收藏从未停止
学习从未开始。现在的知识内容平台太多了,csdn、博客园、思否、知乎等等等等。在搜集信息的时候,经常会在各个平台上进行收藏,可是收藏之后也不怎么看了。最近这段时间,我想把自己收藏的一些文章整理一下,好的留,不好的删,初步想法是把这些文章都留下来,存到别的地方,就不再从收藏夹里找了。那第一步就是把收藏的文章链接导出来。
终于又用到了长时间不用的python了,python这个东西还是很高效且适合新手使用的。
开始
最开始的时候,我的想法是通过收藏的页面,一页一页爬取,然后再用正则把标题和链接爬取出来,后来发现,在个人主页-收藏里面有本账户的所有收藏。所以我直接抓取收藏的响应报文,报文是json内容,直接用json模块来处理。

编写
这个练习分为两部分,第一部分是将收藏文章的标题和链接输出出来;第二部分是对url进行请求,删除不存在的文章。(这是我在写完第一部分发现的,有些文章已经不存在了,服务器响应404)
第一部分
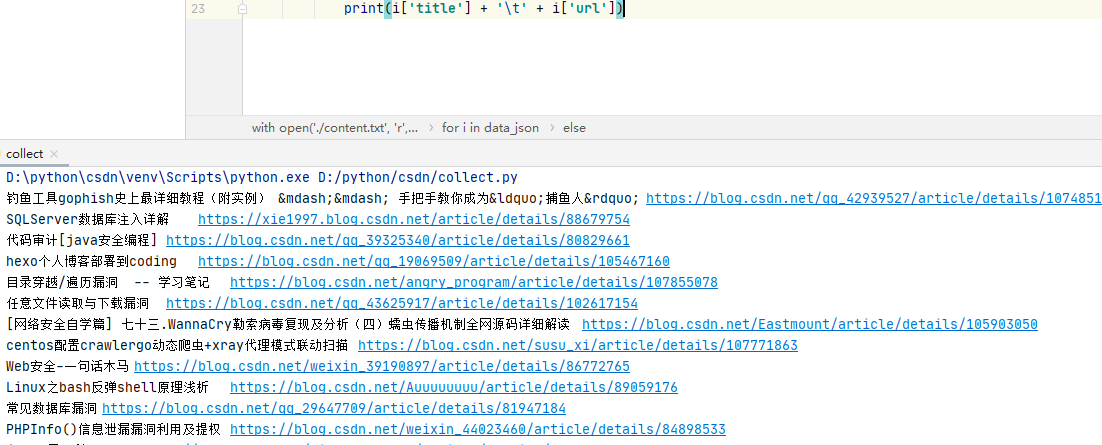
我直接将响应报文里的内容保存到一个txt文本当中,然后对文本的内容进行处理。
import json
from urllib.parse import unquote
with open('./content.txt', 'r', encoding='utf-8') as f:
content = f.read()
data = json.loads(content)
data_json = data['data']['list']
for i in data_json:
#部分文章标题汉字被url编码了,如果文章的标题中包含%,就进行url解码,比较暴力
if '%' in i['title']:
print(unquote(i['title'], 'utf-8') + ' ' + i['url'])
#在响应报文中,发现存在一个标题中间包含
和多个空格的情况,全部替换为空
elif '
' in i['title']:
print((i['title'].replace(' ', '')).replace('
', '') + ' ' + i['url'])
else:
print(i['title'] + ' ' + i['url'])
结果:
第二部分
我的想法是将第一部分的标题和url的链接存储为字典,键名为标题,键值为链接,通过第一部分生成字典,并写成函数形式,返回值为字典。
这里主要写字典的处理。对字典的处理想法是这样的,将不能访问的文章和能访问的文章分别输出出来。使用requests模块,请求链接,响应404的就删除。
但是我发现并没有那么简单,发现所有响应均为404,我想到的原因是,请求时,请求头与请求频率。

后来设置请求头后,已经正常,应该是请求头的原因。
还有一个问题,就是删除响应为404的问题,我最开始是在字典遍历的同时,对链接进行请求,响应为不是200的使用del()进行删除,发现一直报错,网上搜索答案后得知,字典遍历的时候是不允许进行删除操作的,遂根据网上提供的方式,使用字典的方式进行删除。

参考链接:https://blog.csdn.net/u013344884/article/details/81867225
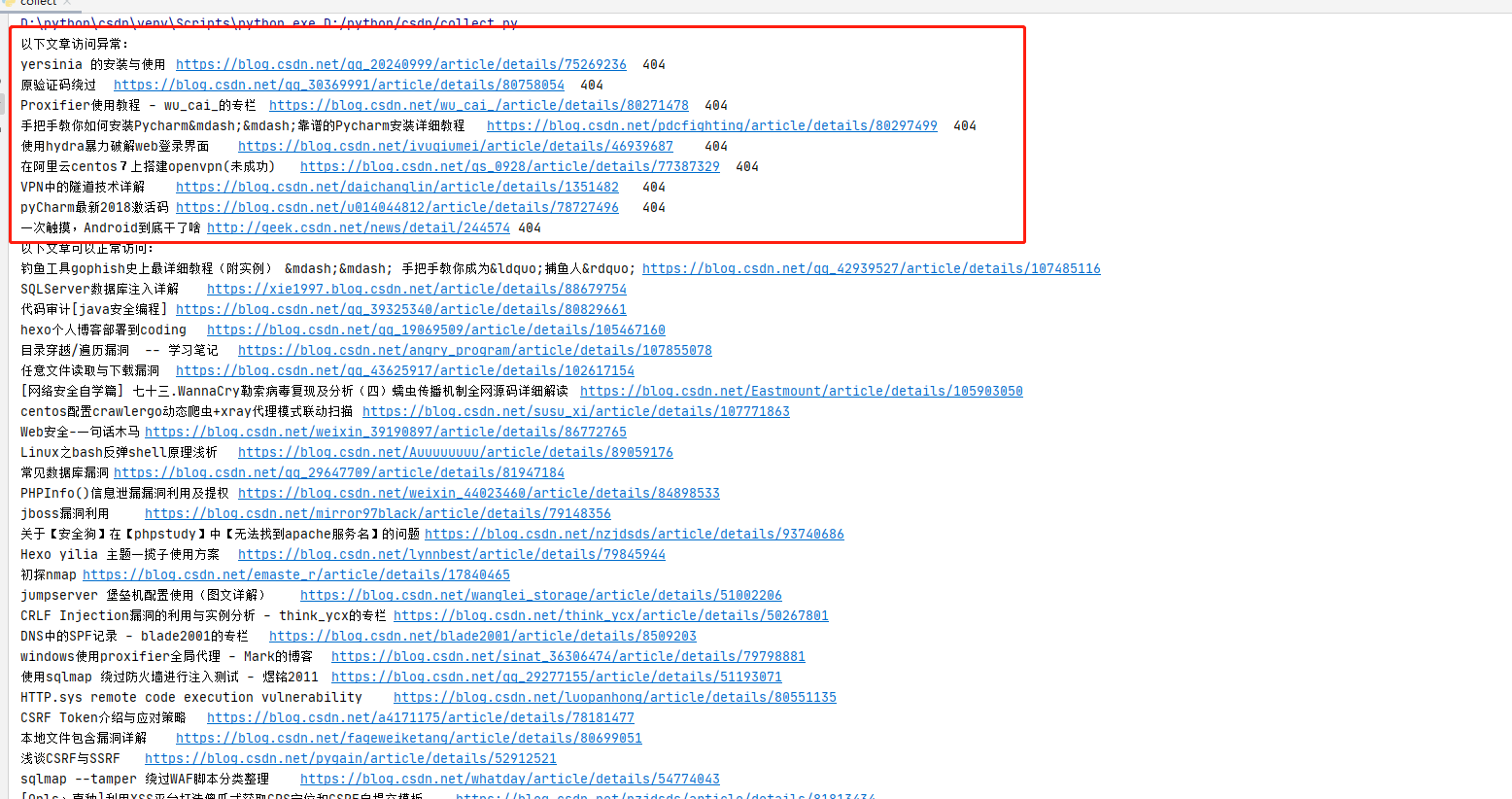
结果:
第二部分源码:
def test_url(title_url):
print('以下文章访问异常:')
for k in list(title_url.keys()):
#增加请求头后,响应正常
url_code = requests.get(title_url[k], headers=headers)
if url_code.status_code != 200:
print(k + ' ' + title_url[k] + ' ' + str(url_code.status_code))
del title_url[k]
continue
print('以下文章可以正常访问:')
for k,v in title_url.items():
print(k + ' ' + v)
GitHub:https://github.com/Ezioz/python_tools/blob/master/csdn/csdn_collect/csdn_collect.py
总结
好长时间不写代码,生疏了很多,尤其是本来基础就比较薄弱。还不错,发现并解决了不少问题,熟能生巧。