最近开始学习机器学习,以下会记录我学习中遇到的问题以及我个人的理解
决策树算法,网上很多介绍,在这不复制粘贴。下面解释几个关键词就好。
信息熵(entropy):就是信息不确定性的多少 H(x)=-ΣP(x)log2[P(x)]。变量的不确定性越大,熵就越大。
信息获取量(Information Gain):这是ID3算法中定义的一个选择属性判断结点的算法。Gain(A)=H(D)-HA(D)。就是本的信息熵与下一级的信息熵之差。用来确定信息获取量的多少,信息获取量最多的即选择为本级的判断属性。就这样一层一层的算,一层一层的判断。
决策树的原理很简答,表达也很直观,Python中的sklearn库能够直接实现
1 from sklearn.feature_extraction import DictVectorizer 2 import csv 3 from sklearn import preprocessing 4 from sklearn import tree 5 from sklearn.externals.six import StringIO 6 7 allElectronicsData=open (r'AllElectronics.csv','rt') #'rb'是读取二进制文件,'rt'是读取文本文件 r‘’是让字符串里面的转义字符失效 8 reader=csv.reader(allElectronicsData) 9 headers=next(reader) #读取下一行数据 10 print("headers:",headers) 11 12 #将表格转化为特征向量字典列表和标签列表 13 FeatureList=[] #储存特征向量字典列表 14 LableList=[] #储存标签列表 15 for row in reader: 16 LableList.append(row[len(row)-1]) 17 rowDict={} 18 for i in range(1,len(row)-1): 19 rowDict[headers[i]]=row[i] 20 FeatureList.append(rowDict) 21 print("LableList:",LableList) 22 print("FeatureList:",FeatureList) 23 24 #将上述列表转化为sklearn可处理的形式。也就是每个属性每个元素都表示出来,有为1 ,没有为0 25 vec=DictVectorizer() 26 dummyX=vec.fit_transform(FeatureList) .toarray()#转化为矩阵 27 print("dummyX",dummyX) 28 print(vec.get_feature_names()) 29 30 lb=preprocessing.LabelBinarizer() 31 dummyY = lb.fit_transform(LableList) 32 print("dummyY",dummyY) 33 34 #直接利用sklearn里面的tree分类器进行创建model 35 clf=tree.DecisionTreeClassifier(criterion='entropy')#创建分类器,criterion是选取算法,entropy信息熵 36 clf=clf.fit(dummyX,dummyY) 37 print("clf:",clf) 38 39 #保存为dot文件,可用graphviz画出决策树 40 with open("allElectronics.dot",'w') as f: 41 f=tree.export_graphviz(clf,feature_names=vec.get_feature_names(),out_file=f) 42 43 #预测 44 newRowX=dummyX[0,:] #取一个之前数据的第一行 45 46 newRowX[0]=1 47 newRowX[2]=0 #修改第一个属性,也就是弄出来个新的数据,这的0,1,还是上面解释的,此属性有就是1,没有就是0 48 49 print("newRowX:",newRowX) 50 newRowX=[newRowX] #一定要注意这个,predict的输入必须是个二位数据 51 predictedY = clf.predict(newRowX) 52 print("predictedY: " + str(predictedY))
里面有我注解的解释,此源码来自于麦子学院课程视频。
运行之后的结果为:
headers: ['RID', 'age', 'income', 'student', 'credit_rating', 'class_buys_computer']
LableList: ['no', 'no', 'yes', 'yes', 'yes', 'no', 'yes', 'no', 'yes', 'yes', 'yes', 'yes', 'yes', 'no']
FeatureList: [{'age': 'youth', 'income': 'high', 'student': 'no', 'credit_rating': 'fair'}, {'age': 'youth', 'income': 'high', 'student': 'no', 'credit_rating': 'excellent'}, {'age': 'middle_aged', 'income': 'high', 'student': 'no', 'credit_rating': 'fair'}, {'age': 'senior', 'income': 'medium', 'student': 'no', 'credit_rating': 'fair'}, {'age': 'senior', 'income': 'low', 'student': 'yes', 'credit_rating': 'fair'}, {'age': 'senior', 'income': 'low', 'student': 'yes', 'credit_rating': 'excellent'}, {'age': 'middle_aged', 'income': 'low', 'student': 'yes', 'credit_rating': 'excellent'}, {'age': 'youth', 'income': 'medium', 'student': 'no', 'credit_rating': 'fair'}, {'age': 'youth', 'income': 'low', 'student': 'yes', 'credit_rating': 'fair'}, {'age': 'senior', 'income': 'medium', 'student': 'yes', 'credit_rating': 'fair'}, {'age': 'youth', 'income': 'medium', 'student': 'yes', 'credit_rating': 'excellent'}, {'age': 'middle_aged', 'income': 'medium', 'student': 'no', 'credit_rating': 'excellent'}, {'age': 'middle_aged', 'income': 'high', 'student': 'yes', 'credit_rating': 'fair'}, {'age': 'senior', 'income': 'medium', 'student': 'no', 'credit_rating': 'excellent'}]
dummyX [[0. 0. 1. 0. 1. 1. 0. 0. 1. 0.]
[0. 0. 1. 1. 0. 1. 0. 0. 1. 0.]
[1. 0. 0. 0. 1. 1. 0. 0. 1. 0.]
[0. 1. 0. 0. 1. 0. 0. 1. 1. 0.]
[0. 1. 0. 0. 1. 0. 1. 0. 0. 1.]
[0. 1. 0. 1. 0. 0. 1. 0. 0. 1.]
[1. 0. 0. 1. 0. 0. 1. 0. 0. 1.]
[0. 0. 1. 0. 1. 0. 0. 1. 1. 0.]
[0. 0. 1. 0. 1. 0. 1. 0. 0. 1.]
[0. 1. 0. 0. 1. 0. 0. 1. 0. 1.]
[0. 0. 1. 1. 0. 0. 0. 1. 0. 1.]
[1. 0. 0. 1. 0. 0. 0. 1. 1. 0.]
[1. 0. 0. 0. 1. 1. 0. 0. 0. 1.]
[0. 1. 0. 1. 0. 0. 0. 1. 1. 0.]]
['age=middle_aged', 'age=senior', 'age=youth', 'credit_rating=excellent', 'credit_rating=fair', 'income=high', 'income=low', 'income=medium', 'student=no', 'student=yes']
dummyY [[0]
[0]
[1]
[1]
[1]
[0]
[1]
[0]
[1]
[1]
[1]
[1]
[1]
[0]]
clf: DecisionTreeClassifier(class_weight=None, criterion='entropy', max_depth=None,
max_features=None, max_leaf_nodes=None,
min_impurity_decrease=0.0, min_impurity_split=None,
min_samples_leaf=1, min_samples_split=2,
min_weight_fraction_leaf=0.0, presort=False, random_state=None,
splitter='best')
newRowX: [1. 0. 0. 0. 1. 1. 0. 0. 1. 0.]
predictedY: [1]
此外可用Graphviz画出决策图。
这就用到了代码中生成的dot文件,在cmd命令中运行以下命令

主要是dot -T pdf input.dot -o output.pdf这个命令。(Graphviz的安装方法网上多的是,记得添加环境变量)
生成pdf 的截图为
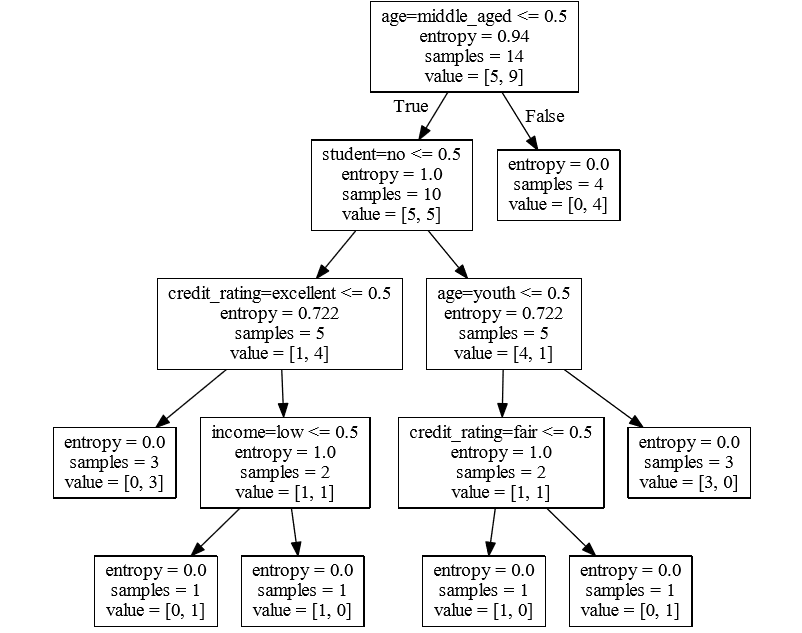
看着更直观
我编程过程中遇到几个问题,课程里面的源码不能直接运行。报错
ValueError: Expected 2D array, got 1D array instead:
array=[1. 0. 0. 0. 1. 1. 0. 0. 1. 0.].
Reshape your data either using array.reshape(-1, 1) if your data has a single feature or array.reshape(1, -1) if it contains a single sample.
如果不要第50行,就是newRowX是一维数组,而predict方法的输入量必须是二维的数组。所以加上newRowX=[newRowX],将newRowX再用[]包括,使之变为二维的数组即可。
另外注意第七行'rb'和'rt'的区别,如果用'rb'就会报错
_csv.Error: iterator should return strings, not bytes (did you open the file in text mode?)
以上就是我学习过程中遇到的问题和个人理解了。