大数据监控平台实践之路
原文地址:
一、监控体系
监控粒度、监控指标完整性、监控实时性是评价监控系统的三要素。从分层体系可以把监控系统分为三个层次:
业务层:
业务系统本质目的是为了达成业务目标,因此监控业务系统是否正常最有效的方式是从数据上监控业务目标是否达成。对业务运营数据进行监控,可及时发现程序bug或业务逻辑设计缺陷,比如注册失败率、登录失败率、付款失败率等。业务系统的多样性决定了应由各个业务系统实现监控指标开发。
应用层:
对应用的整体运行状况进行了解、把控,如果将应用当成黑盒子,开发、运维就无从知晓应用当前状态,不能及时发现潜在故障。应用监控不应局限于业务系统,还包括各种中间件、计算引擎,如Spark、Jstorm、redis、zookeeper、kafka等。常用监控数据:JVM堆内存、GC、CPU使用率、线程数、TPS、吞吐量等。一般通过抽象出的统一指标收集组件,收集应用级指标,比如不管是支付系统还是交易系统,都要监控jvm内存使用。
系统层:
实时掌握服务器工作状态,留意性能、内存消耗、容量和整体系统健康状态,保证服务器稳定运行。监控指标:内存、磁盘、CPU、网络流量、系统进程等系统级性能指标
二、架构设计
工欲善其事必先利其器,根据对现有监控产品的调研,以及我们对监控的分层介绍、所需解决的问题,可以发现监控系统从收集到分析的流程架构:采集-存储-展示-告警:
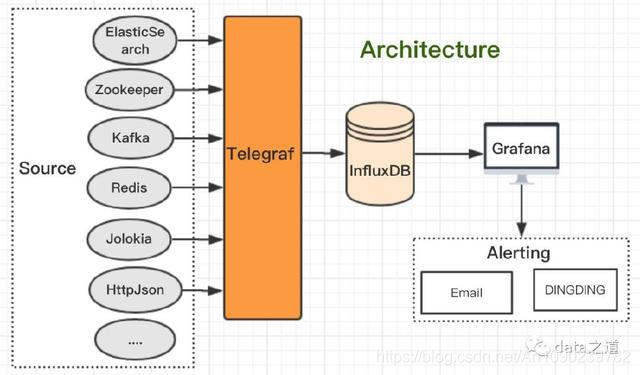
Telegraf:
插件化的指标收集和指标报告服务,能定制化开发并轻松添加所需插件。已经内置了很多常用服务的插件,这也是我们选择telegraf的原因之一,不用再重复造轮子。
Go语言编写的插件化指标收集agent,编译成一个没有外部依赖的二进制文件,安装部署很便捷,直接下载、解压就行,默认配置文件在$TELEGRAF_HOME/etc/telegraf/telegraf.conf目录下。telegraf插件分为两大类:input、output。
input:
收集inputs配置的所有指标,已内置的input插件:elasticsearch、redis、jolokia等。也可直接收集运行agent server的各种指标,比如内存、cpu、磁盘、磁盘IO、进程、swap等。input配置都很简明易用,一般只需配置服务IP地址就可以,如redis指标收集配置:
如果没有内置收集插件,有两种实现方案:
- 开发input插件,但这需要有GO语言基础
- 借助于httpjson input插件,该插件请求http url,返回json格式。url配置为自定义指标收集服务,在指标收集服务内实现指标收集功能,然后指标封装成json返回或指标数据直接在服务内入库。我们监控Kettle Carte、spark、jstorm等用的这种实现思路。
output:
将收集到的度量数据序列化存储,Telegraf指标由四个部分组成:度量、标签、字段、时间戳。支持以下存储结构:InfluxDB、Graphite、JSON,比如度量输出到InfluxDB的配置:
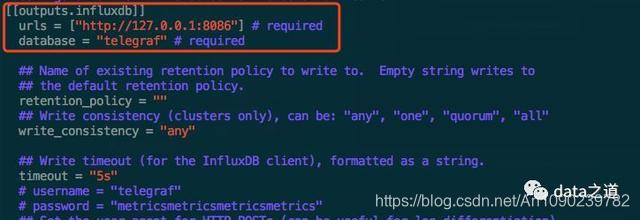
- urls:InfluxDB端口
- database:存储的数据库
- retention_policy:数据保留策略
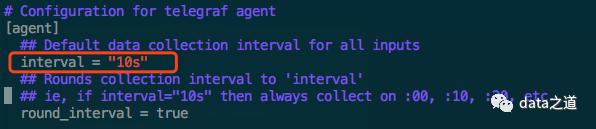
调度频率:
所有指标收集频率是一样的,在配置文件agent项下配置:
服务启动:
–config:配置文件
–config-directory:配置文件目录,如果有多个配置文件时使用
InfluxDB:
高性能的布式时间序列指标数据库。监控指标收集是非常频繁的,否则就失去了实时性,高频收集的结果就是大数据量,也要对时间序列进行分析,InfluxDB就能满足这种应用场景。
InfluxDB是为时间序列构建的高性能数据存储,提供类SQL的查询语言、特定分析时间序列的功能。通过设置数据保留策略,自动从系统中删除过期数据,释放存储空间。社区版只支持单台服务器,会有单点故障风险,商业版版支持高可用,对我们来说,单机InfluxDB已经能满足需求。选择InfluxDB的原因:
- InflluxDB是用GO写的,编译后是一个完全无依赖的二进制文件,安装部署非常便捷,解压缩包即可
- 高性能时间序列专有数据库,对时间序列的存储和查询都做了优化
- 类SQL查询语言,降低使用门槛
- 数据保留策略可以有效的自动清理过期数据
InfluxDB的数据是以shard groups形式存储,指定时间间隔的数据存储到一个shard groups里,这个时间间隔称为shardGroupDuration。
服务启动:
输入influx进入shell命令行:
常用命令:
show databases:查看所有数据库
use db_name:进入数据库
show measurements:显示数据库下所有度量
select *from cpu limit 10:查询一个度量的数据
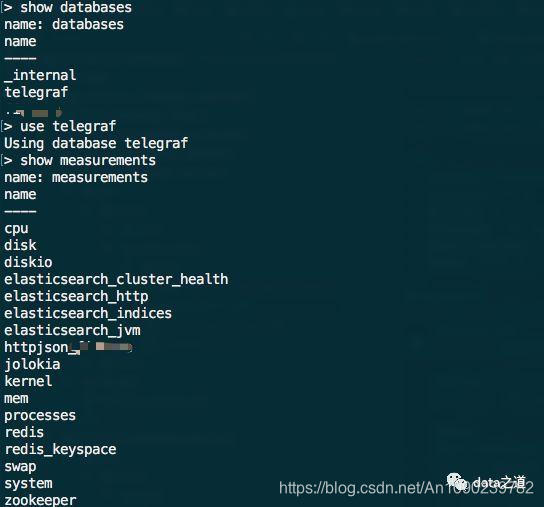
Telegraf默认是将收集的数据持久化到telegraf这个数据库下,每个input对应一个度量表,比如zookeeper的指标数据就在zookeeper这个度量下:
查询数据保留策略:
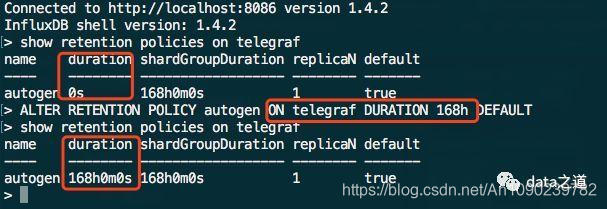
duration:数据保留时间,0表示无限制,InfluxDB默认30分钟检查一次保留策略。ALTER RETENTION语句修改保留7天数据。
replicaN:每个度量在集群里的副本数,副本保证数据高可用性,社区版(单节点)不支持副本数设置。
Grafana:
时间序列分析和监控的开放平台,支持多种数据源(InfluxDB、OpenTSDB时间序列数据库)、丰富的展现形式、支持email/dingding报警。
Grafana是一个指标查询、可视化、监控的开源应用,有着非常漂亮的图表和布局展示,功能齐全的度量仪表盘和图形编辑器,支持Graphite、zabbix、InfluxDB、Prometheus和OpenTSDB作为数据源。
Grafana主要特性:
- 灵活丰富的图形化组件,包括热力图、直方图、地图等
- 在同一dashboard内可以混合多种展示组件
- 开源社区有大量的插件可供选择,包括数据源插件、图形插件、通知插件
- 可以在同一个视图里使用多个不同数据源
简单使用介绍:
- 安装:下载&解压二进制包
- 配置:配置文件:/conf配置端口号、Email、登录用户
- start:命令:/opt/grafana/bin/grafana-server start
- 访问:http://ip:port