在之前将HDFS时,讲过一个数据节点dataNode的概念还NameNode的概念,mycat使用的与其相似,在mycat中,dataNode就是数据库,而mycat就充当的是NameNode的节点。是一个中间件。
mycat的两大核心:
1.分库分表(解决单表数据量过大的问题)
2.独写分离(解决单个数据库访问量大,压力大的问题)
什么是分库分表?
将一个数据量大的表数据分放在不同的数据节点上,这种模式就称为分库分表。
在分库分表中,所有的数据节点都是平等的,没有主从关系。
mycat实现分库分表:
需求:使用两个mysql服务器,通过mycat添加数据,实现一条数据在mysql01,一条数据在mysql02上
使用规则:mod-long
mycat是使用java编写的,因此需要先配置jdk环境,在安装mycat
1.官网下载mycatxxx.tar.gz
2.xftp上传到linux中的apps目录中
3.解压压缩包
tar -zxvf Mycatxxx.tar.gz
4.配置环境变量(与配置jdk环境变量相同)
vim /etc/profile #编辑mycat环境变量 export MYCAT_HOME=/home/apps/mycat export PATH=$PATH:$MYCAT_HOME/bin
至此,mycat安装完成。但是要使用mycat的分库分表还需要配置几个文件:
进入mycat目录下的conf目录:
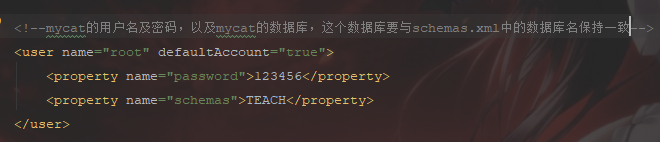
1.修改server.xml文件:
2.修改schemas.xml文件:
<?xml version="1.0"?> <!DOCTYPE mycat:schema SYSTEM "schema.dtd"> <mycat:schema xmlns:mycat="http://io.mycat/"> <!-- schema:相当于mysql中的数据库 name:这个数据库的名字 checkSQLschema:检查sql语句是否错误,默认为false,不需要为true,交给mysql来检查就可以了 sqlMaxLimit:最大执行sql语句数量,可以一次性执行的sql语句数量 --> <schema name="TEACH" checkSQLschema="false" sqlMaxLimit="100"> <!-- 相当于数据库中的表,这个表并不是真实存在的,而是通过mysql映射过来的,因此mysql中一定要存在与这个表的名字相同的表,这样才能映射进来 dataNode:数据节点,上一篇分析HDFS时,已经讲过数据节点的概念,就是mysql数据库,节点之间以,分隔 rule:规则,使用mycat实现分库分表有十大规则,也就是说怎样实现分片,是把每天的数据都分一个片,还是按照编号范围,每100条数据分一块... 等等,具体十大分片规则,可以单独去看,这里使用mod-long,轮询的方式,第一条存mysql1,第2条存mysql2 --> <table name="student" dataNode="dn1,dn2" rule="mod-long" /> </schema> <!--数据节点:就是数据库服务器节点 name:节点的名字,与上面相对应,上面有几个,下面就要有几个 dataHost:数据节点地址,与下面的dataHost标签的名字向对应 database:真实的数据库名, mycat中的TEACH数据库是虚拟的,它里面的表都是通过真实的数据库中的表映射进来的,这里指的是mysql中的真实的数据库 --> <dataNode name="dn1" dataHost="localhost1" database="teach" /> <dataNode name="dn2" dataHost="localhost2" database="teach" /> <!--dataHost:真实的数据库的节点地址信息 name:给该节点起名字,通过dataNode引用该节点 maxCon:最大连接数 minCon:嘴小连接数 balance:负载均衡(在独写分离中讲解,这里用不到) writeType:写入方式(读写分离的配置,这里用不到,下一篇讲) dbType:数据库类型,是mysql还是oracle,redis...等等,本来mycat是只支持mysql的,但是发展到现在支持多种数据库 dbDriver:数据库驱动(使用本地驱动->mycat提供的驱动) switchType:切换方式,读写分离中讲 slaveThreshold:主从复制延时(读写分离的属性,下篇讲)--> <dataHost name="localhost1" maxCon="1000" minCon="10" balance="0" writeType="0" dbType="mysql" dbDriver="native" switchType="1" slaveThreshold="100"> <!--heartbeat:心跳,mycat一直检测mysql的user表(心跳),当接收不到心跳时,就会认为这台mysql宕机了,就不会在对该节点做增删改查等操作--> <heartbeat>select user()</heartbeat> <!--writeHost:写节点,当独立存在时,则该节点又读又写,当与readHost同时存在时,则表示只写,不进行读操作 host属性只是标识了该台数据库的操作的内容,可以随意定义,不能重复 --> <writeHost host="write1" url="192.168.226.159:3306" user="root" password="123456"/> </dataHost> <dataHost name="localhost2" maxCon="1000" minCon="10" balance="0" writeType="0" dbType="mysql" dbDriver="native" switchType="1" slaveThreshold="100"> <heartbeat>select user()</heartbeat> <writeHost host="write2" url="192.168.226.160:3306" user="root" password="123456"/> </dataHost> </mycat:schema>
3修改rule.xml

因为本次只使用了mod-long规则,其他的没有使用,这里count表示数据库的dataNode节点总数
配置完毕,启动mycat,因为配置了环境变量,可以在任意地方执行命令:
mycat console
然后使用mysql连接mycat,此时如果真实的mysql数据中没有数据库及表时,无法映射,因此mycat中的表会显示不存在,需要在真实的mysql数据库上创建表,然后通过mycat添加数据,可以看到一条数据存入mysql1,一条数据存入mysql2的情形。