我们使用的百度搜索和电商网站的搜索功能一般都是基于Lucene实现的,Solr就是对Lucene进行的封装,就像Servlet和Struts2,SpringMvc一样
说的专业点就是全文检索
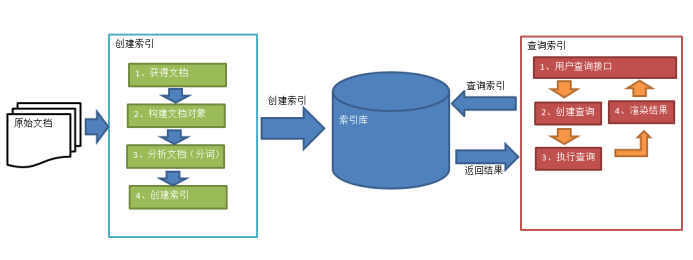
实现全文检索的流程的大致操作如下
这张图表现的很清晰,网上扒下来的
索引库中应该包含两部分,一部分是索引,一部分是文档,索引包含对应文档的id,通过该id可以查找到文档
来看看我的第一个Lucene入门程序
先整理步骤
/* * * 创建索引 * 查询索引 * 1,创建indexwriter对象, * 指定索引库存放位置Directory对象 * 指定一个分析器,对文档内容进行分析 * 2,创建document对象 * 3,创建field对象,将field添加到document对象中 * 4,使用indexwriter对象把document对象写入索引库, * 此过程进行索引创建,并将document对象和索引都写入索引库 * 5,关闭indexwriter对象 */ public class FirstLucene { //创建索引和查询索引要使用同一份分析器(分词器) @Test public void createIndex() throws Exception { //指定索引库存放位置Directory对象 Directory directory = FSDirectory.open(new File("D://lucene//index")); Analyzer analyzer = new IKAnalyzer();//中文分词器 IndexWriterConfig config = new IndexWriterConfig(Version.LUCENE_4_10_3, analyzer);//指定分析器 IndexWriter indexWriter = new IndexWriter(directory, config);//创建IndexWriter File f = new File("D://lucene//searchsource");//源文件的的路径,对这些文件进行分析,添加索引 File[] listFiles = f.listFiles(); for (File file : listFiles) { Document document = new Document(); //文件名 String name = file.getName(); //TextField存储字符串或流 分析Yes 索引Yes 保存Yes Field fileNameField = new TextField("fielName", name, Store.YES); //文件大小 long file_size = FileUtils.sizeOf(file); //LongField存储long型 分析Yes 索引Yes 保存Yes or No Field fileSizeField = new LongField("fileSize",file_size,Store.YES); //StringField存储字符串 分析 N 索引Y 保存Yes or No //文件路径 String file_path = file.getPath(); //StoreFieldc可以存储多种类型 分析No 索引No 保存Yes Field filePathField = new StoredField("filePath", file_path); //文件内容 String file_content = FileUtils.readFileToString(file); Field fileContentField = new TextField("file_content", file_content, Store.YES); //把域添加到文档中 document.add(fileNameField); document.add(fileSizeField); document.add(filePathField); document.add(fileContentField); //使用indexwriter对象添加文档 ,此过程进行索引创建,并将document对象和索引都写入索引库 indexWriter.addDocument(document); } indexWriter.close(); } }
看到这里相信你也已经或创建索引了,加油
public class FirstLucene { //创建索引和查询索引要使用同一份分析器(分词器) @Test public void createIndex() throws Exception { Directory directory = FSDirectory.open(new File("D://lucene//index"));//指定索引库存放位置Directory对象 Analyzer analyzer = new IKAnalyzer();//官方推荐使用这个实现类 IndexWriterConfig config = new IndexWriterConfig(Version.LUCENE_4_10_3, analyzer);//指定分析器 IndexWriter indexWriter = new IndexWriter(directory, config);//创建IndexWriter File f = new File("D://lucene//searchsource");//源文件的的路径 File[] listFiles = f.listFiles(); for (File file : listFiles) { Document document = new Document(); //文件名 String name = file.getName(); //TextField存储字符串或流 分析Yes 索引Yes 保存Yes Field fileNameField = new TextField("fielName", name, Store.YES); //文件大小 long file_size = FileUtils.sizeOf(file); //LongField存储long型 分析Yes 索引Yes 保存Yes or No Field fileSizeField = new LongField("fileSize",file_size,Store.YES); //StringField存储字符串 分析 N 索引Y 保存Yes or No //文件路径 String file_path = file.getPath(); //StoreFieldc可以存储多种类型 分析No 索引No 保存Yes Field filePathField = new StoredField("filePath", file_path); //文件内容 String file_content = FileUtils.readFileToString(file); Field fileContentField = new TextField("file_content", file_content, Store.YES); //把域添加到文档中 document.add(fileNameField); document.add(fileSizeField); document.add(filePathField); document.add(fileContentField); //使用indexwriter对象添加文档 ,此过程进行索引创建,并将document对象和索引都写入索引库 indexWriter.addDocument(document); } indexWriter.close(); } }