不同时期的你去看红楼梦会有不一样的感触,而不同年份的我看ML也会有更深入的理解(*/ω\*)
svm是 一种判别方法 有监督的学习模型 通常用来进行模式识别、分类以及回归分析,主要解决二分类问题。其原理也从线性可分说起,然后扩展到线性不可分的情况。甚至扩展到使用非线性函数中去。
所以,我们先从最简单的线性支持向量机说起。
去年翻ML时,仍不解svm为什么叫支持向量机。或许 同时翻翻线性回归和线性支持向量机就能豁然开朗。
如果一个线性函数能够将样本分开,称这些数据样本是线性可分的。那么什么是线性函数呢?其实很简单,在二维空间中就 是一条直线,在三维空间中就是一个平面,以此类推,如果不考虑空间维数,这样的线性函数统称为超平面。
我们看一个简单的二维空间的例子。
样本是线性可分的,但是很显然不只有这一条直线可以将样本分开,而是有无数条。
线性回归,通常采用最小二乘法作为损失函数,即实际值与观测值相减的平方和最小作为其选取直线的标准。
线性支持向量机,就对应着能将数据正确划分并且间隔最大的直线。
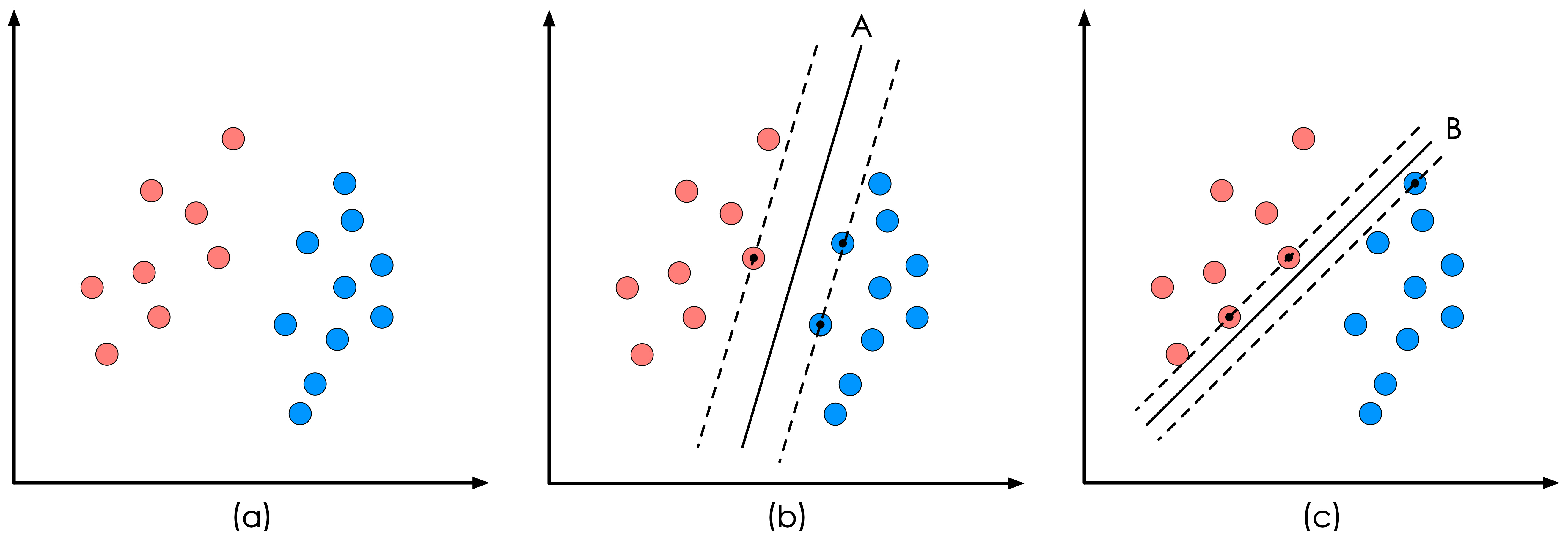
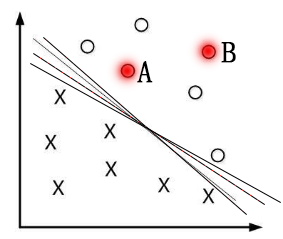
为什么要间隔最大呢?
一般来说,一个点距离分离超平面的远近可以表示分类预测的确信度,如图中的A B两个样本点,B点被预测为正类的确信度要大于A点,所以SVM的目标是寻找一个超平面,使得离超平面较近的异类点之间能有更大的间隔,即 不必考虑所有样本点,只需让求得的超平面使得离它近的点(“支持向量”)间隔最大(svm名称的由来)。 故而SVM自带结构风险最小化,LR(Linear Regress线性回归)则是经验风险最小化。
那么怎么计算间隔?
我们将SVM的推导分为以下几个步骤:
1. 用数学定义要求解的问题
2. 将原始问题转换为二次凸函数+约束条件的优化问题
3. 拉格朗日优化+对偶特性构建方程
4. SMO求解alpha最优值
svm的数学定义
首先,二维空间中,线性直线方程形式很简单 y=ax+b 。现将 X 轴视为 X1 轴, Y 轴视为 X2 轴,则方程的形式为 X2 = aX1 + b ,经移位后为 aX1 + (-1)X2 +b = 0 ,可以写成向量的形式:
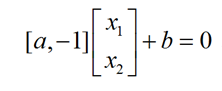
我们可以写出一个更一般的向量表达形式:
![]()
其中,ω 为法向量,代表了超平面的方向, γ 为位移量,代表了超平面与原点的距离。
现给出点到直线距离最简单的公式:
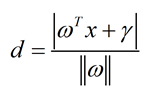
假设超平面能将所有样本点都正确地分类,即对所有训练样本 xi 满足下列公式:
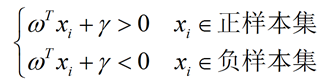
而此时为了计算方便,需要将式子设置为大于等+1,和小于等于-1。
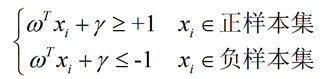
原则上可以是任意常数,但无论是多少,都可以通过对 ω 的变换使其为 +1 和 -1 :
支持向量到决策面的距离为d,则公式可写成:
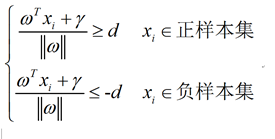 不等式两边除以d,可得:
不等式两边除以d,可得:
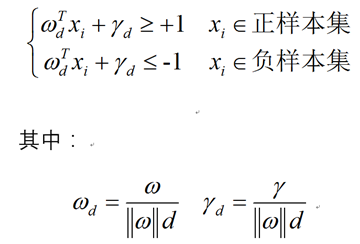
我们可以把参数 ωd和γd重新起个名字,就叫它们ω和γ。
现在我们扯回来,如何使间隔最大:
由上式得出
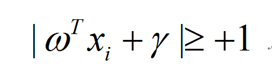
则 支持向量机最大间隔用数学定义如下:
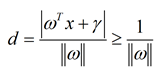
并 将原始问题转换为二次凸函数+约束条件的优化问题:
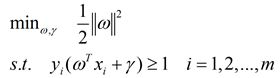
那么现在如何求解呢?
我们引入拉格朗日乘数法这一概念。
什么是拉格朗日乘数法
设给定二元函数z=ƒ(x,y)和附加条件φ(x,y)=0,为寻找z=ƒ(x,y)在附加条件下的极值点,先做拉格朗日函数 ![]() ,其中λ为参数。
,其中λ为参数。
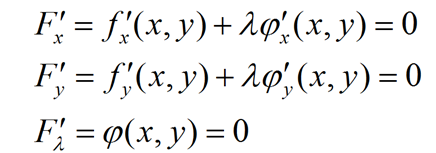
由上述方程组解出 x , y 及 λ, 如此求得的 (x,y) ,就是函数 z=ƒ(x,y) 在附加条件 φ(x,y)=0 下的可能极值点。
用拉格朗日乘数法求解
现将目标问题用拉格朗日表示:
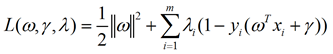
分别对各参数求偏导:
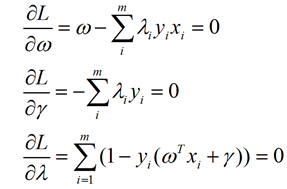
代回拉格朗日函数可得:
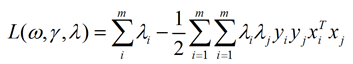
拉格朗日对偶问题
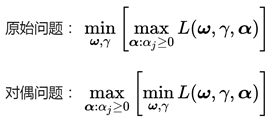
可以将SVM的优化问题![]() 转变为:
转变为:
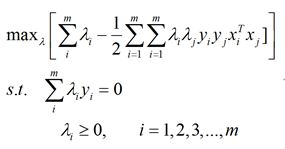
松弛变量
SVM另一个巧妙之处是加入了一个松弛变量来处理样本数据可能存在的噪声问题,如下图所示:
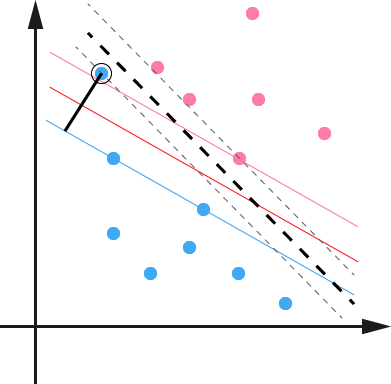
SVM允许数据点在一定程度上对超平面有所偏离,这个偏移量就是SVM算法中可以设置的outlier值,对应于上图中黑色实现的 长度。松弛变量的加入使得SVM并非仅仅是追求局部效果最优,而是从样本数据分布的全局出发,统筹考量,正所谓成大事者 不拘小节。