这里讲的排列问题都可以用DFS的方式来进行搜索,似乎这种类型的题就是为DFS而生的,下面就是解题思路:
(1)定义状态:即如何描述问题求解过程中每一步的状况。为了精简程序,增加可读性,我们一般将参与子结点扩展运算的变量组合成当前状态列入值参,以便回溯时能恢复递归前的状态;
(2)边界条件:即在什么情况下程序不再递归下去。如果是求满足某个特定条件的一条最佳路径,则当前状态到达边界时并非一定意味着此时就是最佳目标状态。因此还须增加判别最优目标状态的条件;
(3)搜索范围:状态生成扩展时需要枚举的变量范围。就是如何设定for 语句中循环变量的初值和终值。
(4) 约束条件和最优性要求:当前扩展出一个子结点后应满足什么条件方可继续递归下去;如果是求满足某个特定条件的一条最佳路径,那么在扩展出某个子状态后是否继续递归搜索下去,不仅取决于子状态是否满足约束条件,而且还取决于子状态是否满足最优性要求。
(5)参与递归运算的参数:将参与递归运算的参数设为递归子程序的值参或局部变量。若这些参数的存储量大(例如数组)且初始值需由主程序传入,为避免内存溢出,则必须将其设为全局变量,且回溯前需恢复其递归前的值。
总结起来就是深度优先搜索解决问题的步骤为:确定问题的解空间--> 确定结点的扩展搜索规则--> 以DFS 方式搜索解空间,并在搜索过程中用剪枝函数避免无效搜索。
基于深度优先遍历,很容易写出一个深度优先搜索算法的框架,代码如下:
void dfs(int cur) //cur 表示当前状态
{
if(到达目标状态) //统计、输出结果等;
else
{
for(int i = 下界; i <= 上界; i++) // 枚举i 所有可能的路径
{
if(满足边界和约束条件)
{
……
设置标记
dfs(cur+1);
取消标记
}
状态树
3
}
}
}
先看几道题:
1.无重复数字的全排列
输入n(<=11),按从小到大输出数字1 到n 个的全部排列。
样例:
输入:
3
输出:
1:1 2 3
2:1 3 2
3:2 1 3
4:2 3 1
5:3 1 2
6:3 2 1
这种是最普通的全排列了,用STL函数或者手写递归的方法都可以,将所有元素之间连一条边,问题即转换为不重复的遍历所有点即可,
下面给出手写的方法:
#include<iostream> using namespace std; int n,p[12],b[12],ct=0; void print() { ct++; cout<<ct<<":"; for(int i=1; i<=n; i++) cout<<p[i]<<" "; cout<<endl; } void dfs(int i) { if(i==n+1) { print(); return; } for(int j=1; j<=n; j++) if(b[j]==0) { p[i]=j; b[j]=1; dfs(i+1); b[j]=0; } } int main() { cin>>n; dfs(1); return 0; }
再来看一道题:
3.有重复元素的全排列
输入n(<=10)个小些字母(可能重复),按从小到大输出输出n 个字符的全部排列。
样例:
输入:
abaab
输出:
1:aaabb
2:aabab
3:aabba
4:abaab
5:ababa
6:abbaa
7:baaab
8:baaba
9:babaa
10:bbaaa
这里的问题在于两点:
1.将从1到n的数改成了手动输入字符;
2.有重复的元素不用管,按照正常的字母顺序排列(这个与无重复的有异曲同工之妙)。
由于字母有重复,如果我们按上述方法建图,会发现分别从1、3、4 结点出发,进行深度优先遍历查找所有路径时,会得到一样的遍历结果,当然从2、5 结点出发也存在同样的问题。
所以应该从一类点出发,而不应该从某一个点出发。
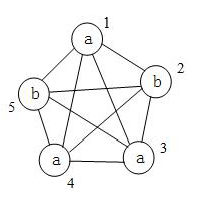
下面给出标程:
#include<iostream> #include<string> using namespace std; int n,b[12],ct=0,ar[200]; char p[12]; string s; void print() { ct++; cout<<ct<<":"; for(int i=1; i<=n; i++) cout<<p[i]; cout<<endl; } void dfs(int i) //搜索第i 个位置 { if(i==n+1) print(); for(int j=97; j<=122; j++) if(ar[j]>0) { p[i]=j; ar[j]--; dfs(i+1); ar[j]++; } } int main() { cin>>s; n=s.size(); for(int i=0; i<n; i++) ar[s[i]]++; //ar 数组记录字符s[i]的个数 dfs(1); return 0; }