知道IEEE这个世界最大电子电气学术组织禁止华为资助和中国某些一流大学教授参与审稿这个消息我是愤怒的。我也是无奈的,学校考核必须发论文到这儿,不得不发。IEEE上面的论文中国人几乎占了三成(美国人搞学术的很少的基本是做金融法律医生这种行业)。中国在校的就要三千多万大学生,一旦国家宣布IEEE期刊不参与学术考核,都不投IEEE这是何其壮观。从这个贸易战看:强权即是真理,没有所谓的自由贸易和平等。中国之大已容不下一个安静的键盘。不过是又一次鸦片战争。除了愤怒还是愤怒,除了一心图强外还是一心图强。中华文明三四千年的历史都是世界顶级,美国人区区100多年第一就想再占100年这不是无知么?中国人有13亿人,是美国人的4倍还要多,4个抵1个也是必然会超过美国。
2019年5月29日 IEEE宣布禁止任何受华为资助的教授或学生参与IEEE审稿。听到这个消息我是愤怒的,说好的科学无国界呢?
梳理下这个过程:
2018.12.1,华为CFO(任正非之女)被美国下令逮捕
2018.12.1 对芯片重大贡献的华人张首晟在美国身亡,就在2年前获得中国国家科学技术奖(中国科技最高奖,最高领导人亲自颁奖,奖金200万美金)
2019年5月 美国撕毁两国元首已经基本确定的协议,对中国征收25%关税。
2019年5月中旬 美国禁止全世界任何企业与华为接触或者提供设备,也禁止购买华为手机或通讯设备。理由:“国家安全”(距离美国棱镜门用思科通讯设备和Google监听全世界这个事件不过几年美国人就忘了自己干了什么事。)同时禁止欧洲其他国家使用华为提供的5G服务。
2019年5月中下旬,Microsoft,ARM,Google纷纷宣布停止和华为任何商业来往,同时Google禁止华为手机使用Google服务。
2019年5月底, IEEE(世界上最大电子电气学术机构)禁止任何受华为资助的教授参与审稿。禁止其他高校或企业与中国的一些高校合作。
PCA用来可以降维。降低数据维度既可以减少计算量,也可以降低噪声。最后本文使用了Python对PCA进行实现。
1. 直观理解PCA主成分分析是什么?
Principal Component Analysis(PCA)主成分分析它本质是把数据视作一个椭球。二维的话就是一个椭圆。我们知道椭球它有长轴和短轴。如果3维的椭球某个短轴非常短,那么我们是不是可以把这个短轴视作没有?这样一个椭球就降维成了一个2维的椭圆。这就是PCA的原理。为了方便计算。首先需要对数据进行归一化,让椭圆的圆心在原点**。那么我们怎么知道哪个短轴非常短呢?看这个轴方向数据的方差。方差越小轴越短。也就是说方差越大证明这个维度的数据越重要即是主成分。**方差越小这个维度越不重要(对应椭圆轴越短),那么这个维度可以舍弃。方差最大的那个数据投影到第一个坐标(也叫做第一主成分),第二大投影到第二个维度的坐标,以此类推。看下面这张图,粉红色那条线就是第一主成分。可以看到当坐标轴转到与粉红色重合时,各点在第一坐标轴上投影点分布式最分散的(方差越大波动越大)。注意:第二主成分必须要和第一主成分垂直(第二主成分是原先的点在第二坐标轴上投影后的点),而且它要占用下一个最大方差。当然下面这个图是二维的,将它降维当然只有一维。所以只有第一主成分,没有其他主成分。
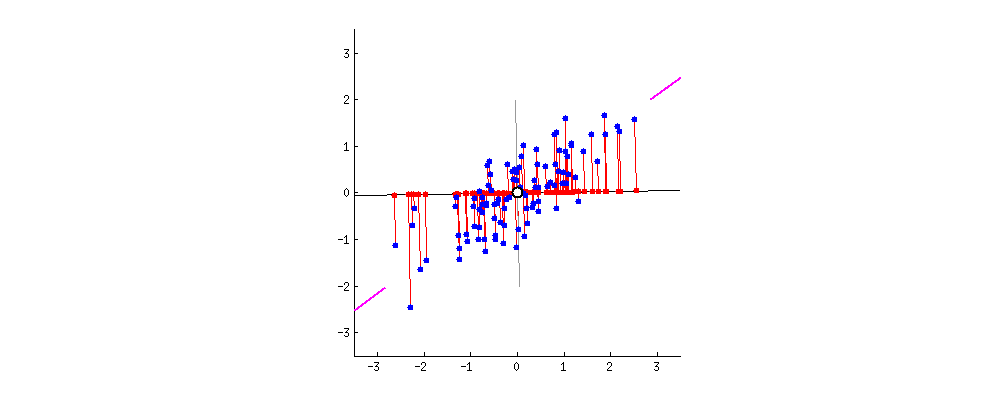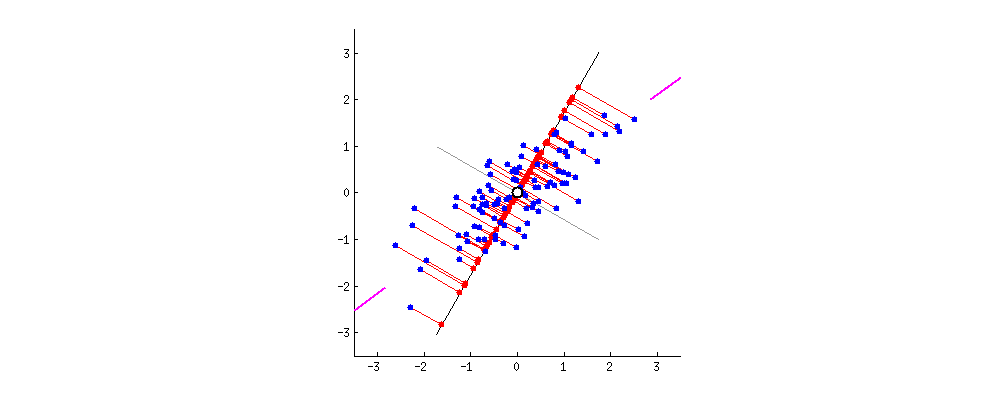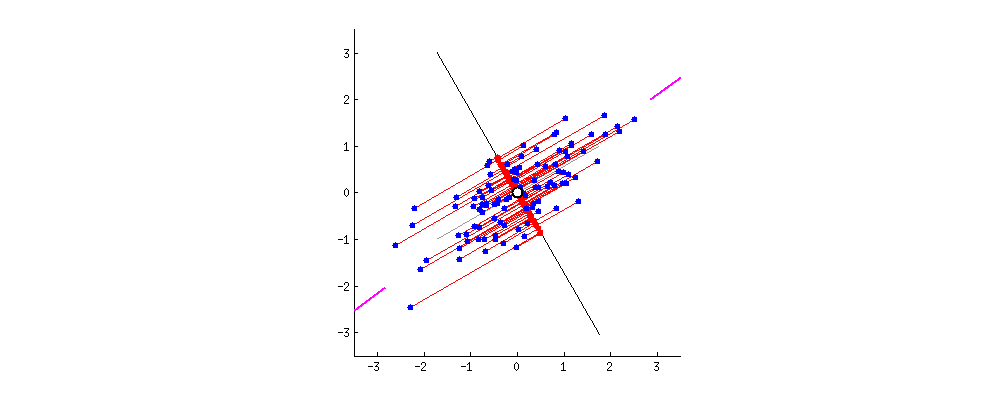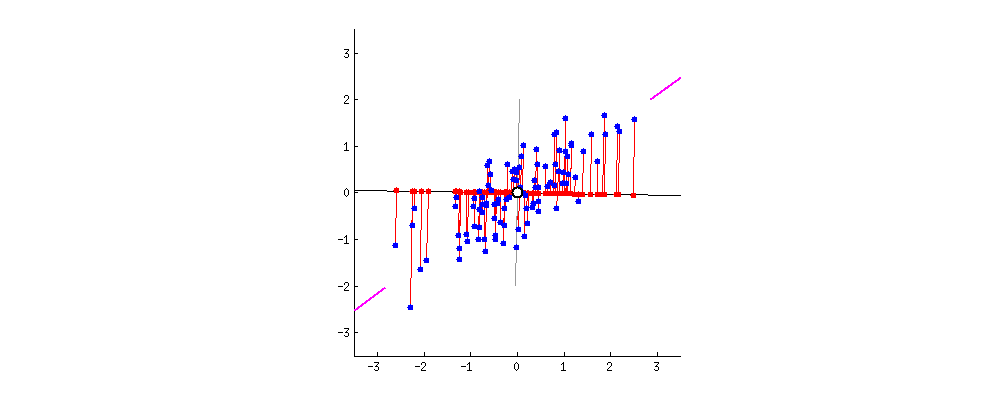
2. 逐步理解PCA的执行过程
2.1 归一化(让椭圆圆心移动到原点)

2.2 计算协方差矩阵
如果是一维的话协方差就是方差(不是矩阵)。多维的话就是协方差矩阵了。如果是一维的话协方差就是方差。协方差就是用来分析两个维度之间的相关性。协方差大于0则两个维度正相关,小于0则是负相关。等于0则是不相干。下面是三维的情况下协方差矩阵。注意Cov(a,b)= Cov(b,a),所以下面这个协方差矩阵是一个对称矩阵。大致理解方差是协方差矩阵在一维情况下的特殊情况就可以了。然后可以看后面的了。


2.3 计算协方差矩阵的特征值,将特征值从高到低排序,然后每个特征值对应一个特征向量。第k个特征向量与原先数据内积就是对应的第k个主成分
假如原数据一共有10维,如果我想降到4维。那么就取前4大的特征值对应的特征向量。这4个特征向量每个特征向量都是10维的。然后用这个4个特征向量与原先数据点内积,得到4个数。所有的原数据点都这样计算后就得到了第一第二第三第四主成分。这样就把10维降低到4维。(当然前面这个过程一般是用矩阵批量运算)
那么怎么计算我保留了多少信息,扔掉了多少信息?答:“计算保留的那4个特征值,占10个总特征值的比例即是保留了百分之几的信息”
3. Python编程实践,2维降到1维
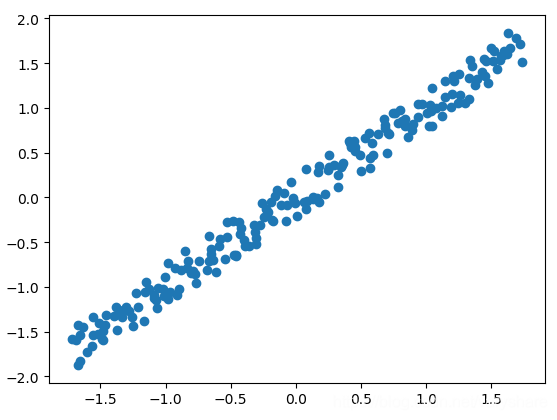
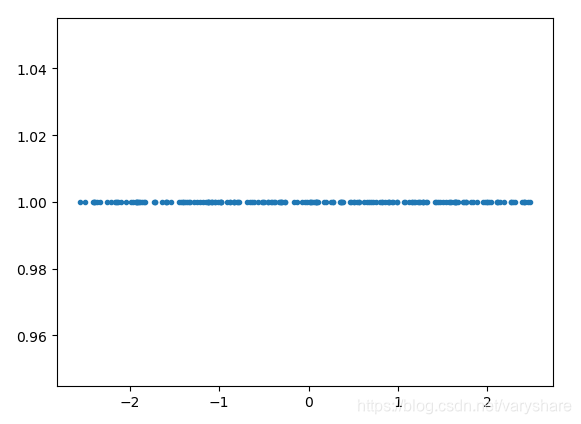
代码如下所示:
# -*- coding: utf-8 -*-
"""
Created on Wed May 29 20:50:26 2019
@author: @Ai酱
"""
import numpy as np
import matplotlib.pyplot as plt
x = np.linspace(0,10,200) + np.random.rand(200)/5
y = 0.233 * x + np.random.rand(200)/3
# 归一化
x = (x - np.mean(x))/np.std(x)
y = (y - np.mean(y))/np.std(y)
#plt.scatter(x,y)
# 1. 计算协方差矩阵
cov_mat = np.cov(x,y)
# 2. 计算协方差矩阵的特征值
eigenvalues,eigenvectors = np.linalg.eig(cov_mat)
k = 1 # 降维后的目标维度
# 对特征值进行排序,取前k个
topk = np.argsort(eigenvalues)[0:k]
# 前k个最大的特征值对应的特征向量与原矩阵相乘
data = np.stack((x,y),axis=-1)
result = np.matmul(data,eigenvectors[topk].T)
plt.plot(result[:,0],result[:,0].shape[0]*[1],'.')#绘制一维图
欢迎关注知乎专栏:《适合初学者的神经网络机器学习理论与实践》
参考文献:
[1] A step by step explanation of Principal Component Analysis