一、概念
xml(Extensible Markup Language)可扩展标记语言,标准通用标记语言的子集,是一种用于标记电子文件使其具有结构性的标记语言。
在电子计算机中,标记指计算机所能理解的信息符号,通过此种标记,计算机之间可以处理包含各种的信息比如文章等。它可以用来标记数据、定义数据类型,是一种允许用户对自己的标记语言进行定义的源语言。 它非常适合万维网传输,提供统一的方法来描述和交换独立于应用程序或供应商的结构化数据。是Internet环境中跨平台的、依赖于内容的技术,也是当今处理分布式结构信息的有效工具。早在1998年,W3C就发布了XML1.0规范,使用它来简化Internet的文档信息传输。
二、作用
主要用来传输和存储数据。
三、解析XML文件的方法
DOM解析是先读取在解析,SAX边读取边解析(用来解析比较大的xml文件)。
3.1DOM
3.2DOM4J(解析需要导入dom4j的jar包)
3.2.1
<?xml version="1.0" encoding="GBK"?> <students> <student> <name>吴飞</name> <college>java学院</college> <telephone>62354666</telephone> <notes>男,1982年生,硕士,现就读于北京邮电大学</notes> </student> <student> <name>李雪</name> <college>C++学院</college> <telephone>62358888</telephone> <notes>男,1987年生,硕士,现就读于中国农业大学</notes> </student> <student> <name>Jack</name> <college>PHP学院</college> <telephone>66666666</telephone> <notes>我是澳洲人</notes> </student> <student> <name>Lucy</name> <college>Android学院</college> <telephone>88888888</telephone> <notes>我是美国人</notes> </student> </students>
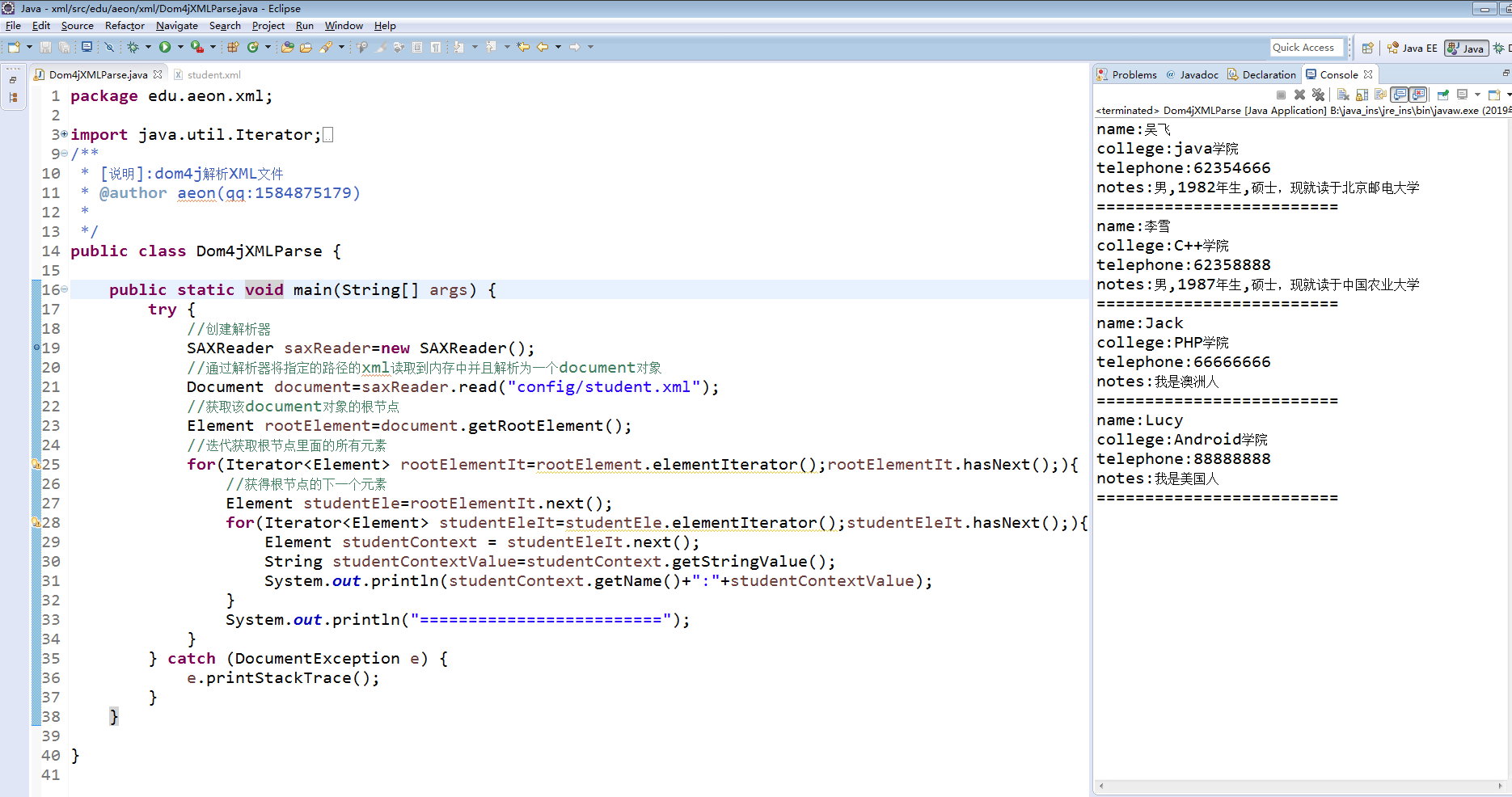
package edu.aeon.xml; import java.util.Iterator; import org.dom4j.Document; import org.dom4j.DocumentException; import org.dom4j.Element; import org.dom4j.io.SAXReader; /** * [说明]:dom4j解析XML文件 * @author aeon(qq:1584875179) * */ public class Dom4jXMLParse { public static void main(String[] args) { try { //创建解析器 SAXReader saxReader=new SAXReader(); //通过解析器将指定的路径的xml读取到内存中并且解析为一个document对象 Document document=saxReader.read("config/student.xml"); //获取该document对象的根节点 Element rootElement=document.getRootElement(); //迭代获取根节点里面的所有元素 for(Iterator<Element> rootElementIt=rootElement.elementIterator();rootElementIt.hasNext();){ //获得根节点的下一个元素 Element studentEle=rootElementIt.next(); for(Iterator<Element> studentEleIt=studentEle.elementIterator();studentEleIt.hasNext();){ Element studentContext = studentEleIt.next(); String studentContextValue=studentContext.getStringValue(); System.out.println(studentContext.getName()+":"+studentContextValue); } System.out.println("========================="); } } catch (DocumentException e) { e.printStackTrace(); } } }
结果:
3.2.2DOM4J+Xpath(解析)
<?xml version="1.0" encoding="utf-8"?> <config> <database-info> <driver-name>com.mysql.jdbc.Driver</driver-name> <url>jdbc:mysql://192.168.1.151:3306/db_test</url> <user>root</user> <password>123</password> </database-info> </config>
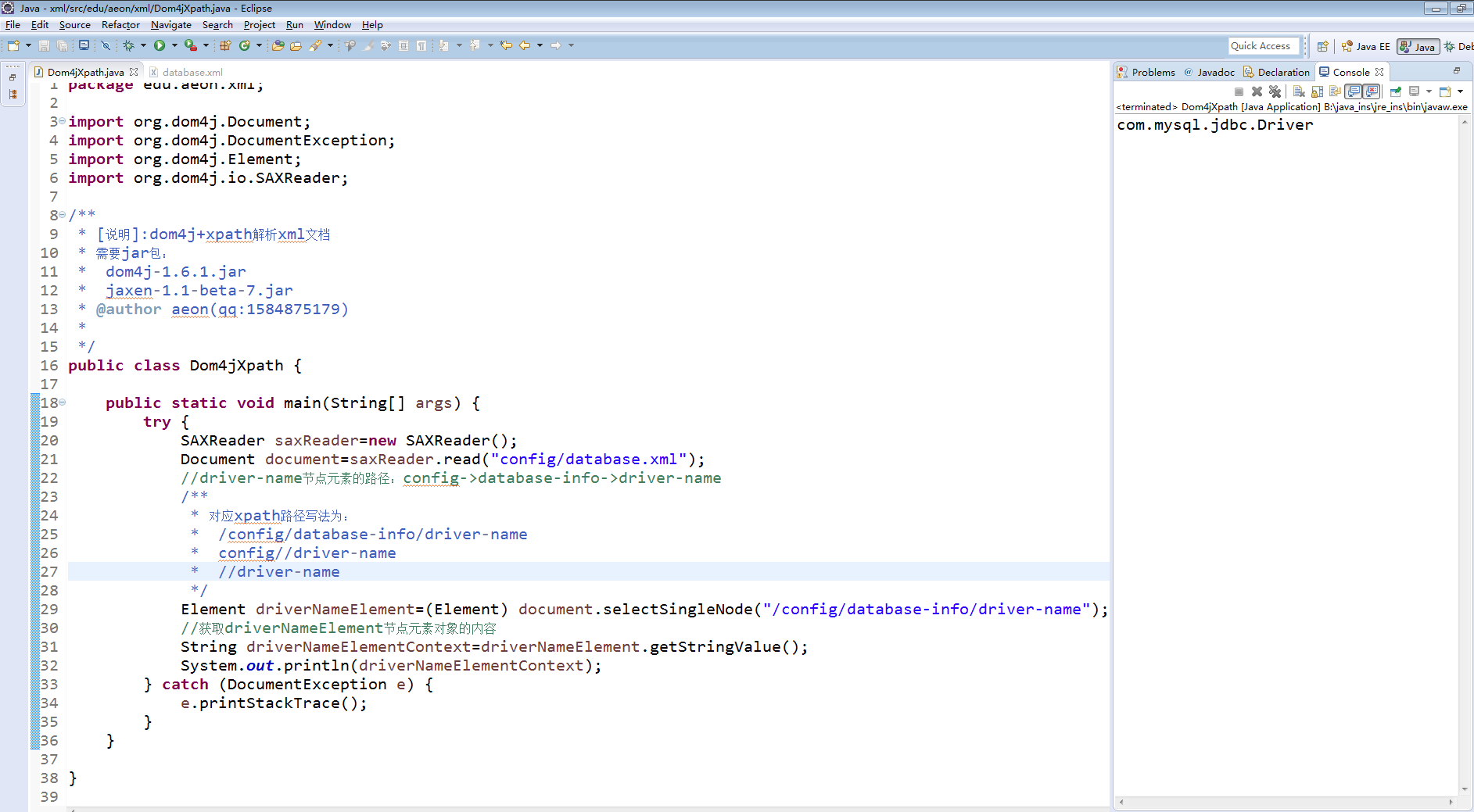
package edu.aeon.xml; import org.dom4j.Document; import org.dom4j.DocumentException; import org.dom4j.Element; import org.dom4j.io.SAXReader; /** * [说明]:dom4j+xpath解析xml文档 * 需要jar包: * dom4j-1.6.1.jar * jaxen-1.1-beta-7.jar * @author aeon(qq:1584875179) * */ public class Dom4jXpath { public static void main(String[] args) { try { SAXReader saxReader=new SAXReader(); Document document=saxReader.read("config/database.xml"); //driver-name节点元素的路径:config->database-info->driver-name /** * 对应xpath路径写法为: * /config/database-info/driver-name * config//driver-name * //driver-name */ Element driverNameElement=(Element) document.selectSingleNode("/config/database-info/driver-name");//选上面三种里面的任何一种xpath路径即可 //获取driverNameElement节点元素对象的内容 String driverNameElementContext=driverNameElement.getStringValue(); System.out.println(driverNameElementContext); } catch (DocumentException e) { e.printStackTrace(); } } }
结果截图:
3.2.3dom4j+xpath解析(带属性)
<?xml version="1.0" encoding="utf-8"?> <server> <service> <connector port ="8080"></connector> </service> </server>
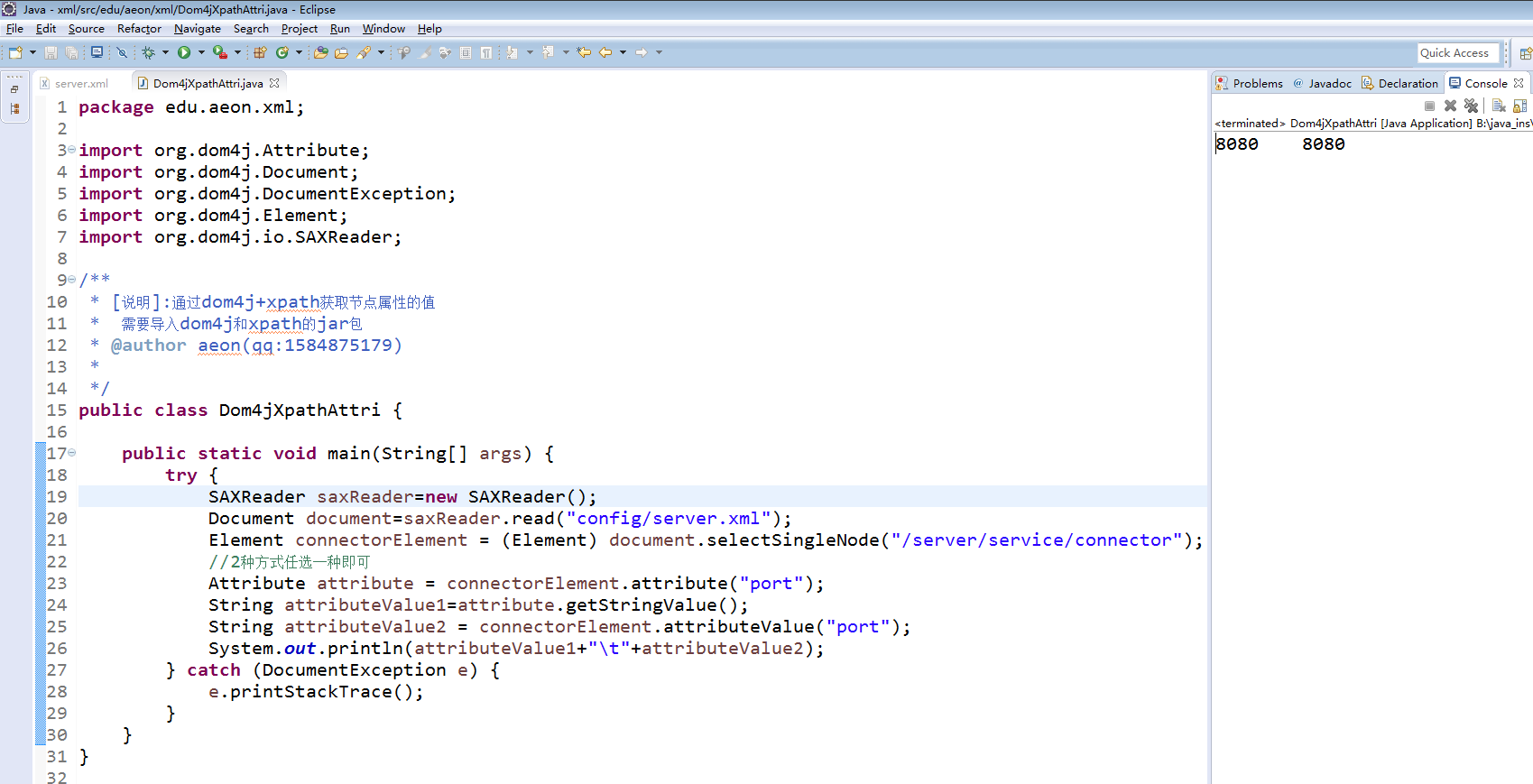
package edu.aeon.xml; import org.dom4j.Attribute; import org.dom4j.Document; import org.dom4j.DocumentException; import org.dom4j.Element; import org.dom4j.io.SAXReader; /** * [说明]:通过dom4j+xpath获取节点属性的值 * 需要导入dom4j和xpath的jar包 * @author aeon(qq:1584875179) * */ public class Dom4jXpathAttri { public static void main(String[] args) { try { SAXReader saxReader=new SAXReader(); Document document=saxReader.read("config/server.xml"); Element connectorElement = (Element) document.selectSingleNode("/server/service/connector"); //2种方式任选一种即可 Attribute attribute = connectorElement.attribute("port"); String attributeValue1=attribute.getStringValue(); String attributeValue2 = connectorElement.attributeValue("port"); System.out.println(attributeValue1+" "+attributeValue2); } catch (DocumentException e) { e.printStackTrace(); } } }
结果截图:
3.3SAX解析(事件驱动解析、边读边解析)
优点:无需将整个xml文档加载到内存中,所以内存消耗少,适合解析特别大的xml文件
package edu.aeon.xml; import javax.xml.parsers.SAXParser; import javax.xml.parsers.SAXParserFactory; import org.xml.sax.Attributes; import org.xml.sax.SAXException; import org.xml.sax.helpers.DefaultHandler; /** * [说明]:通过sax解析xml文档 * @author aeon(qq:1584875179) * */ public class SAXParserTest { public static void main(String[] args) { try { //创建解析工厂 SAXParserFactory saxParserFactory=SAXParserFactory.newInstance(); //通过解析工厂获得解析器 SAXParser saxParser=saxParserFactory.newSAXParser(); //通过自定义的解析格式解析执行xml文档 saxParser.parse("config/student.xml", new myDefaultHandler()); } catch (Exception e) { e.printStackTrace(); } } } class myDefaultHandler extends DefaultHandler{ @Override public void startElement(String uri, String localName, String qName, Attributes attributes) throws SAXException { System.out.print("<"+qName+">"); } @Override public void characters(char[] ch, int start, int length) throws SAXException { System.out.print(new String(ch, start, length)); } @Override public void endElement(String uri, String localName, String qName) throws SAXException { System.out.print("</"+qName+">"); } }
结果截图:

