM(sal) over(PARTITION BY deptno ORDER BY empno rows BETWEEN unbounded preceding AND 1 following) sal9
FROM emp;11 CUME_DIST
1)语法结构
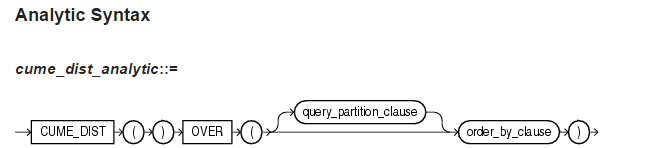
该函数用于计算一个值在一组值中的累积分布,返回的值的范围是0到1。计算逻辑为:在一组值中某一个值的相对位置,即对于某一行R,总行数为N,值为R/N。
2)示例
SQL> SELECT empno,
ename,
job,
mgr,
hiredate,
sal,
deptno,
cume_dist() over(ORDER BY sal) p1,
cume_dist() over(PARTITION BY deptno ORDER BY sal) p2
FROM emp
ORDER BY deptno, sal;![]()
12 PERCENT_RANK
1)语法结构
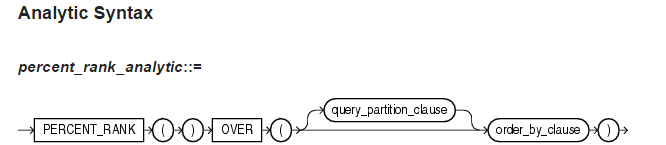
该函数和CUME_DIST函数类似,返回值的范围是0到1,使用该函数的任何集合的第一行是0。计算逻辑为:对于某一行R,总行数为N,值为(R-1)/(N-1)。
2)示例
SQL> SELECT empno,
ename,
job,
mgr,
hiredate,
sal,
deptno,
percent_rank() over(ORDER BY sal) p1,
percent_rank() over(PARTITION BY deptno ORDER BY sal) p2
FROM emp
ORDER BY deptno, sal;![]()