基本架构
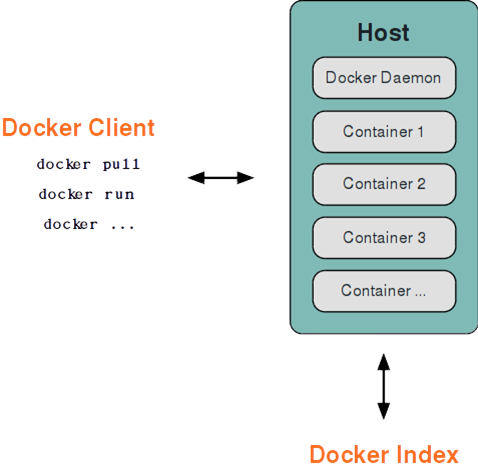
Docker 采用了 C/S架构,包括客户端和服务端。 Docker daemon 作为服务端接受来自客户的请求,并处理这些请求(创建、运行、分发容器)。 客户端和服务端既可以运行在一个机器上,也可通过 socket 或者 RESTful API 来进行通信
Docker daemon 一般在宿主主机后台运行,等待接收来自客户端的消息。 Docker 客户端则为用户提供一系列可执行命令,用户用这些命令实现跟 Docker daemon 交互
名字空间
名字空间是 Linux 内核一个强大的特性。每个容器都有自己单独的名字空间,运行在其中的应用都像是在独立的操作系统中运行一样。名字空间保证了容器之间彼此互不影响。
pid 名字空间
不同用户的进程就是通过 pid 名字空间隔离开的,且不同名字空间中可以有相同 pid。所有的 LXC 进程在 Docker 中的父进程为Docker进程,每个 LXC 进程具有不同的名字空间。同时由于允许嵌套,因此可以很方便的实现嵌套的 Docker 容器。
net 名字空间
有了 pid 名字空间, 每个名字空间中的 pid 能够相互隔离,但是网络端口还是共享 host 的端口。网络隔离是通过 net 名字空间实现的, 每个 net 名字空间有独立的 网络设备, IP 地址, 路由表, /proc/net 目录。这样每个容器的网络就能隔离开来。Docker 默认采用 veth 的方式,将容器中的虚拟网卡同 host 上的一 个Docker 网桥 docker0 连接在一起。
ipc 名字空间
容器中进程交互还是采用了 Linux 常见的进程间交互方法(interprocess communication - IPC), 包括信号量、消息队列和共享内存等。然而同 VM 不同的是,容器的进程间交互实际上还是 host 上具有相同 pid 名字空间中的进程间交互,因此需要在 IPC 资源申请时加入名字空间信息,每个 IPC 资源有一个唯一的 32 位 id。
mnt 名字空间
类似 chroot,将一个进程放到一个特定的目录执行。mnt 名字空间允许不同名字空间的进程看到的文件结构不同,这样每个名字空间 中的进程所看到的文件目录就被隔离开了。同 chroot 不同,每个名字空间中的容器在 /proc/mounts 的信息只包含所在名字空间的 mount point。
uts 名字空间
UTS("UNIX Time-sharing System") 名字空间允许每个容器拥有独立的 hostname 和 domain name, 使其在网络上可以被视作一个独立的节点而非 主机上的一个进程。
user 名字空间
每个容器可以有不同的用户和组 id, 也就是说可以在容器内用容器内部的用户执行程序而非主机上的用户
控制组
控制组(cgroups)是 Linux 内核的一个特性,主要用来对共享资源进行隔离、限制、审计等。只有能控制分配到容器的资源,才能避免当多个容器同时运行时的对系统资源的竞争。
控制组技术最早是由 Google 的程序员 2006 年起提出,Linux 内核自 2.6.24 开始支持。
控制组可以提供对容器的内存、CPU、磁盘 IO 等资源的限制和审计管理
联合文件系统
联合文件系统(UnionFS)是一种分层、轻量级并且高性能的文件系统,它支持对文件系统的修改作为一次提交来一层层的叠加,同时可以将不同目录挂载到同一个虚拟文件系统下(unite several directories into a single virtual filesystem)。
联合文件系统是 Docker 镜像的基础。镜像可以通过分层来进行继承,基于基础镜像(没有父镜像),可以制作各种具体的应用镜像。
另外,不同 Docker 容器就可以共享一些基础的文件系统层,同时再加上自己独有的改动层,大大提高了存储的效率。
Docker 中使用的 AUFS(AnotherUnionFS)就是一种联合文件系统。 AUFS 支持为每一个成员目录(类似 Git 的分支)设定只读(readonly)、读写(readwrite)和写出(whiteout-able)权限, 同时 AUFS 里有一个类似分层的概念, 对只读权限的分支可以逻辑上进行增量地修改(不影响只读部分的)。
Docker 目前支持的联合文件系统种类包括 AUFS, btrfs, vfs 和 DeviceMapper
容器格式
最初,Docker 采用了 LXC 中的容器格式。自 1.20 版本开始,Docker 也开始支持新的 libcontainer 格式,并作为默认选项
Docker 网络实现
首先,要实现网络通信,机器需要至少一个网络接口(物理接口或虚拟接口)来收发数据包;此外,如果不同子网之间要进行通信,需要路由机制。
Docker 中的网络接口默认都是虚拟的接口。虚拟接口的优势之一是转发效率较高。 Linux 通过在内核中进行数据复制来实现虚拟接口之间的数据转发,发送接口的发送缓存中的数据包被直接复制到接收接口的接收缓存中。对于本地系统和容器内系统看来就像是一个正常的以太网卡,只是它不需要真正同外部网络设备通信,速度要快很多。
Docker 容器网络就利用了这项技术。它在本地主机和容器内分别创建一个虚拟接口,并让它们彼此连通(这样的一对接口叫做 veth pair)
Docker 创建一个容器的时候,会执行如下操作:
- 创建一对虚拟接口,分别放到本地主机和新容器中;
- 本地主机一端桥接到默认的 docker0 或指定网桥上,并具有一个唯一的名字,如 veth65f9;
- 容器一端放到新容器中,并修改名字作为 eth0,这个接口只在容器的名字空间可见;
- 从网桥可用地址段中获取一个空闲地址分配给容器的 eth0,并配置默认路由到桥接网卡 veth65f9。
完成这些之后,容器就可以使用 eth0 虚拟网卡来连接其他容器和其他网络。
可以在 docker run 的时候通过 --net 参数来指定容器的网络配置,有4个可选值:
--net=bridge这个是默认值,连接到默认的网桥。--net=host告诉 Docker 不要将容器网络放到隔离的名字空间中,即不要容器化容器内的网络。此时容器使用本地主机的网络,它拥有完全的本地主机接口访问权限。容器进程可以跟主机其它 root 进程一样可以打开低范围的端口,可以访问本地网络服务比如 D-bus,还可以让容器做一些影响整个主机系统的事情,比如重启主机。因此使用这个选项的时候要非常小心。如果进一步的使用--privileged=true,容器会被允许直接配置主机的网络堆栈。--net=container:NAME_or_ID让 Docker 将新建容器的进程放到一个已存在容器的网络栈中,新容器进程有自己的文件系统、进程列表和资源限制,但会和已存在的容器共享 IP 地址和端口等网络资源,两者进程可以直接通过lo环回接口通信。--net=none让 Docker 将新容器放到隔离的网络栈中,但是不进行网络配置。之后,用户可以自己进行配置