GitHub地址:https://github.com/Yasin-cxh/personal-project
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 20 | 30 |
| · Estimate | · 估计这个任务需要多少时间 | 30 | 120 |
| Development | 开发 | ||
| · Analysis | · 需求分析 (包括学习新技术) | 400 | 540 |
| · Design Spec | · 生成设计文档 | 20 | 30 |
| · Design Review | · 设计复审 | 20 | 0 |
| · Coding Standard | · 代码规范 (为目前的开发制定合适的规范) | 120 | 140 |
| · Design | · 具体设计 | 30 | 20 |
| · Coding | · 具体编码 | 240 | 360 |
| · Code Review | · 代码复审 | 60 | 70 |
| · Test | · 测试(自我测试,修改代码,提交修改) | 60 | 40 |
| Reporting | 报告 | ||
| · Test Repor | · 测试报告 | 20 | 40 |
| · Size Measurement | · 计算工作量 20 | 20 | |
| · Postmortem & Process Improvement Plan | · 事后总结, 并提出过程改进计划 | 70 | 60 |
| 合计 | 1130 | 1500 |
需求分析
- 实现一个名为WordCount的命令行程序
- 输入文件名以命令行参数传入,并统计以下几个指标:
- 统计文件的字符数:
- 只需要统计Ascii码,汉字不需考虑
- 空格,水平制表符,换行符,均算字符
- 统计文件的单词总数,单词:至少以4个英文字母开头,跟上字母数字符号,单词以分隔符分割,不区分大小写。
- 英文字母: A-Z,a-z
- 字母数字符号:A-Z, a-z,0-9
- 分割符:空格,非字母数字符号
例:file123是一个单词, 123file不是一个单词。file,File和FILE是同一个单词
- 统计文件的有效行数:任何包含非空白字符的行,都需要统计。
- 统计文件中各单词的出现次数,最终只输出频率最高的10个。频率相同的单词,优先输出字典序靠前的单词。
按照字典序输出到文件result.txt:例如,windows95,windows98和windows2000同时出现时,则先输出windows2000- 输出的单词统一为小写格式
- 输出的格式为
characters: number
words: number
lines: number
<word1>: number
<word2>: number
文件流程图
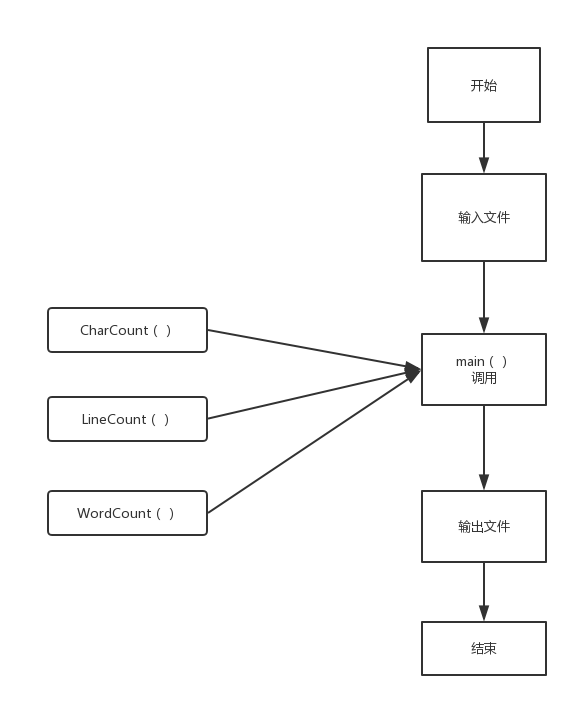
思路分析
-
int CharCount(char* argv)
字符统计函数,读入文件,每次读入一个字符并计数,文件读入完后,输出字符数。 -
int LineCount(char* argv)
行数统计函数,读入文件,每次读入一行并计数,直到文件末尾,输出行数。 -
int WordCount(char *argv)
统计单词数并输出词频前十的单词。用unordered_map<string, int>记录单词以及其出现的频数,最后用vector将unordered_map<string, int>按频数降序排列,最后输出词频前十的单词。
代码如下:
int WordCount(char *argv)
{
//读入文档
fstream file2;
string strfile, stmp;
file2.open(argv);
int numWordCount = 0;
while (getline(file2, strfile))
{
strfile.append(stmp);
stmp.clear();
//去除间隔符,单词统计
for (int i = 0; i < strfile.length(); i++)
{
//小写处理
strfile[i] = tolower(strfile[i]);
if (ispunct(strfile[i]))
{
strfile[i] = ' ';
numWordCount++;
}
}
//统计字符频率
stringstream ss(strfile);
string strTmp;
while (ss >> strTmp)
{
unordered_map<string, int>::iterator it = strMap.find(strTmp);
if (it == strMap.end())//strMap中如果不存在当前单词则插入一个新键值对,出现频率为1
{
strMap.insert(unordered_map<string, int>::value_type(strTmp, 1));
}
else //如果存在则出现频率加1
strMap[strTmp]++;
}
//CountWordFrequency(ss);
}
//单词数等于分隔符+1
if (numWordCount > 0)
numWordCount++;
file2.close();
return numWordCount;
}
**函数输出部分**
//Output(strMap);
ofstream OutputFile("result.txt");
if (OutputFile.is_open())
{
unordered_map<string, int>::const_iterator it;
OutputFile << "characters: " << numCharCount << endl;
OutputFile << "words: " << numWordCount << endl;
OutputFile << "lines: " << numLineCount << endl;
//排序
vector<pair<string, int>>vtMap;
for (auto it = strMap.begin(); it != strMap.end(); it++)
vtMap.push_back(make_pair(it->first, it->second));
sort(vtMap.begin(), vtMap.end(),
[](const pair<string, int> &x, const pair<string, int> &y) -> int {
return y.second < x.second; });
int count = 1;
for (auto it = vtMap.begin(); it != vtMap.end(); it++)
{
if (count > 10)
break;
OutputFile << it->first << ':' << it->second << endl;
count++;
}
//cout << count << endl;
}
性能分析
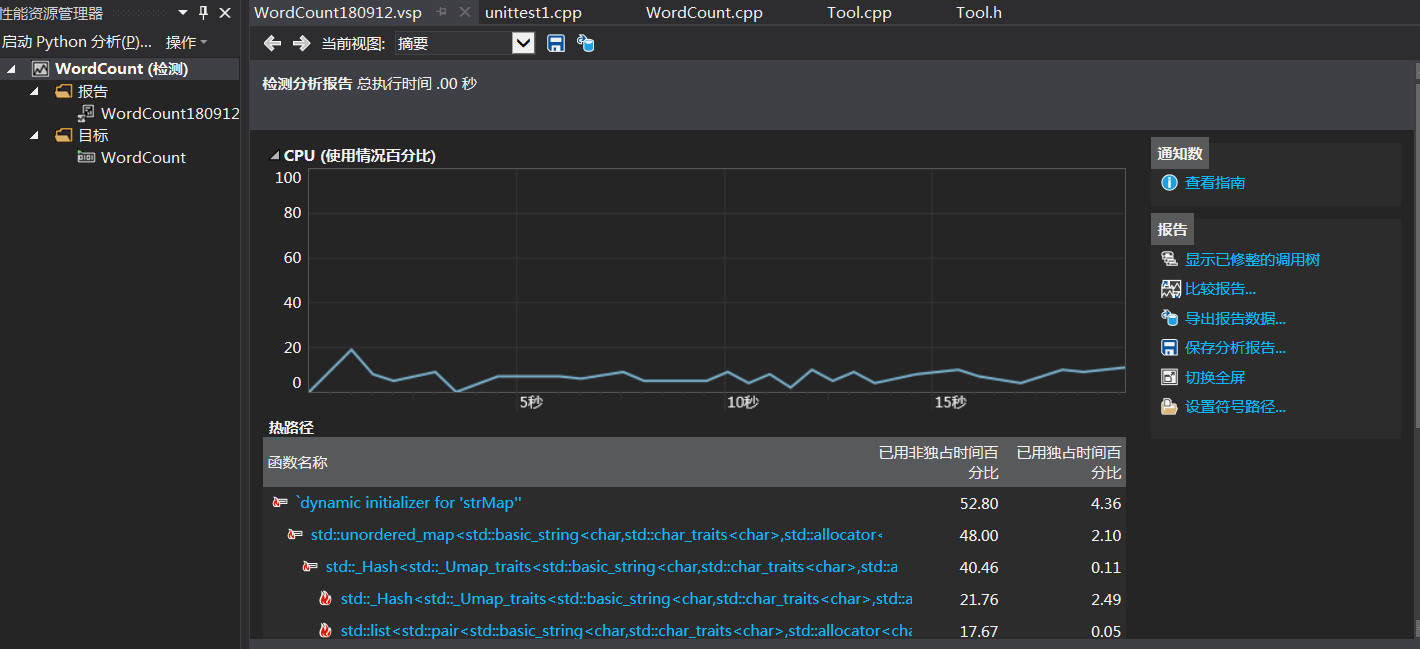
单元测试
单元测试一直完成不了,IDE老是报异常,百度了也不知道为什么,只好手动测试。
这是测试前写的简单测试用例:
namespace UnitTest1
{
TEST_CLASS(UnitTest1)
{
public:
TEST_METHOD(TestMethod1)
{
char file[] = "D:\1.txt";
int num = Tool::CharCount(file);
Assert::IsTrue(num == 1);// TODO: 在此输入测试代码
}
};
}
namespace UnitTest2
{
TEST_CLASS(UnitTest1)
{
public:
TEST_METHOD(TestMethod1)
{
char file[] = "D:\1.txt";
int num = Tool::LineCount(file);
Assert::IsTrue(num == 1);// TODO: 在此输入测试代码
}
};
}
-
测试没有字符
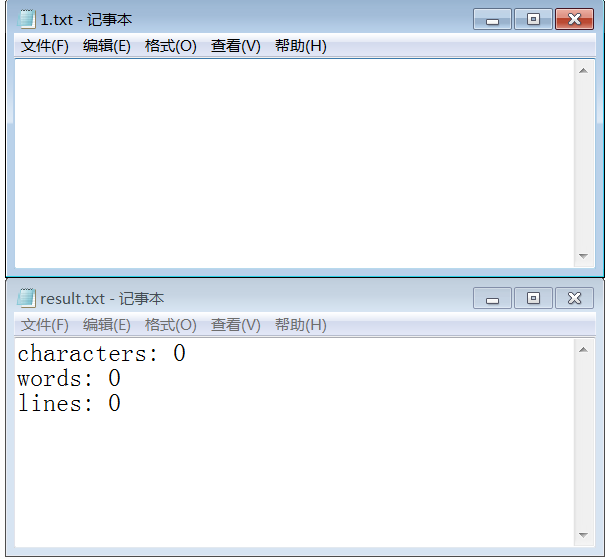
-
测试统计Hamlet
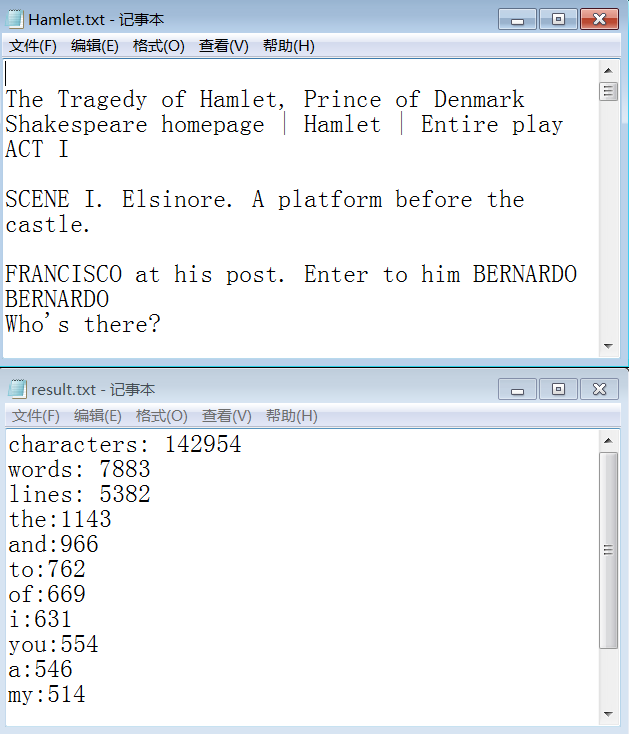
异常处理
if(argv == NULL)
{
cout << "error: you do not put a file " << endl;
}
if (argc > 2)
{
cout << "error: you put too many files" << endl;
}
心得体会
从看到这次作业使用C++或Java来写之后我就觉得凉了,Java 0基础,C++基础差而且忘的差不多了。还是头铁的选择用C++来写。分析完题目,脑中充满了疑惑。这概念是什么?不懂,那概念是什么?也不懂。在这次个人项目中,相比于敲代码,我花了更多的时间去查找资料。这一周的时间让我学会了不少新知识。Learn by doing的概念确实很有效果,但对于基础太差的人来说,有时候会陷入learn的死循环。刚开学这段时间白天工作比较忙,只好深夜激情学习。但有时候花了两三个小时就为了解决一个基本步骤,真让人感叹当初没有好好学习。熬了几个晚上之后,基础功能算是完成了吧。不过遗憾的是单元测试一直不能用,请教了舍友,他们也无能为力,不知道是我操作有问题还是IDE有问题,很疑惑。接口封装只是把一部分函数封装在了.h头文件中,没有全部实现函数接口封装。暑假看《构建之法》,知道对一个软件项目不仅仅是写代码这么简单,等到亲身实践才懂得代码之外的事还有很多,甚至比代码本身更重要,这一点在这次作业中深有体会。养成在分析问题中记录问题的习惯,按照这些问题估计时间,需要查找哪些资料等。有时间把C++基础知识再看看。